Introduction to Genomics and Galaxy
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
Do genes on opposite strands ever overlap? If so, how often?
Learn some of the basic concepts of genomics and bioinformatics
Familiarize yourself with the basics of Galaxy
Time estimation: 2 hours 30 minutesLevel: Introductory IntroductorySupporting Materials:Published: Oct 18, 2017Last modification: May 17, 2026License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00191rating Rating: 5.0 (2 recent ratings, 92 all time)version Revision: 43
This practical aims to familiarize you with the Galaxy user interface. It will teach you how to perform basic tasks such as importing data, running tools, working with histories, creating workflows, and sharing your work.
comment Audience
This tutorial is for those who are new to Galaxy, genomics, and bioinformatics. If you aren’t new to bioinformatics you can just do the items listed in the Hands-On boxes (hands_on), or you can try one of the other introductory tutorials.
This tutorial teaches the same basic content as Galaxy 101, but requires less knowledge of biology to understand the questions this tutorial addresses.
AgendaIn this tutorial, we will:
Introduction
Comment: RequirementsTo run this practical you will need
- An internet-connected computer. Galaxy can run on your laptop without an internet connection, but this practical requires access to resources on the web.
- A web browser. Firefox and Google Chrome work well, as does Safari. Internet Explorer is known to have issues with Galaxy so avoid using that.
- Access to a Galaxy instance. Galaxy is available in many ways. If you are doing this practical as part of a workshop, the instructor will tell you which instance to use. If you are doing this on your own, you can use usegalaxy.org.
Question: Our Motivating QuestionI wonder if genes on opposite strands ever overlap with each other, and if so, how common is that?
To explore this question we need a basic understanding of genomes, chromosomes, strands, and genes.
Comment: Definitions 1
Genome
The genome is the collection of all DNA native to an organism. For humans, the genome is all of a person’s chromosomes.
Chromosome
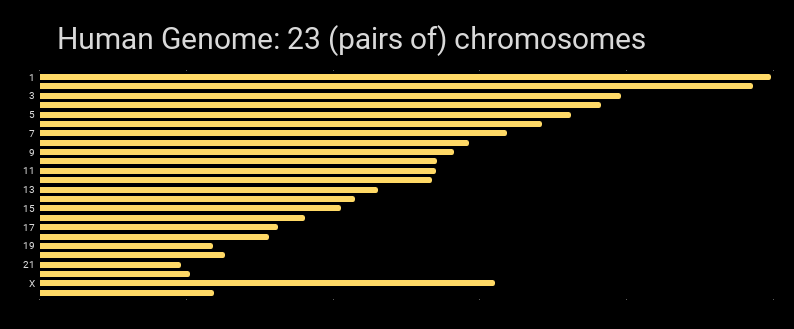
The largest unit of DNA organization in an organism. Humans have two copies of 23 chromosomes. Chromosomes are linear in humans, and all animals and plants. (Bacteria have circular chromosomes.)
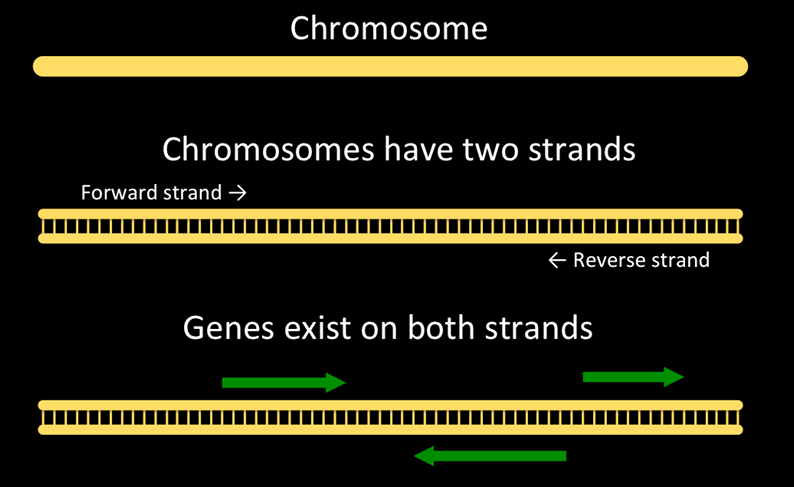
Strand
Chromosomes are double-stranded. One is the forward strand, is typically drawn on top, and moves from left to right. The other, reverse strand, is typically drawn on the bottom and moves from right to left. Genes can occur on either strand. A single gene will have parts on only one stand.
Gene
“What is a gene?” is actually a hotly debated question. For our purposes, a gene is a section of DNA on chromosome strand that creates a molecule used by an organism.
Graphically, the human genome can be shown as the chromosomes that are in it:
And here’s a representation of a chromosome, strands, and genes on the chromosome.
The question we are asking looks like:
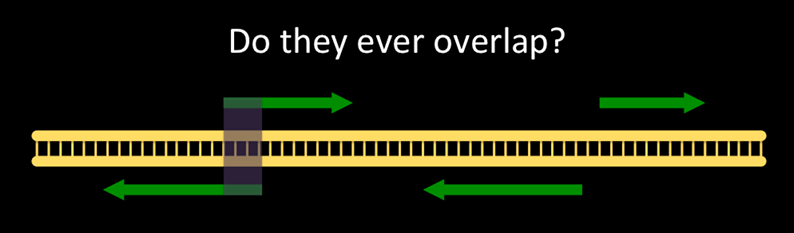
Non-overlapping genes are common. How common are overlapping genes?
Get human data
To answer this question we need to know where genes start and stop on human chromosomes. That seems like a simple question, but if you are new to bioinformatics it’s actually a hard question to answer. Web searches will land you at any number of useful places on the web, but without a lot of background knowledge it’s hard to know what you want: What’s the difference between sequence and annotation? What are FASTA, BED, GTF, GFF3, and VCF? What are GRCh37, GRCh38, hg19, and hg38 (and what happened to hg20 through hg37 - are they okay)?
It turns out that for this particular question (and for many others), most Galaxy instances can help us find this information.
Hands On: Log in to GalaxyIn your web browser, go to your Galaxy instance and log in or register.
The Galaxy interface consists of three main parts. The available tools are listed on the left, your analysis history is recorded on the right, and the central panel will show the home page, tool forms, and dataset content.
Hands On: Start with an empty history
At the start of the tutorial you should ensure that you are working in a new history, i.e. one without any datasets
To create a new history simply click the new-history icon at the top of the history panel:

Get data into Galaxy
There are many ways to get data into a Galaxy instance. We are going to use the Get Data toolbox in the Tools panel on the left.
Hands On: Open Get Data toolbox
Click on the Get Data toolbox to expand it.

The Get Data toolbox contains a list of data sources that this Galaxy instance can get data directly from. Upload file is quite useful for getting data from your computer or from the web (see the Getting data into Galaxy slides). Today we are going to use the UCSC Main table browser.
Get genes
Hands On: Go to UCSC
Click on the tool UCSC Main table browser to go to UCSC.
This will take you to the UCSC Table Browser:
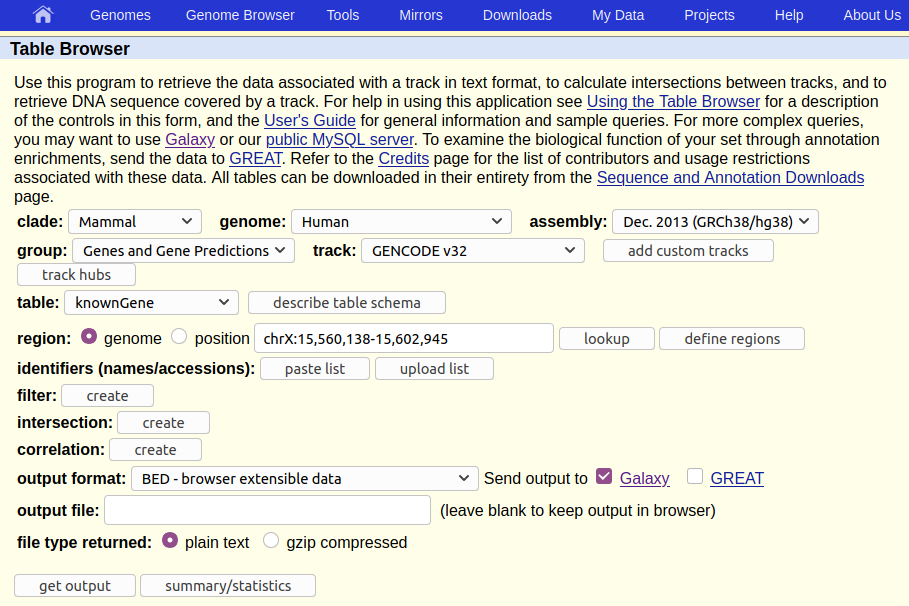
The UCSC Table Browser provides access to all the data that is shown in the UCSC Genome Browser (see box below). If you are working on a species that UCSC supports (like human) then the Table Browser is a great place to get genomic data.
The Table Browser has a daunting number of options. Fortunately, they are all set to commonly used defaults, greatly simplifying things, and most of the options are already set to what we want. In particular, the human genome at version hg38 is already preselected. If the human genome was not what we are interested in, or if we were interested in a different version of it, we could click on Select dataset near the top of the screen to change the default, but for our purpose we only have to verify that what is selected is:
- Assembly:
Dec. 2013 (GRCh38/hg38) - Group:
Genes and Gene Predictions - Track:
GENCODE V49 - Table:
knownGene
Here, Assembly asks which version/definition of the human genome we want. (Any will do for our question, but UCSC is suggesting hg38, which is also an up to date one.) Group is set to Genes and Gene Predictions which sounds like what we want. So far so good.
Track has a bewildering list of options. UCSC suggests GENCODE V49. A web search leads us to the GENCODE web site which prominently states:
The goal of the GENCODE project is to identify and classify all gene features in the human and mouse genomes with high accuracy based on biological evidence…
Warning: ALL GENCODE is different from GENCODEWarning Any recent GENCODE version, V49 or higher, will do for this tutorial though exact numbers calculated in some of the steps will depend on the exact version of the track. Do not, however, select any ALL GENCODE version or you will end up with entirely wrong input data!
Time for a few more definitions.
Comment: Definitions 2
Reference genome
A reference genome is the genome of a single individual that has been thoroughly studied, to the point that we know exactly what most of that individual’s DNA is. In practice a reference genome is used as shared map by researchers working on that organism. Reference genomes are updated periodically as techniques improve.
Sequence
A genome’s sequence describes the DNA in that genome, down to the A, C, T, and G (single nucleotide) level including the exact location where each is. Given a reference genome, you can ask questions like, “What’s the DNA on chromosome 2 between positions 1,678,901 and 1.688,322?”
Genome/Gene annotation
The sequence tells us what DNA is where, but it doesn’t tell us anything about the function of that DNA. Annotation is additional information about particular regions of the genome like where genes, repeats, promotors, and centromeres are, or how active a particular gene is.
The track option asks us which set of annotations do we want to get? There are so many choices because annotation is the result of analysis and interpretation, and there are many ways to do this. (And in this case, many of the options aren’t even genes or gene predictions.)
GENCODE is “high-quality” and “gene annotation.” That sounds like a good thing to use. Lets stay with the default: GENCODE V49 or whatever version is the latest GENCODE when you are doing this tutorial.
So far we haven’t changed anything from the defaults. Lets change something. The default region is the whole genome, which can be done, but it’s a lot of information. For this exercise lets use just one (small) chromosome.
Hands On: Limit the region and get the data.
- Say that we just want chromosome 22
- For region select
position.- In the text box next to
positionenterchr22(case matters).
Click the get output button.
And, that doesn’t actually get us the output. It sends us to a second UCSC page that asks us exactly what we want.
Under Create one BED record per make sure that Whole Gene is selected.
- Click the Send query to Galaxy button at the bottom of the form.

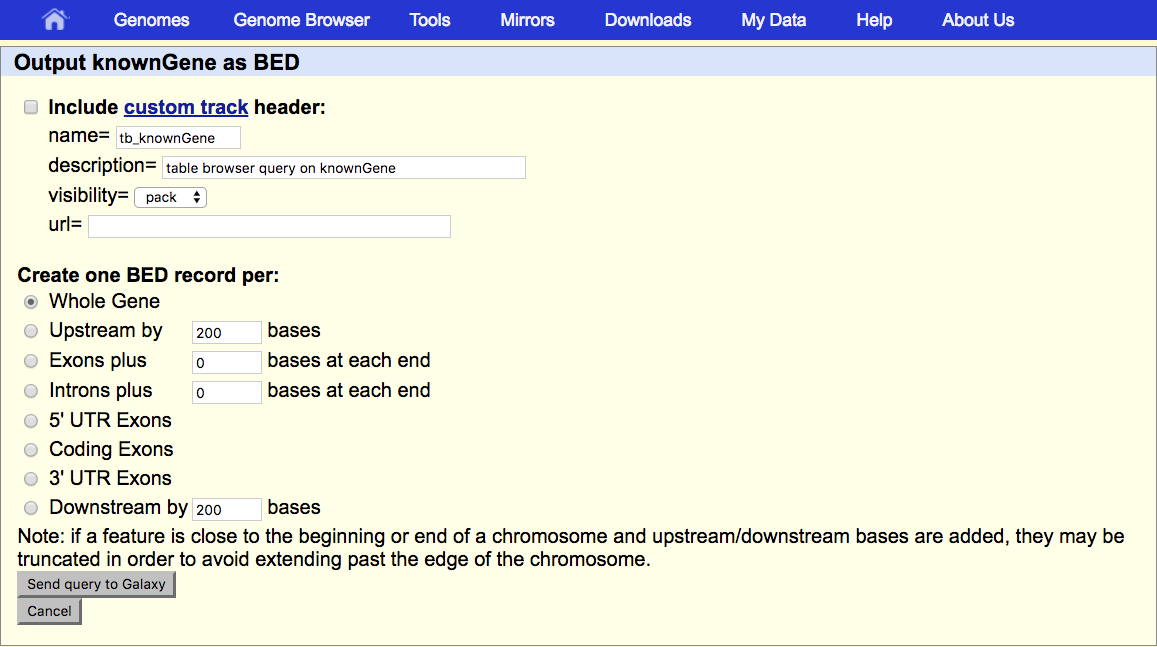
This returns us to Galaxy, first displaying a big green box (that’s good!) and then returning us to the view we started with (if that doesn’t happen, hit the Back button of your browser several/probably three times until you’re back at the regular view of Galaxy). An item should now appear in your history, the dataset from UCSC.
History item status
Watch your new history item. It will go through three statuses before it’s done.
| Color | Icon | Meaning | |
|---|---|---|---|
| Grey | Clock | Item is waiting to start (waiting for data transfer to start) | |
| Yellow | Spinner | Item is running (data is actively being transferred). | |
| Green | None | Item has finished successfully (data transfer complete). | |
| Red | Cross | The job has failed. There can be many reasons. |
You can find more information in the Undestanding Galaxy history system training.
Examine the data
Hands On: Look at the data.Once the dataset is green, click on the dataset name (something like UCSC Main on Human…)
This expands the dataset and shows you information about it, and a preview of its contents.
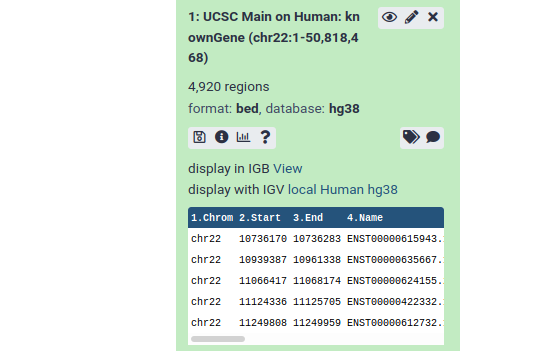
From this preview we can obtain a huge amount of useful information:
- The dataset has over 4000 regions, meaning that there are over 4000 genes on chromosome 22.
- The dataset is in BED format, one of several standards for representing genome annotation. We got BED format because BED was preselected as the output format in the UCSC table browser.
- The dataset’s “database” is hg38. This says which revision of the reference genome this data maps too. hg38 is the latest human reference genome. hg38 was also selected by default in UCSC.
- Finally, it shows us the first 5 rows in the dataset.
The dataset preview is informative, but you can’t see much of the actual dataset. Lets use one of the dataset icons to see the whole dataset:
Hands On: Look at all the data.
Click on the galaxy-eye (eye) icon to view the contents of the dataset. This displays all of the data.
Use the side scroll bars to move through the file.
QuestionHow many columns include the BED file?
Our BED file includes 12 columns, on which the information about the genes distribution along the genome in the chromosome 12 is summarized.
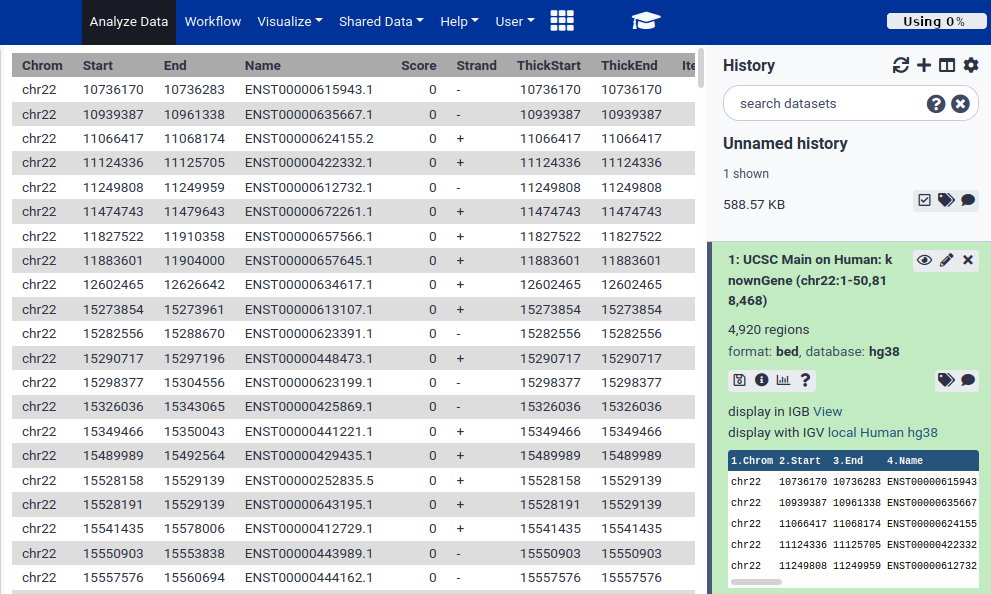
BED is one of several well-established tabular formats for genomic data. Other formats include GFF3 and GTF. For the type of analysis we are doing today, BED format is easiest to work with. BED was created to power the UCSC Genome Browser. BED files contain between 3 and 15 columns. Our example BED file describes genes and contains 12 columns.
We care about columns 1, 2, 3, and 6:
# Column Name Meaning 1 Chromosome The name of the chromosome this gene is on. 2 Start Where on the chromosome the gene starts. 3 End Where on the chromosome the gene ends. 6 Strand Which strand the gene is on. +means forward (top, left to right),-means reverse (bottom, right to left)See the BED format description at UCSC for a full description of all the columns.
Naming
Galaxy allows you to name your analyses (your histories) and your datasets. We only have one history (“Unnamed history”) and one dataset (“UCSC Main on Human:…”) so far, but it’s a good idea to
- Always name your histories
- Name your input and final output datasets, and any significant intermediate datasets.
You don’t have to do this. Galaxy is quite happy for you to have an infinite number of “Unnamed history” histories, and to have all your datasets be obscurely named. However, once you’ve run your first 5 unnamed analyses, all with obscurely named datasets, you’ll might wish you would have named everything.
Hands On: Name your stuff
- Name your history to be meaningful and easy to find.
- Click on the title of the history and enter something like Intro - Strands as the name. Hit the
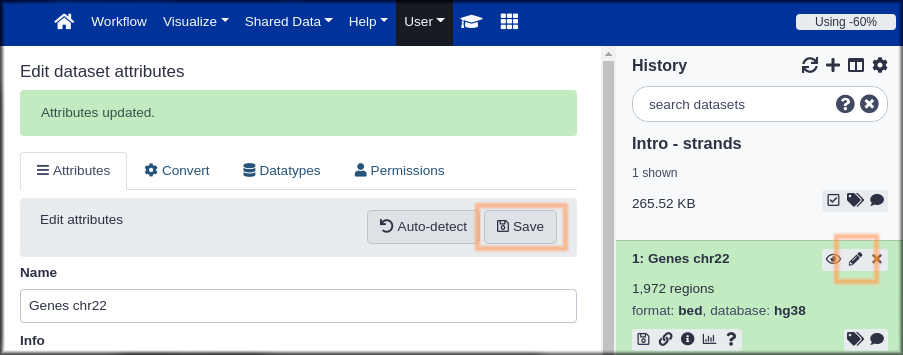
enterkey on your keyboard to save it.- Rename your dataset
- Click on the pencil icon to edit the dataset attributes.
- In the next screen change the name of the dataset to something like
GenesorGenes chr22.- Click the Save button at the bottom of the screen.
Your history should now look something like this:
We’ve got the data - what’s our plan for answering the question?
You have to know what’s possible, before you can build a plan. If you don’t have experience with data analysis then you might not have any idea how you would answer our question. Before we dive in using a particular solution, think about how you might solve this. If you don’t have any experience with tools, then think about how you might solve it manually, using pencil and paper (it may help to assume you have an infinite supply of helpers to do the pencil and paper work).
Here’s how we’ll answer this question:
- Split the genes dataset in two: one for genes on the forward strand, and one for genes on the reverse strand.
- Compare the two datasets to see which ones, if any, overlap.
- Check how many (or what percentage) of our genes overlap with another gene.
It turns out that all of these steps are easy in Galaxy!
Split the genes into forward and reverse datasets
How might we do this? Column 6 contains the strand information. Can we split genes into two datasets based on the value of Column 6. How? Lets take a look at our available tools. And whoa! There are over 40 toolboxes, and several hundred tools. How are we going to find a tool that can do the split?
Hands On: Searching for and launching a tool
- Try the tools search box. Think of terms that might describe what we want to do and type them in the search box. Do you see anything promising? Explore a little.
- If you haven’t already searched with it, enter
filterin the tool search box. Among the results you should see
- Filter data on any column using simple expressions.
- That might work.
- Click on Filter to open the Filter tool in the central panel.
- Take a look at the Syntax and Example sections to understand what the tool does.
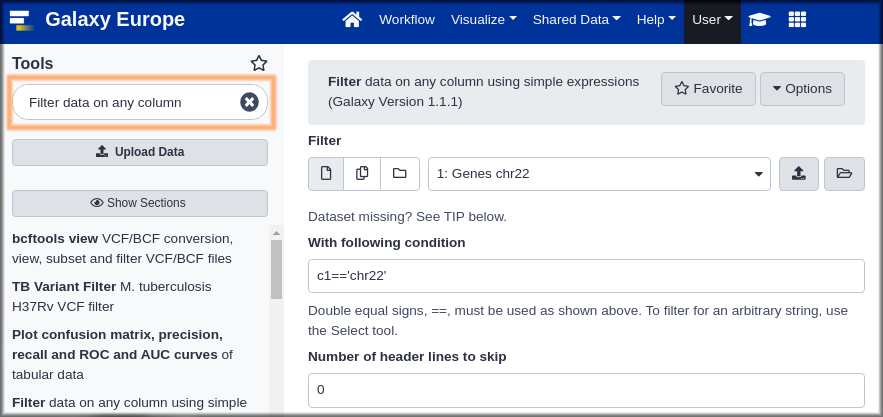
It doesn’t say anything about Filter being able to split a file into multiple files. It does look like we can use Filter to get only genes on the forward strand, or only genes on the reverse strand. We would have to run Filter twice, once for forward strand genes, and once for reverse strand genes. Let’s do that.
Hands On: Run the Filter tool to get genes on the forward strand.
The filter tool has 3 fields:
- Dataset: This pulldown will list any dataset from your history that this tool can work on. In your case that’s probably only one dataset. param-files “filter”:
Genes chr22.- Condition: this free text field is where we specify which records we want in the output dataset. Put in “Condition”:
c6 == "+". This specifies that column 6 (the strand) must be equal to (==is Python for is equal to) a plus sign.“Header lines to skip”:
0Our dataset does not have any header lines.
Finally, click the Execute button.
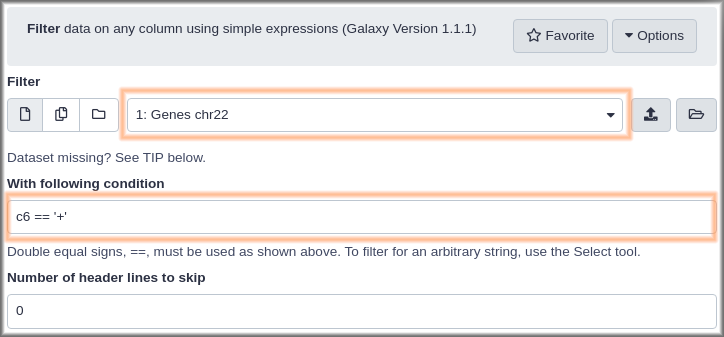
This adds another dataset to your history. This one should contain only genes on the forward strand. Once the dataset is green, click the galaxy-eye (eye) icon to confirm this. We also recommend that you rename this dataset to something like Genes, forward strand (remember how?).
Now we want to get the genes on the reverse strand. There are actually many ways to get this. Here are two of them.
Hands On: Get genes on the reverse strandMethod 1
- Open the dataset preview by clicking on the name of the
Genes, forward stranddataset. This shows an icon than the uploadedGenes chr22dataset did not: a looping arrow.- Click the looping arrow (“Run this job again”) icon. This won’t actually run the job again. What it will do is bring up the Filter tool form with the exact same settings that were used to produce this dataset.
- Rerun Filter but with
- “Condition”:
c6 == "-"- Click the Run Tool button.
Method 2
- Click on Filter in the tool panel to open the Filter tool in the central panel.
- Fill the form as before, except:
- Make sure the Dataset pulldown is set to the
Genes chr22dataset.- Set Condition to
c6 == "-".- Click the Run Tool button.
Both Methods
- Rename your new dataset to something like
Genes, reverse strand
The rerun button can be a huge help as you run more complex tools.
Comment: Empty result?If you used Method 2 and didn’t explicitly set the dataset, then you ran Filter on the
Genes, forward stranddataset. None of the genes in the forward strand dataset have “-“ in column 6 so all of them were filtered out from the result.Try again and set the dataset to your
Genes chr22dataset.
Your history should now have (at least) 3 datasets in it, with names like:
Genes chr22Genes, forward strandGenes, reverse strand
The number of genes in the forward plus reverse datasets should be the same as in the Genes chr22 dataset. If they aren’t can you figure out why?
Check for overlaps
Genes are an example of a genomic interval.
Comment: Definitions 3
- Genomic interval In Galaxy, a genomic interval is a something that spans part of a chromosome (or some other linear frame of reference like a contig). Genes are a common example of a genomic interval. Even a chromosome is a genomic interval, albeit a very long one.
Galaxy excels at answering questions about genomic intervals and different sets of genomic intervals relate to each other. Lets take a look.
Hands On: Genomic Interval Tools
- The next step is finding overlapping intervals, so type
intervalin the tool search box. There are many results from this search, so you might want to click the Show sections button to see which sections the tools are organised into.- Explore the tools in this toolbox, looking for something that we can use to see which genes on opposite strands overlap.
Although there are the bedtools (section BED) and a section Operate on Genomic Intervals offering promising tools, the simple Intersect tool under Text Manipulation appears sufficient. Let’s try Intersect.
Hands On: Genomic Interval Tools
- Intersect ( Galaxy version 1.0.0) with the following parameters:
- “Return”:
Overlapping Intervals. This looks like it might return whole genes, whileOverlapping piecesmay return only the parts that overlap. We suspect that whole genes might be more useful.- param-files“of”:
Genes, forward strand(the first dataset)- param-files “that intersect” :
Genes, reverse strand(the second dataset)“for at least”:
1This will return genes with even just one position overlapping.
- Click Run Tool.
Now repeat the intersect, but make the first dataset be the reverse genes, and the second be the forward genes.
- Finally give both of the new datasets meaningful names, like
Overlapping forward genesandOverlapping reverse genes
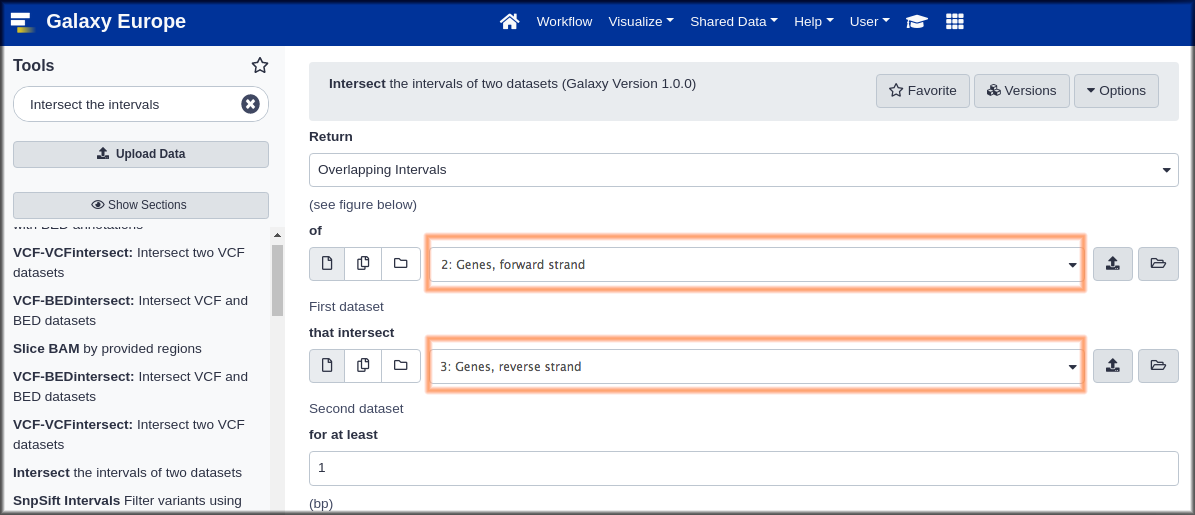
Results and final steps.
At this point we could say that we have answered our question. Using dataset previews in the history panel, we can compare the number of genes in the Overlapping forward and Overlapping reverse datasets with the number of genes in the full Genes chr22 dataset, and conclude that overlapping genes on opposite strands are actually pretty common.
However, before we rush off to publish our conclusions, let’s
- Get both the forward and reverse overlapping genes into a single dataset (one link will look better in our publication), and
- Visualize our new dataset, just to double-check our results.
Combine forward and reverse overlapping genes into one dataset.
What tool can we use to combine the two datasets into one? Try searching for combine or join or stack in the tool search box. You’ll find lots of tools, but none of them do what we want to do. Some times you just have to manually look through toolboxes to find what you need. Where should we look? It’s probably not Get Data or Send Data, but it could easily be in any of the next 4 toolboxes: Lift-Over, Collection Operations, Text Manipulation, or Datamash.
It turns out that Lift-Over and Collection Operations are not what we want. (But, take a look at them: if you are going to work with genomic data it won’t take long before you’ll need both.)
Hands On: Concatenate two datasets
- Open the Text Manipulation toolbox.
- Near the top of the toolbox is Concatenate multiple datasets or collections. Click on it. Lets try that tool.
- Concatenate multiple datasets or collections with the following parameters:
- param-files “Concatenate Dataset”:
Overlapping reverse genes.- “Dataset”
Click on param-repeat “Insert Dataset”
This adds a second dataset pull-down menu to the form.
In “1: Dataset”:
- param-files “Select”:
Overlapping forward genesas the second dataset.- Click Run Tool
- Rename the resulting dataset something informative like
Overlapping genes
Once the concatenate operation is finished, preview the dataset in your history panel. Does it have the expected number of genes in it? If not, see if you can figure out what happened.
As the name of the tool suggests, it has simply taken the second input and glued it to the end of the first input to form the new dataset. Now all reverse-strand genes are listed before the forward-strand genes, independent of their genomic location. While that’s not necessarily a problem, it may be nicer to sort the genes back into the position-based order we originally obtained them in.
Hands On: Sort the overlapping genes by genomic position
- Sort ( Galaxy version 9.5+galaxy3) data in ascending or descending order with the following parameters:
- param-file “Sort Query”:
Overlapping genes.- param-repeat “Column selections”:
- In “1: Column selections”:
- “Sort on column”:
Column 1- “in”:
Ascending order- “using sort flavor”:
Natural/Version sort (-V)- Click on param-repeat “Insert Column selections”
- In “2: Column selections”:
- “Sort on column”:
Column 2- “in”:
Ascending order- “using sort flavor”:
Fast numeric sort (-n)- Click on param-repeat “Insert Column selections”
- In “3: Column selections”:
- “Sort on column”:
Column 3- “in”:
Ascending order- “using sort flavor”:
Fast numeric sort (-n)- Click Run Tool
- Rename the resulting dataset to, for example,
Overlapping genes sorted
We now have a new dataset with the genes sorted first by chromosome (which is not strictly necessary in our case because we know all genes are from the same chromosome chr22, but is important, of course, in the general case), then by start position on the chromosome and, finally, by end position (in case that’s needed to break ties).
Visualize the overlapping genes
Galaxy knows about several visualization options for lots of different dataset types, including BED. Whenever you preview a dataset in the history panel, Galaxy provides links to these visualizations. For BED files (which is the format we have), options include IGB, IGV, and UCSC main. IGB and IGV are widely used desktop applications and eventually you may want to install one or both of them. For now, let’s visualize the data at UCSC, using the UCSC Genome Browser.
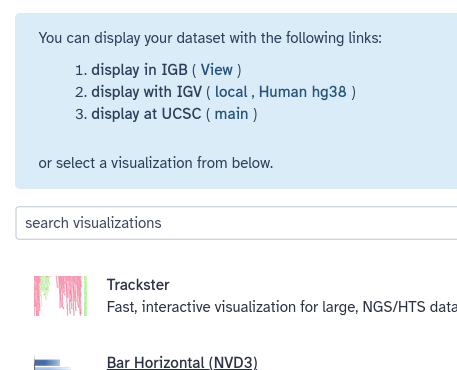
Hands On: Display data in Genome Browser
- Click on your
Overlapping genes sorteddataset in your history panel. This will show the dataset preview in the history panel.- Click to expand the dataset, if it isn’t already, so that you can see the dataset metadata and additional actions like Visualize.
- Click on the galaxy-barchart (Visualize) icon
- Click on the display at UCSC (main) link that appears in the blue box at the top of the screen.
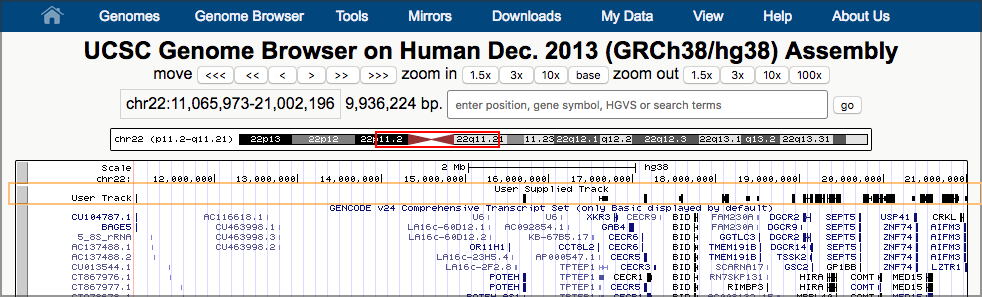
Possibly after some delay, this will launch a new window, showing UCSC’s Genome Browser with our dataset shown right at the top. UCSC figures out that our first overlapping gene is ~11 million bases into chromosome 22, and it has landed us there.
Comment: Background: UCSC Genome Browser
Genome browsers are software for viewing genomic information graphically. The UCSC Genome Browser (and most genome browsers) typically display different types of annotation about a region of a genome. This is displayed as a stack of tracks and each track contains a different type of information.
Genome browsers are useful for seeing information in context and for seeing (and discovering) correlations between different types of information. (They are also useful for visually checking results, which is what we are doing now.)
The UCSC Genome Browser has information on over 100 animals, and their Archaeal Genome Browser has genomic information on well over 100 microbial species.
Now, take a look at one of our results. (Any pair of overlapping genes will do.) Our data is in the second to top track (User Track / User Supplied Track). That track shows a line of small black boxes, sometimes connected with a line.
Hands On: Zoom in on an area of the chromosome that shows a set of linked black boxesTo zoom in,
- Click on the Scale track (the top track) just to the left of the start of the black boxes.
- Now drag the mouse across the Scale track to just to the right of the black boxes and let go.
- A window pops up describing several ways to interact with the browser. Just click the Zoom In button at the bottom.
- This redraws the window, this time zoomed in to what you highlighted.
- Continue to zoom in until you have the set of linked black boxes you picked centered on the screen.
- Once you are as zoomed as you want to be, click on one of the linked boxes. This will expand the track:

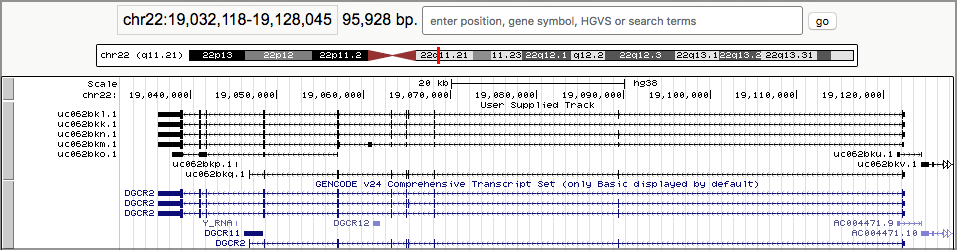
The black boxes connected by lines represent genes, and each set of connected boxes is a single gene (actually, a single transcript of a gene). Take a close look at the top several tracks.
- It looks like we preserved the gene definitions just fine.
- It looks like, sure enough, there are overlapping genes here, and they are on opposite sides. The arrows on the connecting lines tell us which strand the gene is on.
Um, what’s up with the boxes and the lines connecting them?
Comment: Definitions 4
- Exon In humans (and in all plants and animals) the molecules that are built from genes are often only built from a part of the DNA in the gene. The sections of DNA that can produce the molecules are called exons.
As you may have guessed (or already knew): The black boxes are exons. Genes are defined as covering the entire area from the first black box to the last connected black box.
Do we have a problem?
Maybe.
Our ad hoc review of identified overlapping genes in the UCSC Genome Browser has (or should have!) confirmed that every gene we said has an overlapping gene on the opposite strand does in fact have that. So, our conclusion appears solid: A significant percentage of genes do overlap with other genes on the opposite strand.
But, our conclusion may not be as significant as we had hoped. If only parts of genes, the exons, make stuff in our bodies, then should we have run this analysis on just the exons rather then the entire genes? Probably.
Let’s refine our question slightly
Question: Our Revised Motivating QuestionI wonder if exons on opposite strands ever overlap with each other, and if so, how common is that?
So, I have to do this all over again, but with exons?
Well, yes and no. We will have to run the analysis again, this time on exons instead of whole genes. But we won’t have to manually recreate every step of our analysis. Galaxy enables us to create a reusable workflow from the analysis we just did, and then we can rerun the analysis, as one step, anytime we want to, and on any dataset.
Walk through the workflow tutorial
Run the Create a reusable workflow from a history tutorial for how to do this, and then come back here to run your newly created workflow with the exon data.
Rerun analysis with exon data
We want to run the same analysis, but this time only look for overlaps that happen in exons, the parts of genes that produce stuff our body uses. Before we start looking at exons, let’s start a new history, one that contains only the genes file we got from UCSC. We could go back to UCSC and refetch the file, but there is an easier way.
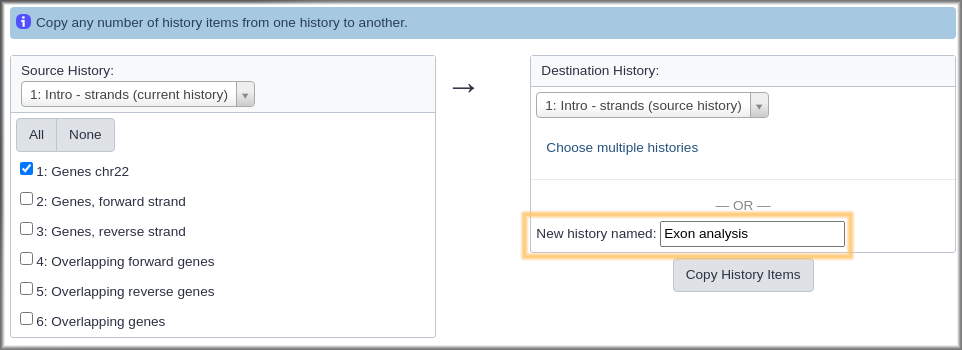
Hands On: Create a new history that contains some data from current history
- Click on galaxy-history-options History options at the top of the history panel.
- Select the Copy Datasets option from the pull down menu. This launches the copy datasets form.
- Under Source History:, select the dataset(s) you want to copy to the new history.
- In our case, we only want the
Genes chr22dataset.- Under Destination History enter an informative history name in the New history named: box.
- For example,
Exon overlaps on opposite strands- Click the Copy History Items button to create your new history.
- This creates a new history (with the copied dataset) and throws up a green box saying: “1 dataset copied to 1 history:
name you gave your new history.”- The history name is a link. Click on it.
Get the exon data
And your new history appears in the history panel with the copied genes dataset. What we need is exons. How can we get the exon information? There are two relatively easy ways to get this information, one of which will be very familiar.
The first method involves going back to the UCSC Table Browser. Everything on the first form would stay the same: We still want human, hg38, GENCODE v41, and just chr22. The second form is what changes. Instead of getting the Whole Gene, we need to retrieve the Coding Exons only.
The second method is to use the Gene BED To Exon/Intron/Codon BED expander tool in the Operate on Genomic Intervals toolbox to extract the exon information from the genes BED file we already have. (Of course! you say. Umm, there is no way that you should have known that you already had this information in the genes file, or that this tool existed.)
Hands On: Get the exon data
- Get the exon information, either by revisiting UCSC, or by using the Gene BED To Exon/Intron/Codon BED expander tool. If you use the expander tool select Coding Exons only from the Extract pull-down.
- Give the resulting dataset a meaningful name.
If you got the data from UCSC it will look something like this:
Your history should now have two datasets: one describing entire genes, and one describing just the exons.
Rerun the analysis, this time on exons.
When you did the History to Workflow tutorial you created a new workflow that was then added to your list of defined workflows.
Hands On: Run the workflow on the exon data.
Click the Workflow tab in the menu at the top of the Galaxy page.
This lists all of your defined workflows, including the one you just created.
Click on the workflow-run (Run workflow) button next to your workflow.
This launches the workflow run form (which you also saw when testing this workflow)
Select No under Send results to a new history
If you do not see this option displayed, click on Expand to full workflow form to reveal it.
- Set the first (and only) input dataset to the
Exonsdataset, using the pull-down menu.- Click the Run workflow button.
And Galaxy launches the workflow and says (in a nice big green box) something like:
You can check the status of queued jobs and view the resulting data by refreshing the History pane.
Which in this case is the truth. You can refresh the history panel by either reloading the whole page, of by clicking the looping arrow icon at the top of the history panel. What you’ll see is a stack of history steps that will go from queued to running to done as you watch them.
All steps in the history will be green when the workflow is done. Once that happens compare your output dataset with your input dataset? What percentage of exons overlap with other exons on the opposite strand, and is it common or rare? Is it a smaller percentage than we saw for whole genes?
Are we done?
Probably. Note that we can no longer say what percentage of genes overlap. We can say what percentage of exons overlap, and that is probably close enough for our goals. If it isn’t and we actually need to say what percentage of genes overlap, then we will have to do some extra work. This can be done is several ways, but the Galaxy 101 tutorial may give you some ideas on how to follow this question all the way to genes.
Conclusion
trophy Well done! You have just performed your first analysis in Galaxy!
You could just as easily use Excel to answer the same question, and if the goal is to learn how to use a tool, then either tool would be great! But what if you are working on a question where your analysis matters? Maybe you are working with human clinical data trying to diagnose a set of symptoms, or you are working on research that will eventually be published and maybe earn you a Nobel Prize?
In these cases your analysis, and the ability to reproduce it exactly, is vitally important, and Excel won’t help you here. It doesn’t track changes and it offers very little insight to others on how you got from your initial data to your conclusions.
Galaxy, on the other hand, automatically records every step of your analysis. And when you are done, you can share your analysis with anyone. You can even include a link to it in a paper (or your acceptance speech). In addition, you can create a reusable workflow from your analysis that others (or yourself) can use on other datasets.
Another challenge with spreadsheet programs is that they don’t scale to support next generation sequencing (NGS) datasets, a common type of data in genomics, and which often reach gigabytes or even terabytes in size. Excel has been used for large datasets, but you’ll often find that learning a new tool gives you significantly more ability to scale up, and scale out your analyses.
You've Finished the Tutorial
Key points
Galaxy provides an easy-to-use graphical user interface for often complex command-line tools
Galaxy keeps a full record of your analysis in a history
Workflows enable you to repeat your analysis on different data
Galaxy can connect to external sources for data import and visualization purposes
Galaxy provides ways to share your results and methods with others
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsFeedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Dave Clements, Cristóbal Gallardo, Introduction to Genomics and Galaxy (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/introduction/tutorials/galaxy-intro-strands/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{introduction-galaxy-intro-strands, author = "Dave Clements and Cristóbal Gallardo", title = "Introduction to Genomics and Galaxy (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/introduction/tutorials/galaxy-intro-strands/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Funding
These individuals or organisations provided funding support for the development of this resource
Congratulations on successfully completing this tutorial!

You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/introduction/tutorials/galaxy-intro-strands/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: text_processing owner: bgruening revisions: ddf54b12c295 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: ab83aa685821 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: intersect owner: devteam revisions: 69c10b56f46d tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/