From peaks to genes
| Author(s) |
|
| Editor(s) |
|
| Reviewer(s) |
|
OverviewQuestions:
Objectives:
How to use Galaxy?
How to get from peak regions to a list of gene names?
Familiarize yourself with the basics of Galaxy
Learn how to obtain data from external sources
Learn how to run tools
Learn how histories work
Learn how to create a workflow
Learn how to share your work
Time estimation: 3 hoursLevel: Introductory IntroductorySupporting Materials:
- Datasets
- Workflows
- galaxy-history-answer Answer Histories
- FAQs
- video Recordings
- instances Available on these Galaxies
Published: Mar 29, 2016Last modification: Mar 30, 2026License: Tutorial content is licensed under Creative Commons Attribution 4.0 International License. The GTN framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00189rating Rating: 5.0 (1 recent ratings, 1 all time)version Revision: 69
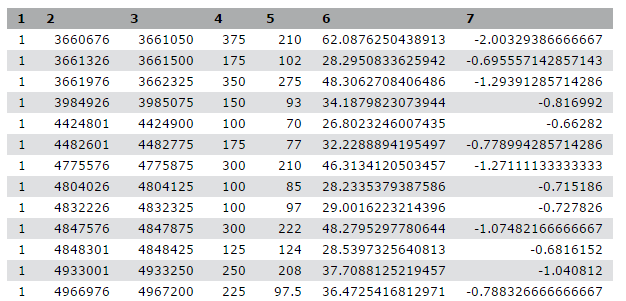
We stumbled upon a paper (Li et al. 2012) called “The histone acetyltransferase MOF is a key regulator of the embryonic stem cell core transcriptional network”. The paper contains the analysis of possible target genes of an interesting protein called Mof. The targets were obtained by ChIP-seq in mice and the raw data is available through GEO. However, the list of genes is neither in the supplement of the paper, nor part of the GEO submission. The closest thing we could find is a file in GEO containing a list of the regions where the signal is significantly enriched (so called peaks):
| 1 | 3660676 | 3661050 | 375 | 210 | 62.0876250438913 | -2.00329386666667 |
| 1 | 3661326 | 3661500 | 175 | 102 | 28.2950833625942 | -0.695557142857143 |
| 1 | 3661976 | 3662325 | 350 | 275 | 48.3062708406486 | -1.29391285714286 |
| 1 | 3984926 | 3985075 | 150 | 93 | 34.1879823073944 | -0.816992 |
| 1 | 4424801 | 4424900 | 100 | 70 | 26.8023246007435 | -0.66282 |
Table 1 Subsample of the available file
The goal of this exercise is to turn this list of genomic regions into a list of possible target genes.
Comment: Results may varyYour results may be slightly different from the ones presented in this tutorial due to differing versions of tools, reference data, external databases, or because of stochastic processes in the algorithms.
AgendaIn this tutorial, we will deal with:
Pretreatments
Hands On: Open Galaxy
- Browse to a Galaxy instance: the one recommended by your instructor or one in the list Galaxy instance on the head of this page
Log in or register (top panel)

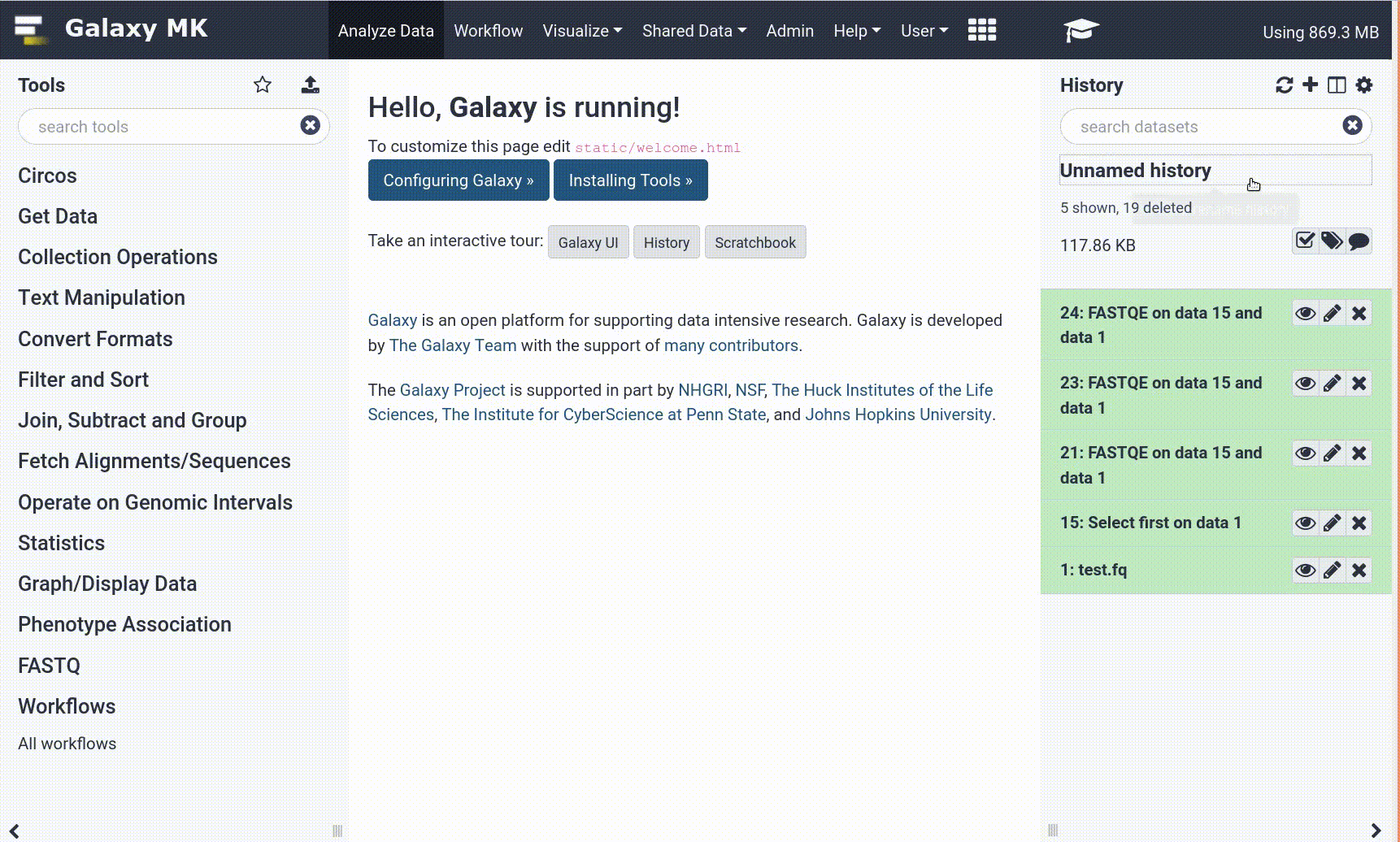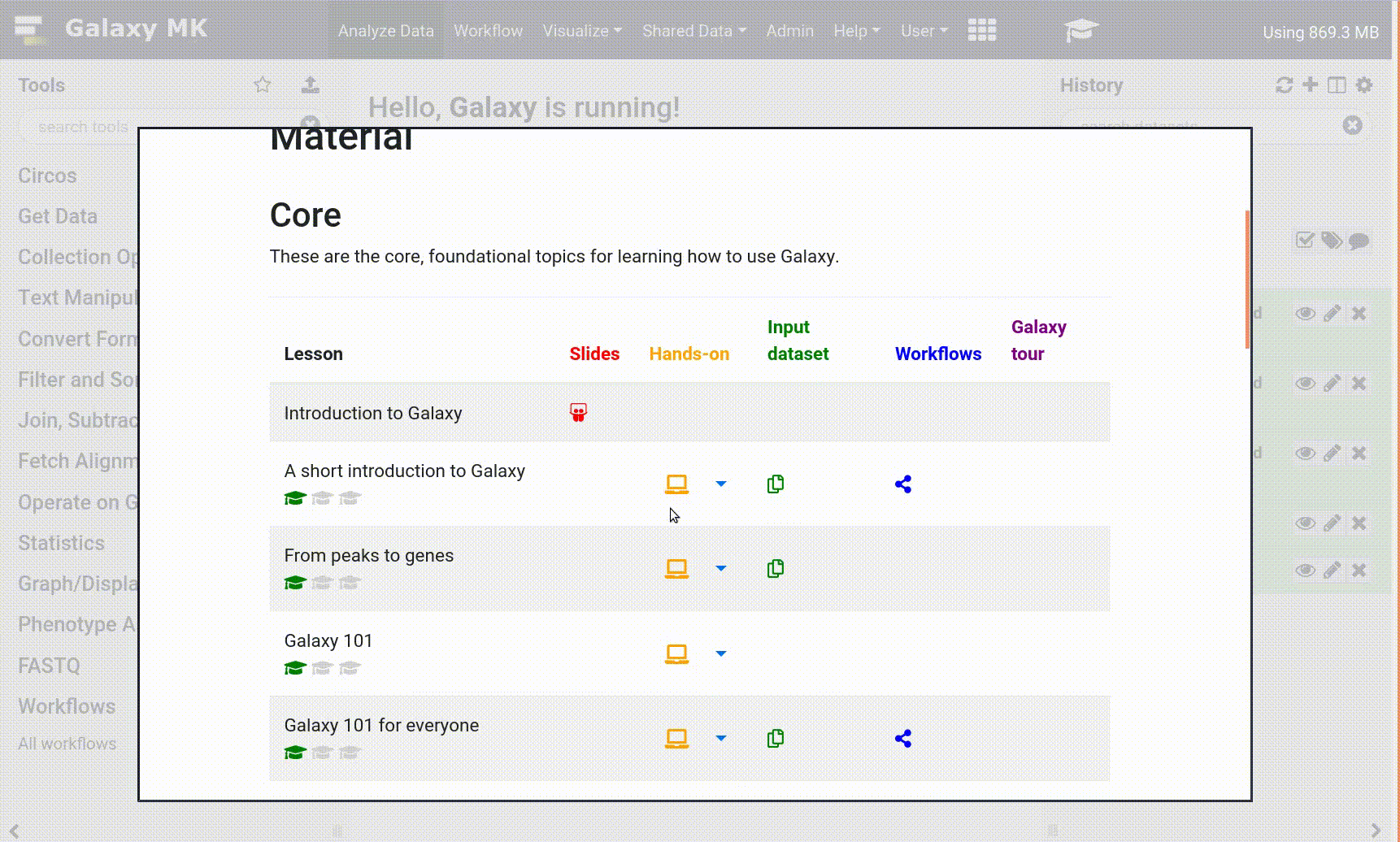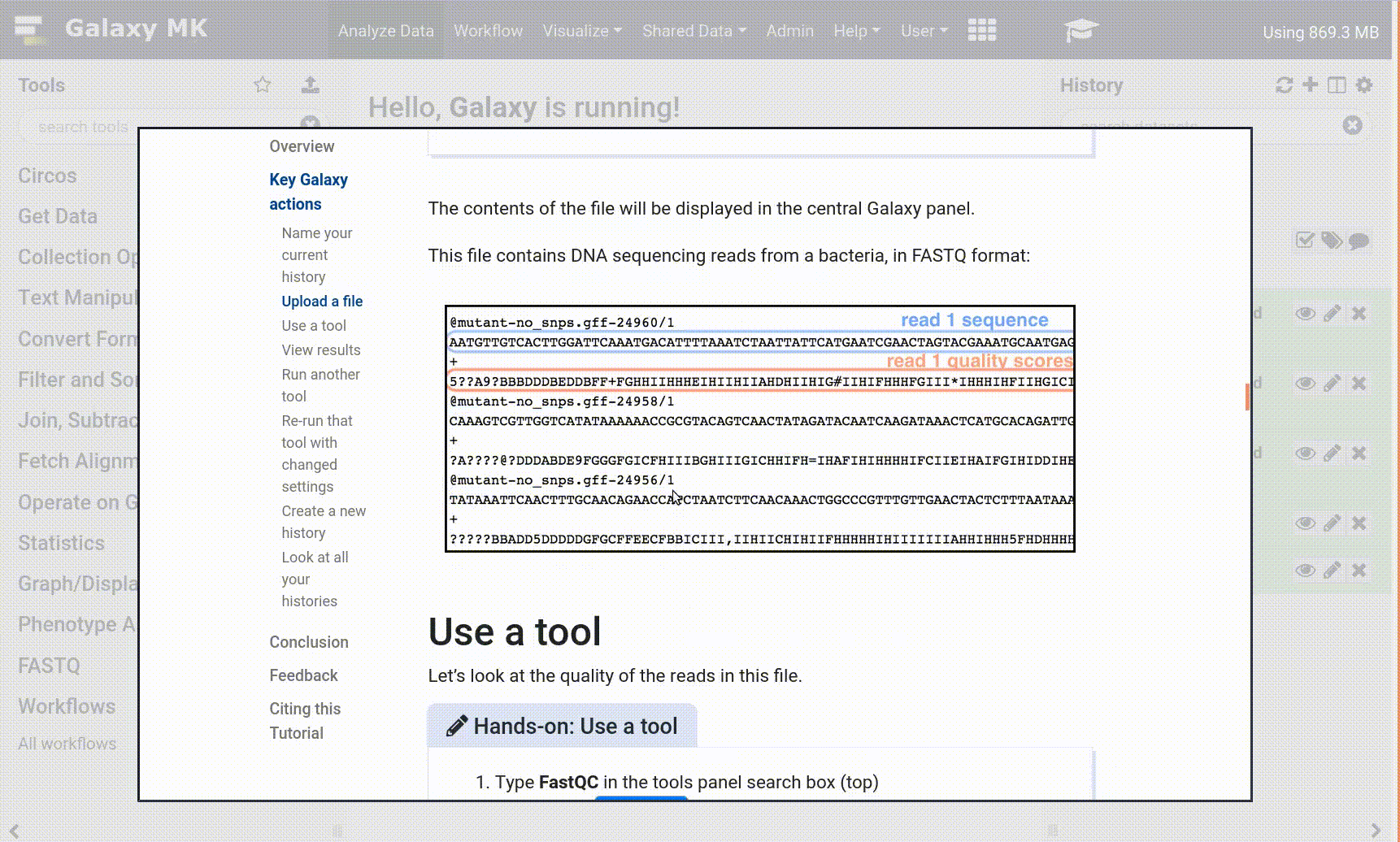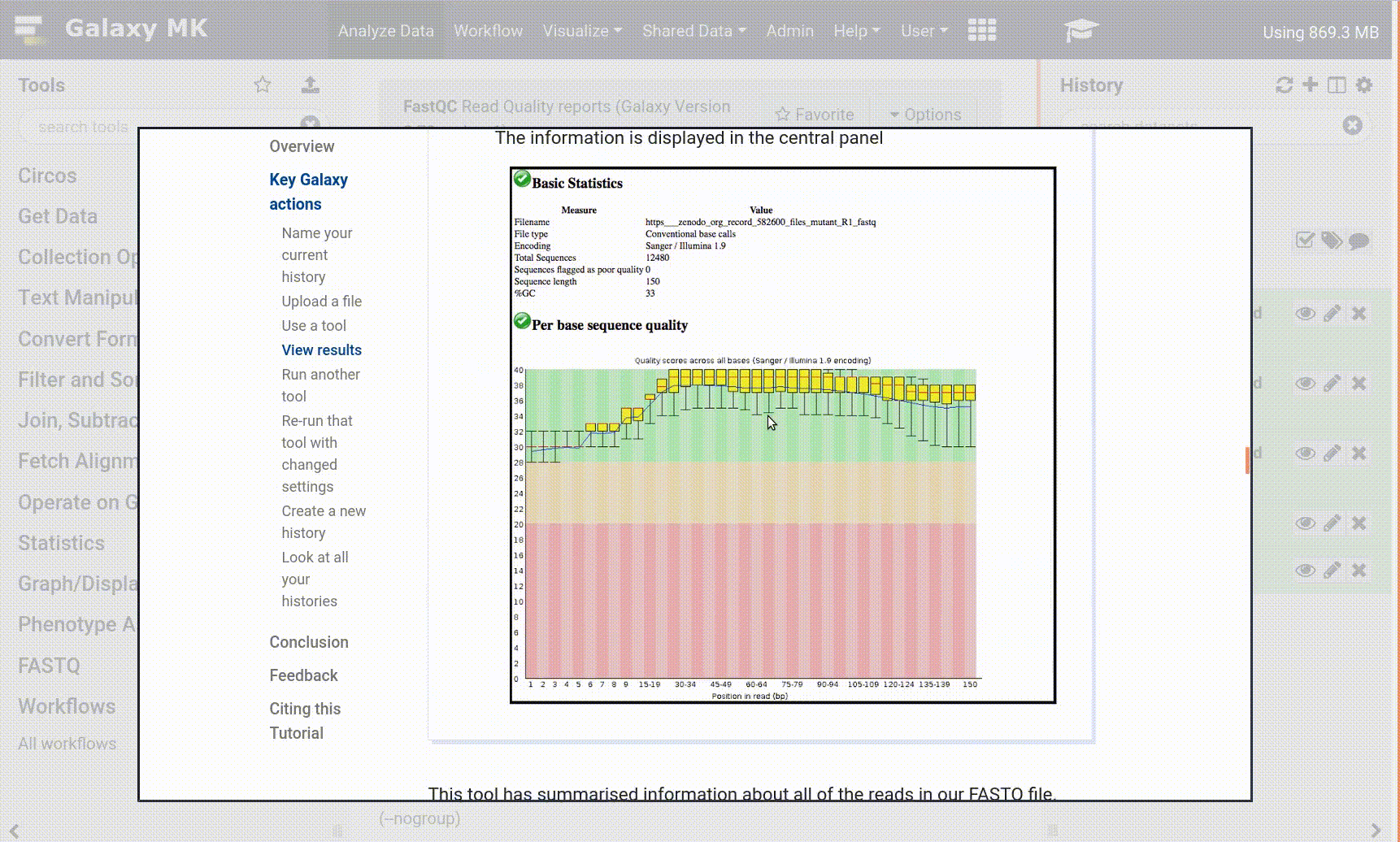
The Galaxy interface consist of three main parts. The available tools are listed on the left, your analysis history is recorded on the right, and the central panel will show the tools and datasets.
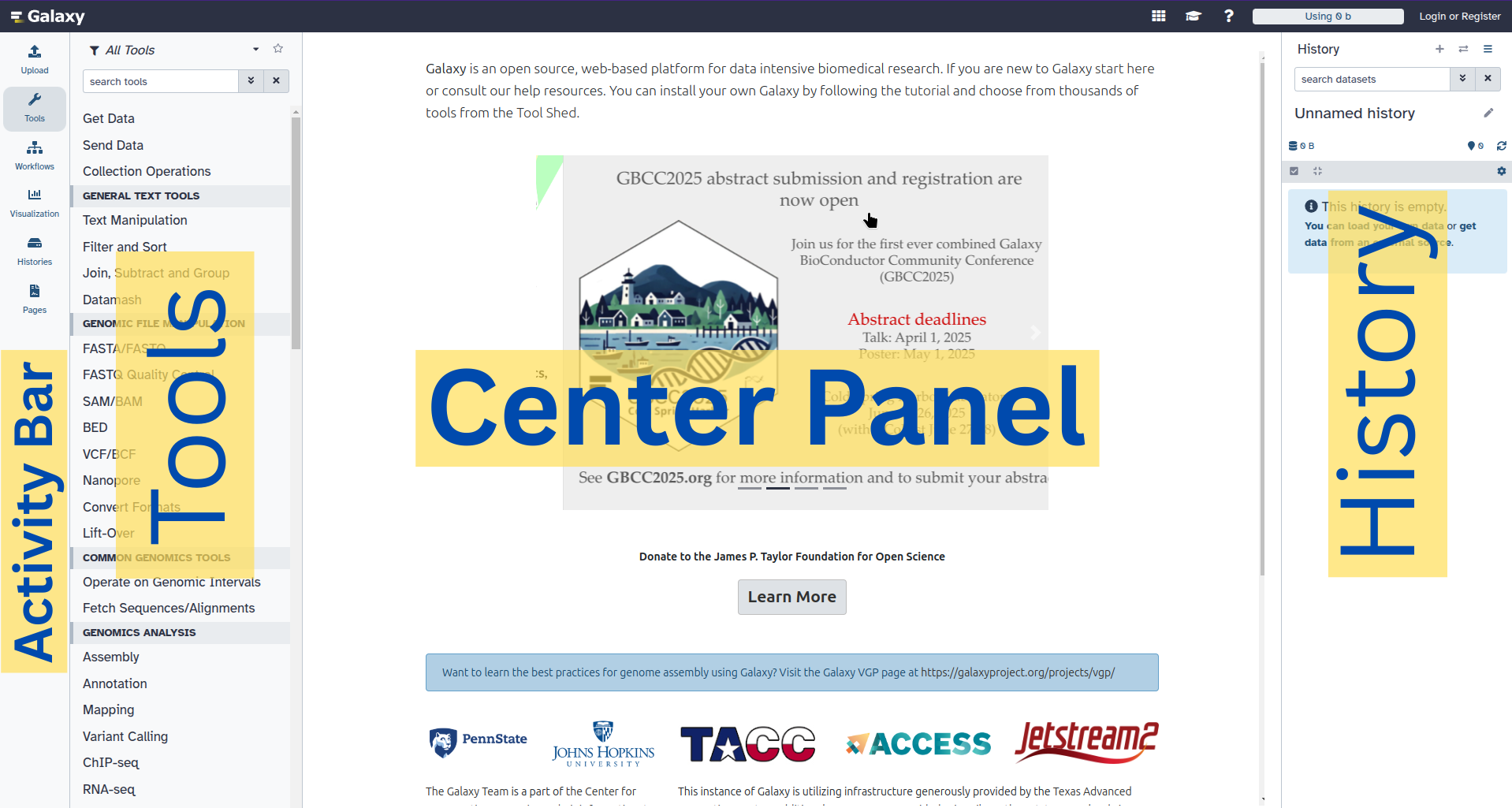 Open image in new tab
Open image in new tabLet’s start with a fresh history.
Hands On: Create history
Make sure you have an empty analysis history.
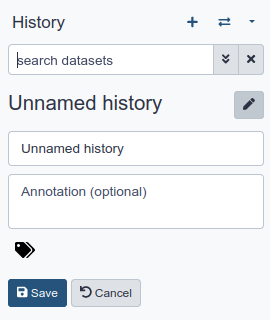
To create a new history simply click the new-history icon at the top of the history panel:
Rename your history to make it easy to recognize
Click on the title of the history (by default the title is
Unnamed history)
- Type
Galaxy Introductionas the name- Press Enter

Data upload
Hands On: Data upload
- Download the list of peak regions (the file GSE37268_mof3.out.hpeak.txt.gz) from GEO to your computer
Click on the upload button in the upper left of the interface
- Press Choose local files and search for your file on your computer
- Select
intervalas Type- Press Start
- Press Close
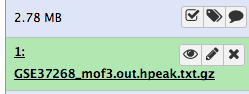
Wait for the upload to finish. Galaxy will automatically unpack the file.
After this you will see your first history item in Galaxy’s right pane. It will go through the gray (preparing/queued) and yellow (running) states to become green (success):
Directly uploading files is not the only way to get data into Galaxy
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Change Type (set all): from “Auto-detect” to
intervalPress Start
- Close the window
There are more options for advanced users.

Comment: Interval file formatInterval format is a Galaxy format for representing genomic intervals. It is tab-separated, but has the added requirement that three of the columns must be:
- chromosome ID
- start position (0-based)
- end position (end-exclusive)
An optional strand column can also be specified, and an initial header row can be used to label the columns, which do not have to be in any special order. Unlike BED format (see below) arbitrary additional columns can also be present.
You can find more information about formats that can be used in Galaxy at the Galaxy Data Formats page.
Hands On: Inspect and edit attributes of a file
Click on the file in the history panel
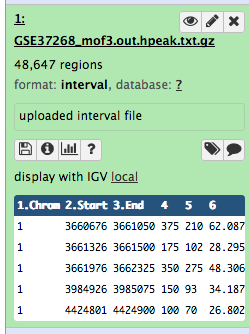
Some meta-information (e.g. format, reference database) about the file and the header of the file are then displayed, along with the number of lines in the file (48,647):
Click on the galaxy-eye (eye) icon (View data) in your dataset in the history
The content of the file is displayed in the central panel
Click on the galaxy-pencil (pencil) icon (Edit attributes) in your dataset in the history
A form to edit dataset attributes is displayed in the central panel
Search for
mm9in Database/Build attribute and selectMouse July 2007 (NCBI37/mm9)(the paper tells us the peaks are frommm9)
- Click on Save at the bottom
Add a tag called
#peaksto the dataset to make it easier to track in the historyDatasets can be tagged. This simplifies the tracking of datasets across the Galaxy interface. Tags can contain any combination of letters or numbers but cannot contain spaces.
To tag a dataset:
- Click on the dataset to expand it
- Click on Add Tags galaxy-tags
- Add tag text. Tags starting with
#will be automatically propagated to the outputs of tools using this dataset (see below).- Press Enter
- Check that the tag appears below the dataset name
Tags beginning with
#are special!They are called Name tags. The unique feature of these tags is that they propagate: if a dataset is labelled with a name tag, all derivatives (children) of this dataset will automatically inherit this tag (see below). The figure below explains why this is so useful. Consider the following analysis (numbers in parenthesis correspond to dataset numbers in the figure below):
- a set of forward and reverse reads (datasets 1 and 2) is mapped against a reference using Bowtie2 generating dataset 3;
- dataset 3 is used to calculate read coverage using BedTools Genome Coverage separately for
+and-strands. This generates two datasets (4 and 5 for plus and minus, respectively);- datasets 4 and 5 are used as inputs to Macs2 broadCall datasets generating datasets 6 and 8;
- datasets 6 and 8 are intersected with coordinates of genes (dataset 9) using BedTools Intersect generating datasets 10 and 11.
Now consider that this analysis is done without name tags. This is shown on the left side of the figure. It is hard to trace which datasets contain “plus” data versus “minus” data. For example, does dataset 10 contain “plus” data or “minus” data? Probably “minus” but are you sure? In the case of a small history like the one shown here, it is possible to trace this manually but as the size of a history grows it will become very challenging.
The right side of the figure shows exactly the same analysis, but using name tags. When the analysis was conducted datasets 4 and 5 were tagged with
#plusand#minus, respectively. When they were used as inputs to Macs2 resulting datasets 6 and 8 automatically inherited them and so on… As a result it is straightforward to trace both branches (plus and minus) of this analysis.More information is in a dedicated #nametag tutorial.
The dataset should now look like below in the history


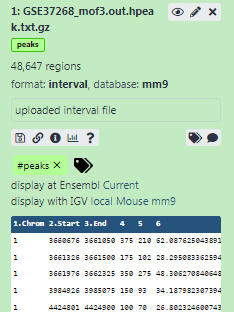
In order to find the related genes to these peak regions, we also need a list of genes in mice, which we can obtain from UCSC.
Hands On: Data upload from UCSC
Search for
UCSC Mainin the tool search bar (top left)
Click on
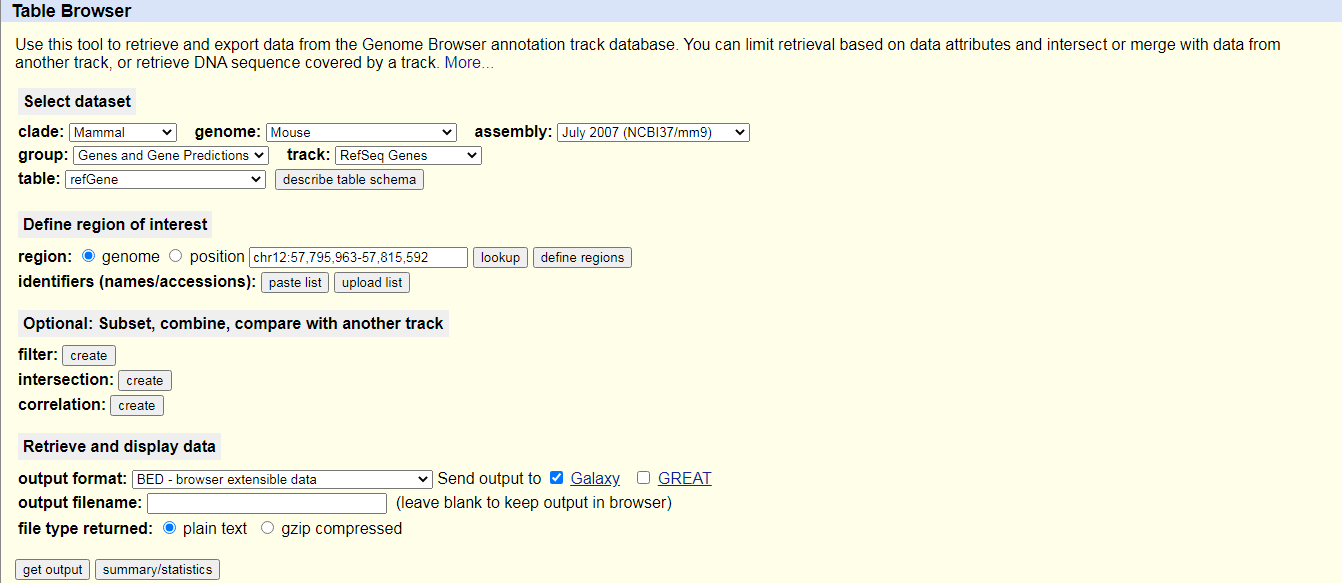
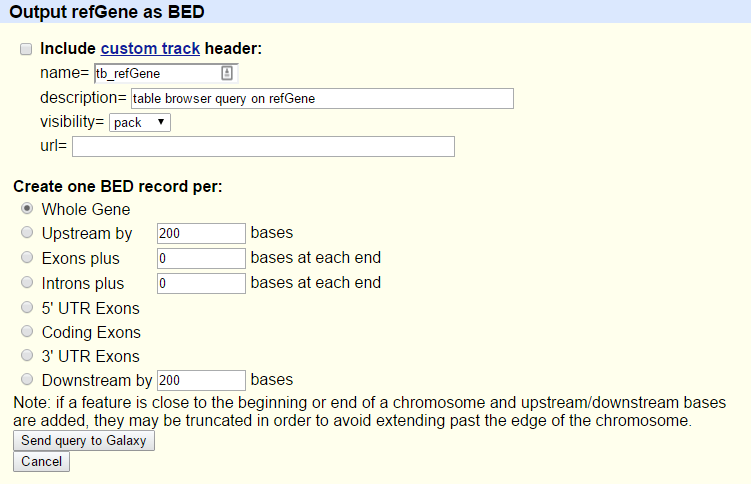
UCSC MaintoolYou will be taken to the UCSC table browser, which looks something like this:
- Set the following options:
- “Clade”:
Mammal- “Genome”: Search for
mm9and selectMouse (mm9)- “Assembly”:
July 2007 (NCBI37/mm9)- “Group”:
Genes and Gene Predictions- “Track”:
RefSeq Genes- “Table”:
refGene- “Region”:
Genome- “Output format”:
BED - browser extensible data- “Send output to”:
Galaxy(only)Click on the Get output button
You will see the next screen:
- Make sure that “Create one BED record per” is set to
Whole Gene- Click on the Send query to Galaxy button
- Wait for the upload to finish
Rename our dataset to something more recognizable like
Genes
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, change the Name field to
Genes- Click the Save button
- Add a tag called
#genesto the dataset to make it easier to track in the history
Comment: BED file formatThe BED - Browser Extensible Data format provides a flexible way to encode gene regions. BED lines have three required fields:
- chromosome ID
- start position (0-based)
- end position (end-exclusive)
There can be up to and nine additional optional fields, but the number of fields per line must be consistent throughout any single set of data.
You can find more information about it at UCSC including a description of the optional fields.
Now we have collected all the data we need to start our analysis.
Part 1: Naive approach
We will first use a “naive” approach to try to identify the genes that the peak regions are associated with. We will identify genes that overlap at least 1bp with the peak regions.
File preparation
Let’s have a look at our files to see what we actually have here.
Hands On: View file content
Click on the galaxy-eye (eye) icon (View data) of the peak file to view the content of it
It should look like this:
View the content of the regions of the genes from UCSC
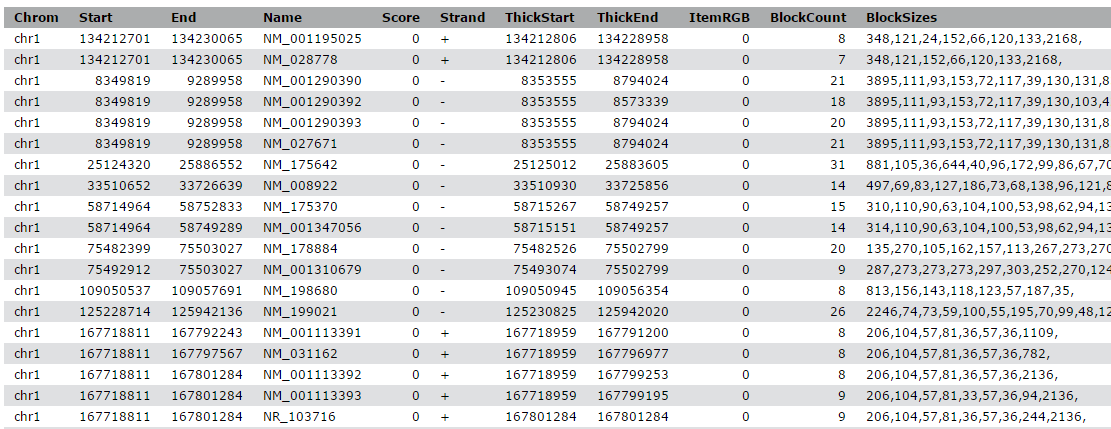
To view both the files side by side for comparision, enable the window manager.
If you would like to view two or more datasets at once, you can use the Window Manager feature in Galaxy:
- Click on the Window Manager icon galaxy-scratchbook on the top menu bar.
- You should see a little checkmark on the icon now
- View galaxy-eye a dataset by clicking on the eye icon galaxy-eye to view the output
- You should see the output in a window overlayed over Galaxy
- You can resize this window by dragging the bottom-right corner
- View galaxy-eye a second dataset from your history
- You should now see a second window with the new dataset
- This makes it easier to compare the two outputs
- Repeat this for as many files as you would like to compare
- You can turn off the Window Manager galaxy-scratchbook by clicking on the icon again
QuestionWhile the file from UCSC has labels for the columns, the peak file does not. Can you guess what the columns stand for?
This peak file is not in any standard format and just by looking at it, we cannot find out what the numbers in the different columns mean. In the paper the authors mention that they used the peak caller HPeak.
By looking at the HPeak manual we can find out that the columns contain the following information:
- chromosome name by number
- start coordinate
- end coordinate
- length
- location within the peak that has the highest hypothetical DNA fragment coverage (summit)
- not relevant
- not relevant
In order to compare the two files, we have to make sure that the chromosome names follow the same format.
As we can see, the peak file lacks chr before any chromosome number. But what happens with chromosome 20 and 21? Will it be X and Y instead? Let’s check:
Hands On: View end of file
- Search for Select last lines from a dataset (tail) ( Galaxy version 9.5+galaxy2) tool and run with the following settings:
- “Text file”: our peak file
GSE37268_mof3.out.hpeak.txt.gz- “Operation”:
Keep last lines- “Number of lines”: Choose a value, e.g.
100- Click Run Tool
- Wait for the job to finish
Inspect the file through the galaxy-eye (eye) icon (View data)
Question
- How are the chromosomes named?
- How are the chromosomes X and Y named?
- The chromosomes are just given by their number. In the gene file from UCSC, they started with
chr- The chromosomes X and Y are named 20 and 21
In order to convert the chromosome names we have therefore two things to do:
- add
chr - change 20 and 21 to X and Y
Hands On: Adjust chromosome names
- Replace Text ( Galaxy version 9.5+galaxy2) in a specific column with the following settings:
- “File to process”: our peak file
GSE37268_mof3.out.hpeak.txt.gz(warning careful! select the initial peaks file)- “in column”:
Column: 1“Find pattern”:
[0-9]+This will look for numerical digits
“Replace with”:
chr&
&is a placeholder for the find result of the pattern searchRename your output file
chr prefix added.- Replace Text ( Galaxy version 9.5+galaxy2) : Let’s rerun the tool with two more replacements
- “File to process”: the output from the last run,
chr prefix added- param-repeat Replacement
- “in column”:
Column: 1- “Find pattern”:
chr20- “Replace with”:
chrX- param-repeat Insert Replacement
- “in column”:
Column: 1- “Find pattern”:
chr21- “Replace with”:
chrY
- Expand the dataset information
- Press the galaxy-refresh icon (Run this job again)
Inspect the latest file through the galaxy-eye (eye) icon. Have we been successful?
We have quite a few files now and need to take care to select the correct ones at each step.
QuestionHow many regions are in our output file? You can click the name of the output to expand it and see the number.
It should be equal to the number of regions in your first file,
GSE37268_mof3.out.hpeak.txt.gz: 48,647 If yours says 100 regions, then you have run it on theTailfile and need to re-run the steps.- Rename the file to something more recognizable, e.g.
Peak regions
Analysis
Our goal is to compare the 2 region files (the genes file and the peak file from the publication) to know which peaks are related to which genes. If you only want to know which peaks are located inside genes (within the gene body) you can skip the next step. Otherwise, it might be reasonable to include the promoter region of the genes into the comparison, e.g. because you want to include transcriptions factors in ChIP-seq experiments. There is no strict definition for promoter region but 2kb upstream of the TSS (start of region) is commonly used. We’ll use the Get Flanks tool to get regions 2kb bases upstream of the start of the gene to 10kb bases downstream of the start (12kb in length). To do this we tell the Get Flanks tool we want regions upstream of the start, with an offset of 10kb, that are 12kb in length, as shown in the diagram below.
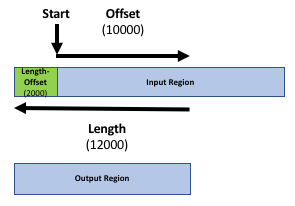
Hands On: Add promoter region to gene records
- Get Flanks ( Galaxy version 1.0.0) returns flanking region/s for every gene, with the following settings:
- “Select data”:
Genesfile from UCSC- “Region”:
Around Start- “Location of the flanking region/s”:
Upstream- “Offset”:
10000- “Length of the flanking region(s)”:
12000This tool returns flanking regions for every gene
Compare the rows of the resulting BED file with the input to find out how the start and end positions changed
Click Enable/Disable Scratchbook on the top panel
- Click on the galaxy-eye (eye) icon of the files to inspect
Click on Show/Hide Scratchbook
- Rename your dataset to reflect your findings (
Promoter regions)

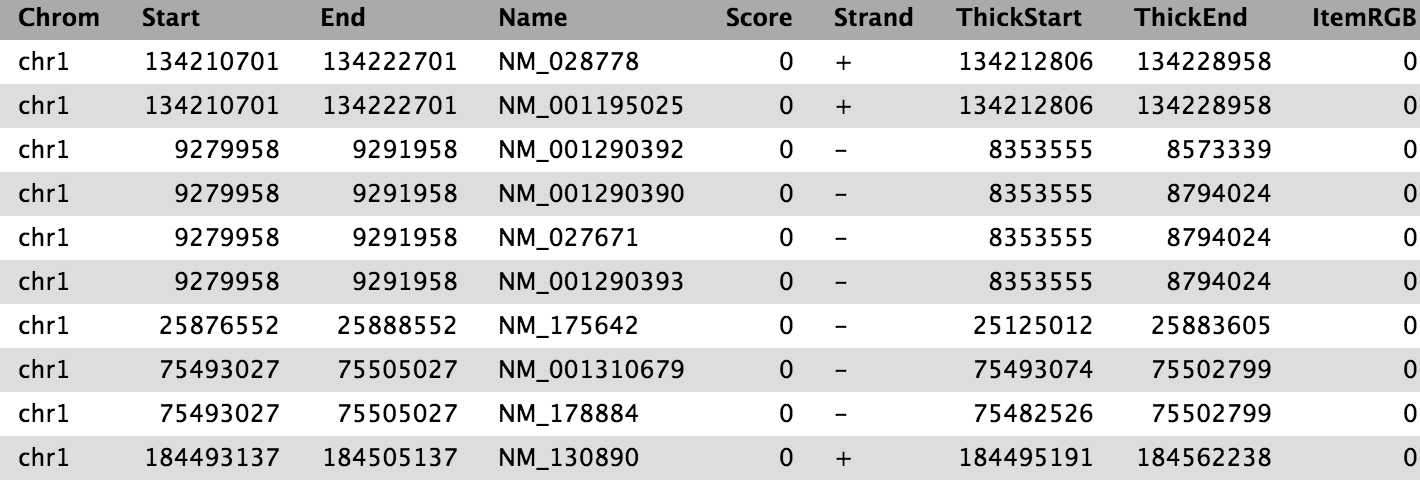
The output is regions that start from 2kb upstream of the TSS and include 10kb downstream. For input regions on the positive strand e.g. chr1 134212701 134230065 this gives chr1 134210701 134222701. For regions on the negative strand e.g. chr1 8349819 9289958 this gives chr1 9279958 9291958.
You might have noticed that the UCSC file is in BED format and has a database associated to it. That’s what we want for our peak file as well. The Intersect tool we will use can automatically convert interval files to BED format but we’ll convert our interval file explicitly here to show how this can be achieved with Galaxy.
Hands On: Change format and database
- Click on the galaxy-pencil (pencil) icon in the history entry of our peak region file
- Switch to the Datatypes tab
- In section Convert to Datatype under “Target datatype” select:
bed (using 'Convert Genomic Interval To Bed')- Press Create Dataset
- Check that the “Database/Build” is
mm9(the database build for mice used in the paper)- Again rename the file to something more recognizable, e.g.
Peak regions BED
It’s time to find the overlapping intervals (finally!). To do that, we want to extract the genes which overlap/intersect with our peaks.
Hands On: Find Overlaps
- Intersect ( Galaxy version 1.0.0) the intervals of two datasets, with the following settings:
- “Return”:
Overlapping Intervals- “of”: the UCSC file with promoter regions (
Promoter regions)- “that intersect”: our peak region file from Replace (
Peak regions BED)- “for at least”:
1CommentThe order of the inputs is important! We want to end up with a list of genes, so the corresponding dataset with the gene information needs to be the first input (
Promoter regions).
We now have the list of genes (column 4) overlapping with the peak regions, similar to shown above.
To get a better overview of the genes we obtained, we want to look at their distribution across the different chromosomes. We will group the table by chromosome and count the number of genes with peaks on each chromosome
Hands On: Count genes on different chromosomes
- Group data by a column and perform aggregate operation on other columns, with the following settings:
- “Select data”: the result of the intersection
- “Group by column”:
Column: 1- Press Insert Operation and choose:
- “Type”:
Count- “On column”:
Column: 1- “Round result to nearest integer?”:
NoQuestionWhich chromosome contained the highest number of target genes?
The result varies with different settings, for example, the annotation may change due to updates at UCSC. If you followed step by step, with the same annotation, it should be chromosome 11 with 2164 genes. Note that for reproducibility, you should keep all input data used within the analysis. Rerunning the analysis with the same set of parameters, stored Galaxy, can lead to a different result if the inputs changed e.g. the annotation from UCSC.
Visualization
We have some nice aggregated data, so why not draw a barchart of it?
Before we do that we should polish our grouped data a bit more though.
You may have noticed that the mouse chromosomes are not listed in their correct order in that dataset (the Group tool tried to sort them, but did so alphabetically).
We can fix this by running a dedicated tool for sorting on our data.
Hands On: Fix sort order of gene counts table
- Sort ( Galaxy version 9.5+galaxy2) data in ascending or descending order, with the following settings:
- “Sort Query”: result of running the Group tool
- in param-repeat “Column selections”
- “on column”:
Column: 1- “in”:
Ascending order- “Flavor”:
Natural/Version sort (-V)Sometimes there are multiple tools with very similar names. If the parameters in the tutorial don’t match with what you see in Galaxy, please try the following:
Use Tutorial Mode curriculum in Galaxy, and click on the blue tool button in the tutorial to automatically open the correct tool and version (not available for all tutorials yet)
Tools are frequently updated to new versions. Your Galaxy may have multiple versions of the same tool available. By default, you will be shown the latest version of the tool. This may NOT be the same tool used in the tutorial you are accessing. Furthermore, if you use a newer tool in one step, and try using an older tool in the next step… this may fail! To ensure you use the same tool versions of a given tutorial, use the Tutorial mode feature.
- Open your Galaxy server
- Click on the curriculum icon on the top menu, this will open the GTN inside Galaxy.
- Navigate to your tutorial
- Tool names in tutorials will be blue buttons that open the correct tool for you
- Note: this does not work for all tutorials (yet)
- You can click anywhere in the grey-ed out area outside of the tutorial box to return back to the Galaxy analytical interface
Warning: Not all browsers work!
- We’ve had some issues with Tutorial mode on Safari for Mac users.
- Try a different browser if you aren’t seeing the button.
Check that the entire tool name matches what you see in the tutorial. Please check that:
Full tool name:
Sort data in ascending or descending orderTool version:
1.1.1(written after the tool name)
Great, we are ready to plot things!
Hands On: Draw barchart
- Click on galaxy-barchart (visualize) icon on the output from the Sort tool
- Select
Bar, Line and Scatterfrom the main panel- Click on the « in the upper right corner
- Switch to the Settings tab and change the axis labels
- Choose a title below Title, e.g.
Gene counts per chromosome- Play around with the settings in the Tracks tab
When you are happy, click the cloud-upload icon to Save visualization in the top right of the main panel
This will store it to your saved visualisations. Later you can view, download, or share it with others by clicking again on Visualization on the left menu bar. In the opened menu bar click on the blue Saved Visualizations button on top. In the main panel you can find your saved plot.
Extracting workflow
When you look carefully at your history, you can see that it contains all the steps of our analysis, from the beginning to the end. By building this history we have actually built a complete record of our analysis with Galaxy preserving all parameter settings applied at every step. Wouldn’t it be nice to just convert this history into a workflow that we’ll be able to execute again and again?
Galaxy makes this very simple with the Extract Workflow option. This means that any time you want to build a workflow, you can just perform it manually once, and then convert it to a workflow, so that next time it will be a lot less work to do the same analysis. It also allows you to easily share or publish your analysis.
Hands On: Extract workflow
Clean up your history: remove any failed (red) jobs from your history by clicking on the galaxy-delete button.
This will make the creation of the workflow easier.
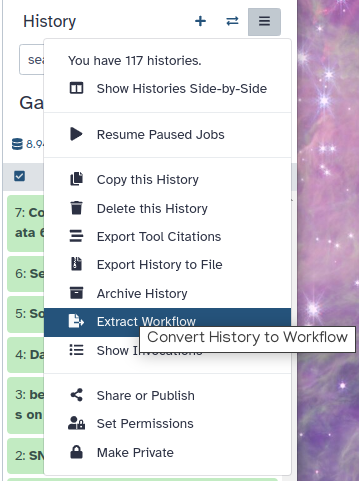
Click on galaxy-history-options (History options) at the top of your history panel and select Extract Workflow.
The central panel will show the content of the history in reverse order (oldest on top), and you will be able to choose which steps to include in the workflow.
Replace the Workflow name to something more descriptive, for example:
From peaks to genesIf there are any steps that shouldn’t be included in the workflow, you can uncheck them in the first column of boxes.
Since we did some steps which where specific to our custom peak file, we might want to exclude:
- Select last tool
- all Replace Text tool steps
- Convert Genomic Intervals to BED
- Get flanks tool
Click on the Create Workflow button near the top.
You will get a message that the workflow was created. But where did it go?
Click on Workflows in the left menu of Galaxy
Here you have a list of all your workflows
Select the newly generated workflow and click on Edit
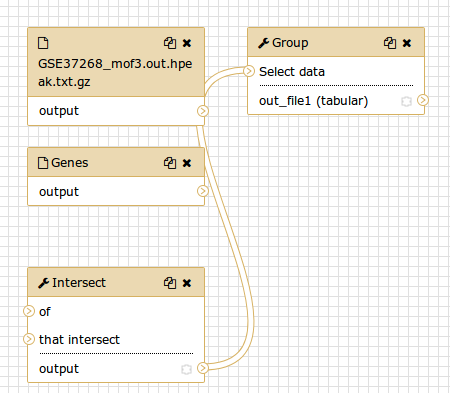
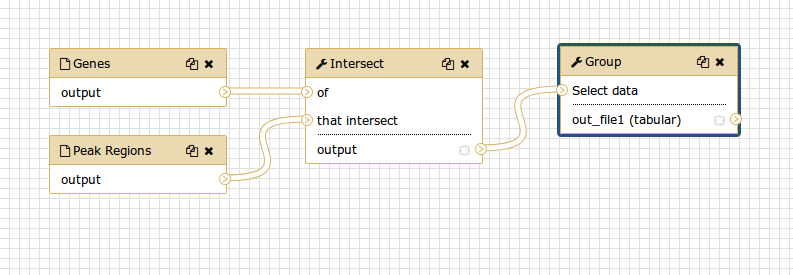
You should see something similar to this:
Comment: The workflow editorWe can examine the workflow in Galaxy’s workflow editor. Here you can view/change the parameter settings of each step, add and remove tools, and connect an output from one tool to the input of another, all in an easy and graphical manner. You can also use this editor to build workflows from scratch.
Although we have our two inputs in the workflow they are missing their connection to the first tool (Intersect tool), because we didn’t carry over some of the intermediate steps.
- Connect each input dataset to the Intersect tool tool by dragging the arrow pointing outwards on the right of its box (which denotes an output) to an arrow on the left of the Intersect box pointing inwards (which denotes an input)
- Rename the input datasets to
Reference regionsandPeak regions- Press Auto Re-layout to clean up our view
- Click on the galaxy-save Save icon (top) to save your changes
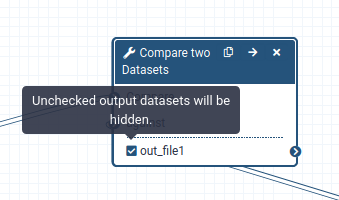
When a workflow is executed, the user is usually primarily interested in the final product and not in all intermediate steps. By default all the outputs of a workflow will be shown, but we can explicitly tell Galaxy which output to show and which to hide for a given workflow. This behaviour is controlled by the little asterisk next to every output dataset:
If you click on this asterisk for any of the output datasets, then only files with an asterisk will be shown, and all outputs without an asterisk will be hidden (Note that clicking all outputs has the same effect as clicking none of the outputs, in both cases all the datasets will be shown).
- Return to the Galaxy home page by clicking the Galaxy icon in the top-left corner of the page.
Now it’s time to reuse our workflow for a more sophisticated approach.
Part 2: More sophisticated approach
In part 1 we used an overlap definition of 1 bp (default setting) to identify genes associated with the peak regions. However, the peaks could be broad, so instead, in order to get a more meaningful definition, we could identify the genes that overlap where most of the reads are concentrated, the peak summit. We will use the information on the position of the peak summit contained in the original peak file and check for overlap of the summits with genes.
Preparation
We again need our peak file, but we’d like to work in a clean history. Instead of uploading it twice, we can copy it to a new history.
Hands On: Copy history items
Create a new history and give it a new name like
Galaxy Introduction Part 2To create a new history simply click the new-history icon at the top of the history panel:
Click on the History options galaxy-history-options at the top right of your history. Click on the Show Histories Side-by-Side
You should see both of your histories side-by-side now
- Drag and drop the edited peak file (
Peak regions, after the replace steps), which contains the summit information, to your new history.- Click on the Galaxy name in the top menu bar (top left) to go back to your analysis window
Create peak summit file
We need to generate a new BED file from the original peak file that contains the positions of the peak summits. The start of the summit is the start of the peak (column 2) plus the location within the peak that has the highest hypothetical DNA fragment coverage (column 5, rounded down to the next smallest integer because some peak summits fall in between to bases). As the end of the peak region, we will simply define start + 1.
Hands On: Create peak summit file
- Compute on rows ( Galaxy version 2.1) with the following parameters:
- “Input file”: our peak file
Peak regions(the interval format file)- *“Input has a header line with column names?”:
No- In “Expressions”:
- param-repeat “Expressions”
- “Add expression”:
c2 + int(c5)- “Mode of the operation”: Append
- param-repeat “Expressions”
- “Add expression”:
c8 + 1- “Mode of the operation”: Append
This will create an 8th and a 9th column in our table, which we will use in our next step:
- Rename the output
Peak summit regions
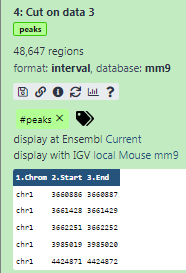
Now we cut out just the chromosome plus the start and end of the summit:
Hands On: Cut out columns
- Cut columns from a table with the following settings:
- “Cut columns”:
c1,c8,c9- “Delimited by Tab”:
Tab- “From”:
Peak summit regionsThe output from Cut will be in
tabularformat.Change the format to
interval(use the galaxy-pencil) since that’s what the tool Intersect expects.
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select
intervalfrom “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button
The output should look like below:
Get gene names
The RefSeq genes we downloaded from UCSC did only contain the RefSeq identifiers, but not the gene names. To get a list of gene names in the end, we use another BED file from the Data Libraries.
CommentThere are several ways to get the gene names in, if you need to do it yourself. One way is to retrieve a mapping through Biomart and then join the two files (Join two Datasets side by side on a specified field tool). Another is to get the full RefSeq table from UCSC and manually convert it to BED format.
Hands On: Data upload
Import
mm9.RefSeq_genes_from_UCSC.bedfrom Zenodo or from the data library:https://zenodo.org/record/1025586/files/mm9.RefSeq_genes_from_UCSC.bed
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Change Genome to
mm9Press Start
- Close the window
As an alternative to uploading the data from a URL or your computer, the files may also have been made available from a shared data library:
- Go into Libraries (left panel)
Navigate to : Click on “GTN - Material”, “Introduction to Galaxy Analyses”, “From peaks to genes”, and then “DOI: 10.5281/zenodo.1025586” or the correct folder as indicated by your instructor.
- Select the desired files
- Click on Add to History galaxy-dropdown near the top and select as Datasets from the dropdown menu
In the pop-up window, choose
- “Select history”: the history you want to import the data to (or create a new one)
- Click on Import
As default, Galaxy takes the link as name, so rename them.
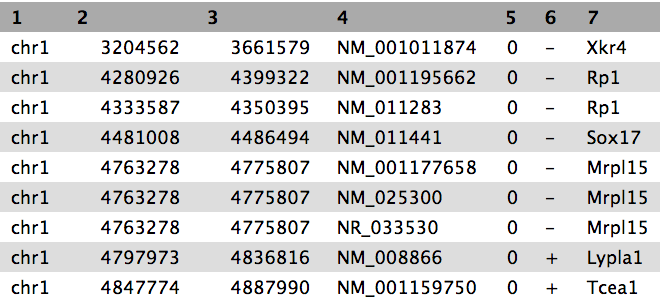
Inspect the file content to check if it contains gene names. It should look similar to below:
- Rename it
mm9.RefSeq_genes- Apply the tag
#genes
Repeat workflow
It’s time to reuse the workflow we created earlier.
Hands On: Run a workflow
- Open the Workflows menu (left menu bar)
- Find the workflow you made in the previous section, and select the option Run workflow-run
- Choose as inputs our
mm9.RefSeq_genes(#genes) BED file and the result of the Cut tool (#peaks)Click Run workflow
The outputs should appear in the history but it might take some time until they are finished.
We used our workflow to rerun our analysis with the peak summits. The Group tool again produced a list containing the number of genes found in each chromosome. But wouldn’t it be more interesting to know the number of peaks in each unique gene? Let’s rerun the workflow with different settings!
Hands On: Run a workflow with changed settings
- Open the workflow menu (left menu bar)
- Find the workflow you made in the previous section, and select the option Run
- Click on Workflow run settings galaxy-wf-options and then on Expanded workflow form
- Choose as inputs our
mm9.RefSeq_genes(#genes) BED file and the result of the Cut tool (#peaks)- Click on the title of the tool Group tool to expand the options
- Change the following settings by clicking on the galaxy-pencil (pencil) icon on the left:
- “Group by column”:
7- In “Operation”:
- “On column”:
7- Click Run workflow
Congratulations! You should have a file with all the unique gene names and a count on how many peaks they contained.
QuestionWhich gene has the most number of peaks?
Kcnma1
The list of unique genes is not sorted or you workflow included a sorting step but for the gene names. Try to sort it on your own! You can use the tool “ Sort ( Galaxy version 9.5+galaxy2) data in ascending or descending order” or rerun to sort tool of your workflow. Sort on colum
Column: 2inDescending orderwithFast numeric sort (-n)flavor.
Share your work
One of the most important features of Galaxy comes at the end of an analysis. When you have published striking findings, it is important that other researchers are able to reproduce your in-silico experiment. Galaxy enables users to easily share their workflows and histories with others.
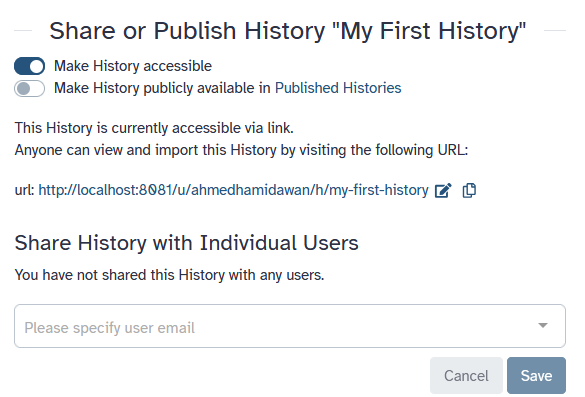
To share a history, click on the galaxy-history-options history options and select Share & Manage Access. On this tab (Share or Publish) you can Make History accessible or Share History with Individual Users:
-
Make History accessible
This generates a link that you can give out to others. Anybody with this link will be able to view your history.
-
Make History publicly available
This will not only create a link, but will also publish your history. This means your history will be listed under
Histories → Published Historiesin the left menu and other users can access the history there. -
Share with Individual Users
This will share the history only with specific users on the Galaxy instance.
- Share one of your histories with your neighbour
- See if you can do the same with your workflow!
Find the history and/or workflow shared by your neighbour
Histories shared with specific users can be accessed by those users under
Histories → Shared with Me.
Conclusion
trophy You have just performed your first analysis in Galaxy. You also created a workflow from your analysis so you can easily repeat the exact same analysis on other datasets. Additionally you shared your results and methods with others.
You've finished the tutorial
Key points
Galaxy provides an easy-to-use graphical user interface for often complex commandline tools
Galaxy keeps a full record of your analysis in a history
Workflows enable you to repeat your analysis on different data
Galaxy can connect to external sources for data import and visualization purposes
Galaxy provides ways to share your results and methods with others
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsReferences
- Li, X., L. Li, R. Pandey, J. S. Byun, K. Gardner et al., 2012 The Histone Acetyltransferase MOF Is a Key Regulator of the Embryonic Stem Cell Core Transcriptional Network. Cell Stem Cell 11: 163–178. 10.1016/j.stem.2012.04.023
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Anne Pajon, Clemens Blank, Bérénice Batut, Björn Grüning, Nicola Soranzo, Dilmurat Yusuf, Sarah Peter, Helena Rasche, From peaks to genes (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/introduction/tutorials/galaxy-intro-peaks2genes/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{introduction-galaxy-intro-peaks2genes, author = "Anne Pajon and Clemens Blank and Bérénice Batut and Björn Grüning and Nicola Soranzo and Dilmurat Yusuf and Sarah Peter and Helena Rasche", title = "From peaks to genes (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/introduction/tutorials/galaxy-intro-peaks2genes/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
References
These individuals or organisations provided funding support for the development of this resource
Congratulations on successfully completing this tutorial!

You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/introduction/tutorials/galaxy-intro-peaks2genes/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: text_processing owner: bgruening revisions: d698c222f354 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: c41d78ae5fee tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: c41d78ae5fee tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: d698c222f354 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: c41d78ae5fee tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: column_maker owner: devteam revisions: aff5135563c6 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: get_flanks owner: devteam revisions: 077f404ae1bb tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: intersect owner: devteam revisions: 69c10b56f46d tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/