EncyclopeDIA
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How to perform quantitative analysis using DIA data with the help of EncyclopeDIA?
How to perform quantitation with or without Chromatogram Libraries?
Requirements:
Understand the difference between DDA and DIA methods
Performing quantitative analysis using DIA data
Understand the purpose and benefits of using a Chromatogram Library for the detection of peptides
You can use Bloom’s Taxonomy to write effective learning objectives
Time estimation: 6 hoursSupporting Materials:Published: Jun 21, 2021Last modification: May 19, 2025License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00215version Revision: 12
Data Independent Acquisition (DIA) was introduced as a method to provide reproducible quantitative information as an improvement over the Data Dependent Acquisition (DDA) Gillet et al. 2012. Despite the benefits of DIA, such as increased depth of coverage and lesser missing values, the computational analysis of the complicated and multiplexed data presents challenges. Therefore, with the rise of usage of this technique, rises a need for new and robust methods of data analysis.
The EncyclopeDIA Searle et al. 2020 workflow described in this tutorial contains three steps. The first step is the conversion of the input data files from RAW file types to mzML file-type using the tool msconvert. The second step which is a critical component of this workflow is the generation of a Chromatogram Library. Chromatogram Library is generated by employing the gas-phase fractionation (GPF) method and can make use of DDA-generated or predicted spectral libraries. Lastly, the experimental wide-window DIA files are analyzed using the EncyclopeDIA software tool generated by Brian Searle. EncyclopeDIA analysis of experimental DIA data against the generated Chromatogram Library and the background proteome FASTA file generates peptide and protein quantitation outputs. The availability of EncyclopeDIA workflow within the Galaxy platform offers another easier way of analyzing DIA data.
An Overview of the EncyclopeDIA Standard Workflow
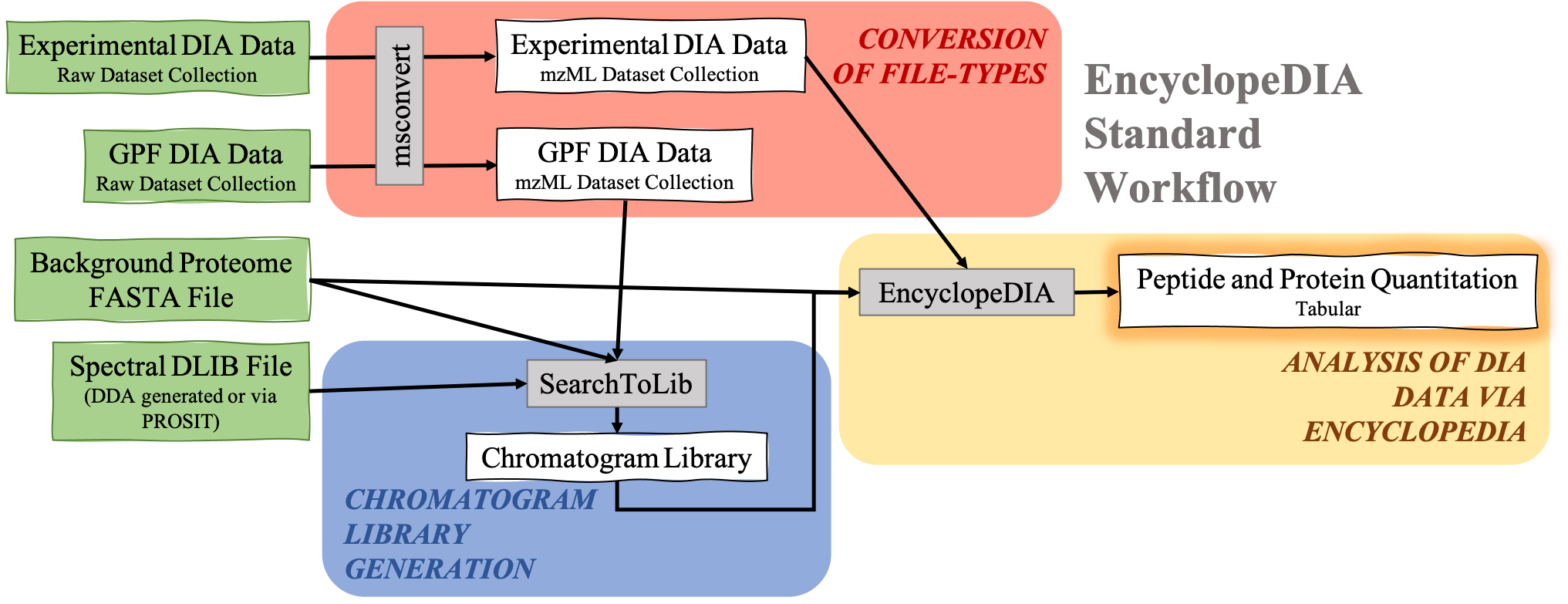 Open image in new tab
Open image in new tabAbout the data: In this tutorial, we will be analyzing the dataset provided by the iPRG (Proteome Informatics Research Group).
AgendaIn this tutorial, we will cover:
DDA, DIA, and their differences
Data Independent Acquisition (DIA) Mass Spectrometry is a promising alternative to Data Dependent Acquisition (DDA) Mass Spectrometry for protein quantitation.
In the DDA-MS method, the instrument selects specific precursor ions for fragmentation based on their measured abundance in MS1 (Figure 1). Once selected, MS2 data is collected for these m/z time points and used to determine the sequences of the peptides that are present. Additionally, when integrated with the information given with the precursor peak, the quantity of peptide can be calculated.
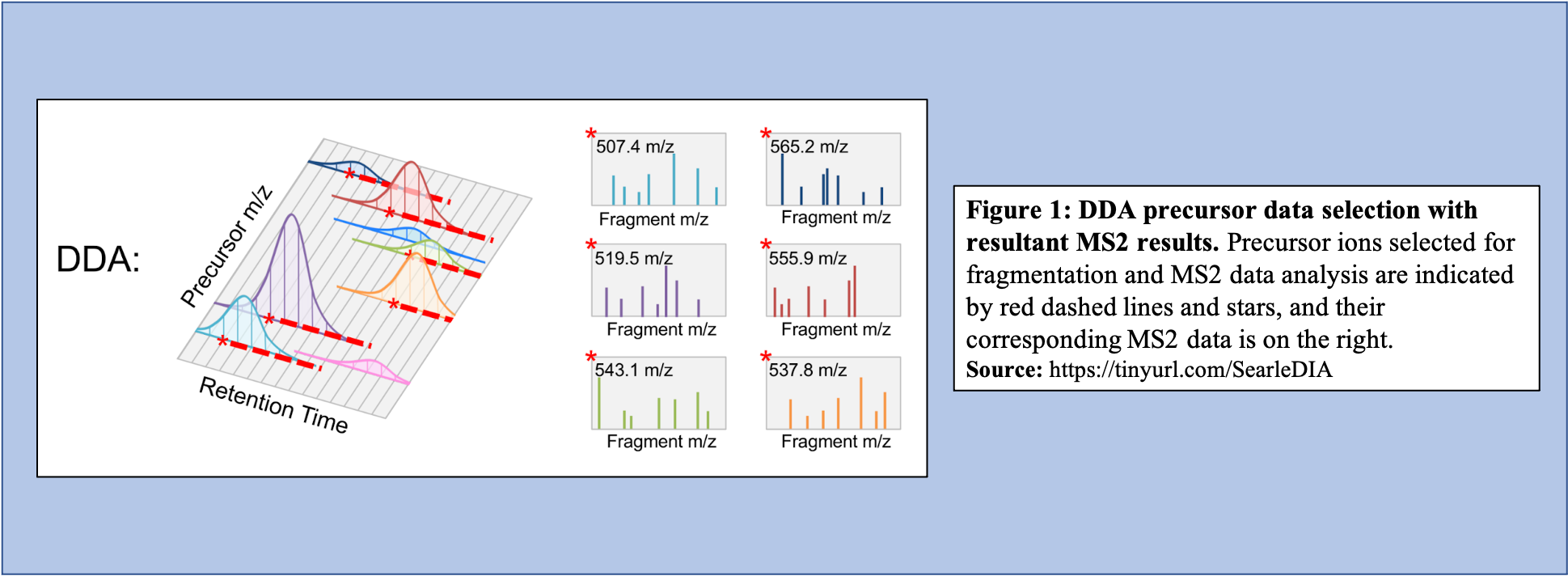 Open image in new tab
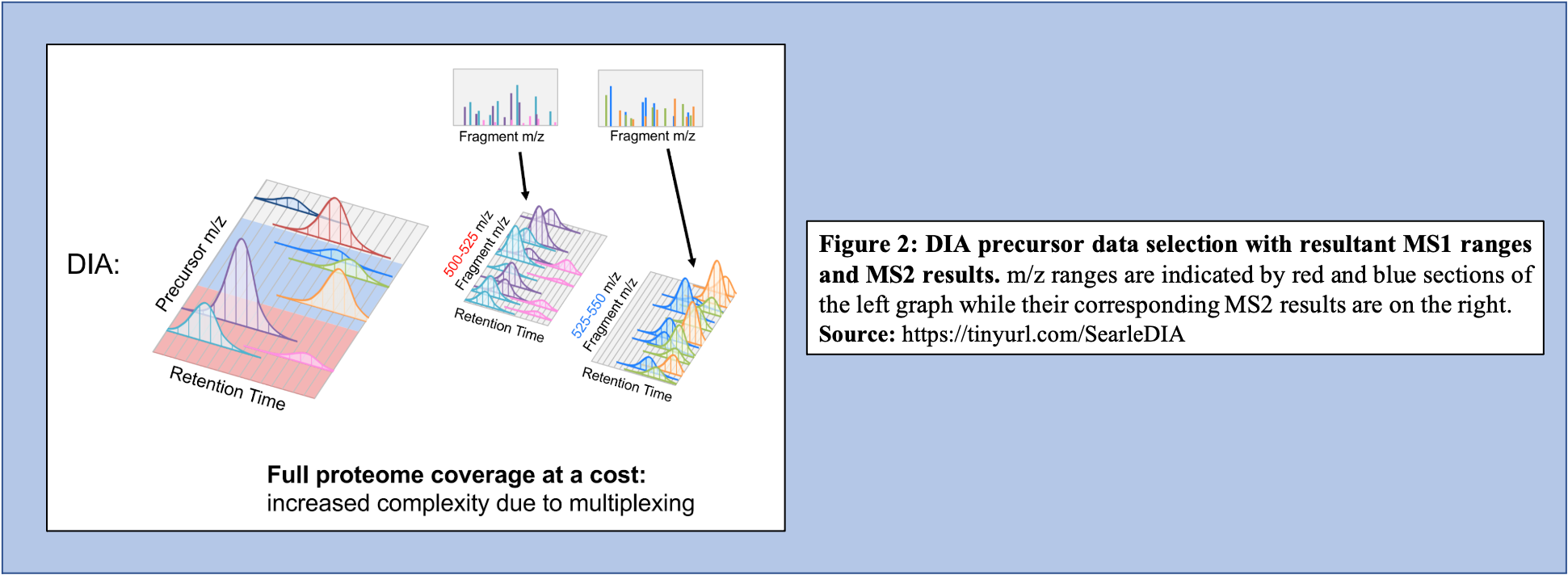
Open image in new tabOn the other hand, in the DIA-MS method, the mass spectrometer fragments analytes within a specified m/z range (Figure 2). The MS2 data contribute to analyte identification and provide relative quantification. Compared to DDA which selects for a specific time point corresponding to a specific peptide, DIA scans across a time range resulting in multiplexed and complex MS2 data containing peak information from multiple peptides.
 Open image in new tab
Open image in new tabWhat does a typical DIA experiment look like?
In a typical DIA-MS experiment, the precursor scan usually ranges between 400-1000 m/z as opposed to 400-1600 m/z typically associated with DDA experiments. Multiple precursor scans are selected, each containing several fragment scans spanning across the entire 400-1000 m/z range (Figure 3A). Specific corresponding fragment ion scans can then be condensed and each combined fragment ion scan containing a small m/z range and its peaks can be examined and its peptide content can then be analyzed (Figure 3B).
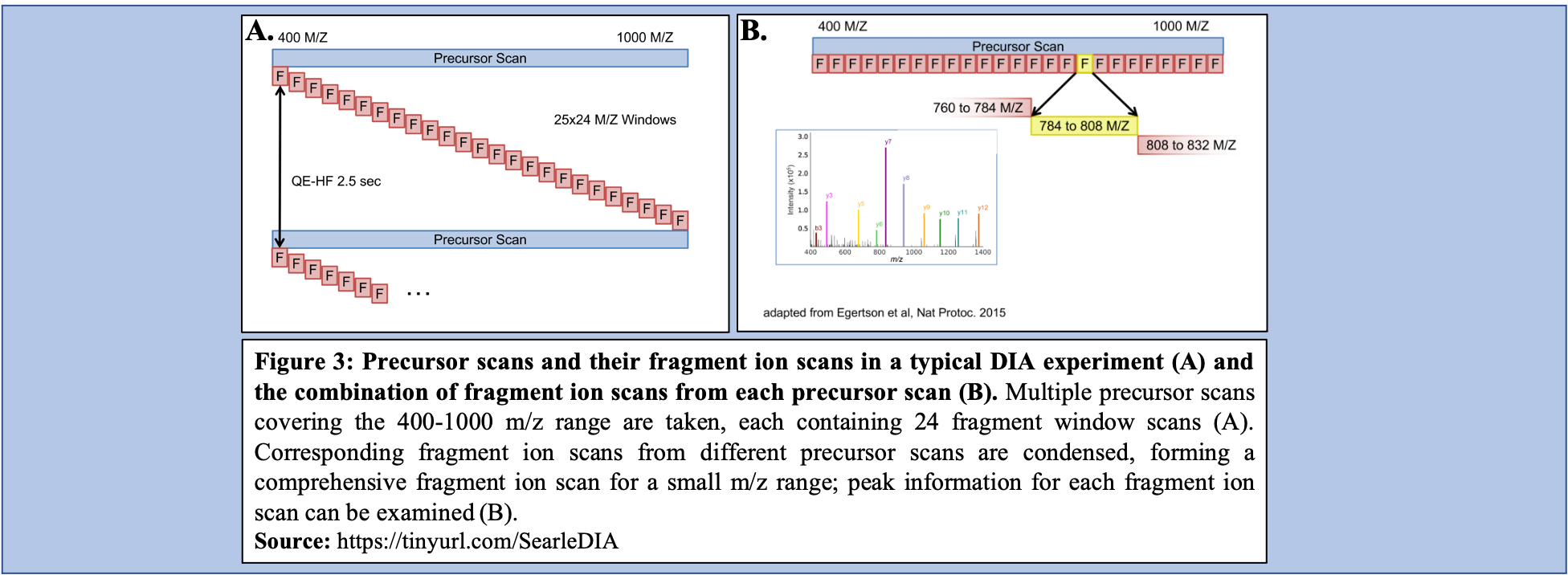 Open image in new tab
Open image in new tabAn advantage of DIA-MS compared to DDA-MS is that it is possible to obtain a better coverage of the proteome. Since DDA-MS focuses on the selection of precursor ions with significant abundance, data for less abundant (but perhaps equally interesting or important) peptides is not acquired. Therefore, DIA-MS, which fragments ions based on a mass range and not abundance, can provide a more comprehensive proteome coverage within a sample. DIA-MS relies on quantitation via fragment MS ions as compared to precursor ion MS and hence avoids the issue of quantitative interference due to co-eluting peptides associated with the DDA-MS methods. Finally, since DIA-MS is not dependent on the precursor intensity, MS2 signals can be used for quantitative analysis of low-abundance peptides and proteins. For a more detailed description of DIA and its applications and advantages, we recommend users to watch two presentations by Brian Searle available on YouTube Introduction to DIA and DIA tips.
Import data
Hands On: Data upload
- Create a new history for this tutorial
Import the files from Zenodo or from the shared data library (
GTN - Material->proteomics->EncyclopeDIA):https://zenodo.org/records/13505774/files/191023JAT03_1_Mix_2_1ug_pOT_30k_390_1010_12_20.raw https://zenodo.org/records/13505774/files/191023JAT10_2_Mix_4_1ug_pOT_30k_390_1010_12_20.raw https://zenodo.org/records/13505774/files/191023JAT11_3_Mix_1_1ug_pOT_30k_390_1010_12_20.raw https://zenodo.org/records/13505774/files/191023JAT12_4_Mix_3_1ug_pOT_30k_390_1010_12_20.raw https://zenodo.org/records/13505774/files/191023JAT04_P_1ug_395_505_4_20.raw https://zenodo.org/records/13505774/files/191023JAT05_P_1ug_495_605_4_20.raw https://zenodo.org/records/13505774/files/191023JAT06_P_1ug_595_705_4_20.raw https://zenodo.org/records/13505774/files/191023JAT07_P_1ug_695_805_4_20.raw https://zenodo.org/records/13505774/files/191023JAT08_P_1ug_795_905_4_20.raw https://zenodo.org/records/13505774/files/191023JAT09_P_1ug_895_1005_4_20.raw https://zenodo.org/record/4926594/files/T4_Salmonella_Ecoli_Bacillus_BS_191102.fasta https://zenodo.org/record/4926594/files/T4_Salmonella_Ecoli_Bacillus_fasta_trypsin_z2_nce33_BS_191102.dlib
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window
As an alternative to uploading the data from a URL or your computer, the files may also have been made available from a shared data library:
- Go into Libraries (left panel)
- Navigate to the correct folder as indicated by your instructor.
- On most Galaxies tutorial data will be provided in a folder named GTN - Material –> Topic Name -> Tutorial Name.
- Select the desired files
- Click on Add to History galaxy-dropdown near the top and select as Datasets from the dropdown menu
In the pop-up window, choose
- “Select history”: the history you want to import the data to (or create a new one)
- Click on Import
For all the datasets that you have just uploaded, please rename them if “%20” is seen.
- Check that the datatype
- For the FASTA file, the datatype should be set as
fasta- For the Library files, the datatype should be set as
dlib- For the Raw files, the datatype should be set as
thermo.raw
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select
thermo.rawfrom “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button
- Add to each dataset a tag corresponding to file type, i.e.
- GPF datasets (files containing - 395, 495, 595, 695, 795, and 895) can be labeled as
#gpf- Experimental DIA datasets (Mix 1-4) label as
#experimentalDatasets can be tagged. This simplifies the tracking of datasets across the Galaxy interface. Tags can contain any combination of letters or numbers but cannot contain spaces.
To tag a dataset:
- Click on the dataset to expand it
- Click on Add Tags galaxy-tags
- Add tag text. Tags starting with
#will be automatically propagated to the outputs of tools using this dataset (see below).- Press Enter
- Check that the tag appears below the dataset name
Tags beginning with
#are special!They are called Name tags. The unique feature of these tags is that they propagate: if a dataset is labelled with a name tag, all derivatives (children) of this dataset will automatically inherit this tag (see below). The figure below explains why this is so useful. Consider the following analysis (numbers in parenthesis correspond to dataset numbers in the figure below):
- a set of forward and reverse reads (datasets 1 and 2) is mapped against a reference using Bowtie2 generating dataset 3;
- dataset 3 is used to calculate read coverage using BedTools Genome Coverage separately for
+and-strands. This generates two datasets (4 and 5 for plus and minus, respectively);- datasets 4 and 5 are used as inputs to Macs2 broadCall datasets generating datasets 6 and 8;
- datasets 6 and 8 are intersected with coordinates of genes (dataset 9) using BedTools Intersect generating datasets 10 and 11.
Now consider that this analysis is done without name tags. This is shown on the left side of the figure. It is hard to trace which datasets contain “plus” data versus “minus” data. For example, does dataset 10 contain “plus” data or “minus” data? Probably “minus” but are you sure? In the case of a small history like the one shown here, it is possible to trace this manually but as the size of a history grows it will become very challenging.
The right side of the figure shows exactly the same analysis, but using name tags. When the analysis was conducted datasets 4 and 5 were tagged with
#plusand#minus, respectively. When they were used as inputs to Macs2 resulting datasets 6 and 8 automatically inherited them and so on… As a result it is straightforward to trace both branches (plus and minus) of this analysis.More information is in a dedicated #nametag tutorial.
- Please create a dataset collection for both the GPF files and the Experimental Design files.
- Name the dataset collections as “GPF collection” and “Experimental Design collection”
- Click on galaxy-selector Select Items at the top of the history panel
- Check all the datasets in your history you would like to include
Click n of N selected and choose Advanced Build List
You are in collection building wizard. Choose Flat List and click ‘Next’ button at the right bottom corner.
Double clcik on the file names to edit. For example, remove file extensions or common prefix/suffixes to cleanup the names.
- Enter a name for your collection
- Click Build to build your collection
- Click on the checkmark icon at the top of your history again


Conversion of file types
msconvert is the first tool in this EncyclopeDIA workflow as before analysis of DIA data may begin, the data files (.RAW format) must be converted to the correct file type (mzML) from the MS/MS data. Conversion from .raw to .mzML is important because the SearchToLib tool (responsible for generation of the Chromatogram Library), as well as the EncyclopeDIA tool (responsible for analysis of DIA data), require mzmL inputs. As msconvert exists on the Galaxy platform, conversion of files to the necessary type is straightforward and can be incorporated into the workflow itself as opposed to a separate precursor. Both the GPF DIA raw data and the Experimental DIA raw data are run through msconvert for conversion to mzML for the following steps, creation of the Chromatogram Library and analysis of DIA data through EncyclopeDIA.
In this workflow, msconvert uses dataset collections. The tool will convert each of the data files in the collection from a raw file type to a mzML file type. Then, a dataset collection containing the mzML files will be generated as the output from msconvert. msconvert will run twice, as both the GPF raw DIA data as well as the Experimental DIA raw data need to be converted to mzML file type. Therefore, two outputs will be generated:
-
GPF mzML DIA dataset collection
This output will serve as an input for SearchToLib in generating the Chromatogram Library.
-
Experimental mzML DIA dataset collection
This output will be the DIA data analyzed with EncyclopeDIA.
Hands On: Conversion of GPF DIA mass spectrometry raw data to mzML data-type.
- msconvert Convert and/or filter mass spectrometry files ( Galaxy version 3.0.20287.6) with the following parameters:
- param-collection “Input unrefined MS data”:
GPF collection(Input dataset collection)- “Do you agree to the vendor licenses?”:
Yes- “Output Type”:
mzML- In “Data Processing Filters”:
- “Apply peak picking?”:
Yes- “Apply m/z refinement with identification data?”:
No- “(Re-)calculate charge states?”:
no- “Filter m/z Window”:
Yes- “Filter out ETD precursor peaks?”:
Yes- “De-noise MS2 with moving window filter”:
Yes- “Demultiplex overlapping or MSX spectra”:
Yes- In “Scan Inclusion/Exclusion Filters”:
- “Filter MS Levels”:
Yes- In “General Options”:
- “Sum adjacent scans”:
Yes- “Output multiple runs per file”:
YesCommentSearchToLib uses the mzML dataset collection from this step as its input, making this step vital for the function of the workflow.
Question
- Why is conversion from raw to mzML necessary?
- Can you use any other tool for conversion?
- SearchToLib and EncyclopeDIA require mzML file inputs. Failing to convert the experimental DIA data and the GPF DIA data from raw files would mean that SearchToLib and EncyclopeDIA would not run successfully.
- msconvert is specifically used in this workflow as it specializes in conversion of mass spectrometry data, and can therefore be applied to the DIA data that requires conversion to be analyzed in this workflow. However, there is an option to convert from raw to mzML using a command line-based tool.
Hands On: Conversion of Experimental DIA mass spectrometry raw data to mzML data-type.
- msconvert Convert and/or filter mass spectrometry files ( Galaxy version 3.0.20287.6) with the following parameters:
- param-collection “Input unrefined MS data”:
Experimental Design collection(Input dataset collection)- “Do you agree to the vendor licenses?”:
Yes- “Output Type”:
mzML- In “Data Processing Filters”:
- “Apply peak picking?”:
Yes- “Apply m/z refinement with identification data?”:
No- “(Re-)calculate charge states?”:
no- “Filter m/z Window”:
Yes- “Filter out ETD precursor peaks?”:
Yes- “De-noise MS2 with moving window filter”:
Yes- “Demultiplex overlapping or MSX spectra”:
Yes- In “Scan Inclusion/Exclusion Filters”:
- “Filter MS Levels”:
Yes- In “General Options”:
- “Sum adjacent scans”:
Yes- “Output multiple runs per file”:
YesCommentFor the analysis of the Experimental DIA data via EncyclopeDIA to proceed, the raw dataset collection must be converted to mzML which makes this a critical step in the function of this workflow. Additionally, as DIA uses overlapping windows and fragments (Figure 3B), deconvolution of the data is vital to analyze it correctly in the removal of repeated data. Conversion from raw to mzML allows for this deconvolution to occur within the workflow as part of the data’s conversion.
Chromatogram Library Generation
Libraries used in DIA data analysis are often constructed from DDA data assuming that DDA data is a reasonable substitute or reasonable representation of DIA data, which is not always the case Pino et al. 2020. However, researchers began postulating that libraries could be generated using DIA data, and formed methods of generating DIA data libraries as well as libraries generated through other methods.
As mentioned, there are challenges associated with the use of DDA libraries to analyze DIA data. The main challenge is that the difference in the method of data generation causes inconvenient variance between the DDA library and the DIA data to be analyzed, making accurate investigation of data difficult. One significant difference that arises between DDA libraries and DIA data is retention time. Dependent on how the protein elutes off the column as well as changes caused by coelution in the environment, retention time varies between DDA and DIA methods. Additionally, DDA libraries can be cumbersome to generate when examining DIA data due to differences in methods of fractionation. For example, SCX fractionation provides a vastly different profile compared to high pH reverse phase fractionation. Thus, to generate a comprehensive profile with a DDA library, multiple fractionation methods must be completed. So, while DDA libraries can be used to analyze DIA data, their use significantly increases the required labor and the quantity of data required to generate a library.
Libraries generated using DIA data can bypass several issues, including lowering the overall labor required to produce the library, as well as increasing the accuracy of the library concerning the sample that is being analyzed. To generate libraries using DIA data, Gas Phase Fractionation (GPF) is used. In DDA library generation, typically one injection is performed over the precursor scan, with multiple (24) ion fraction windows contained over the scan. However, using GPF, multiple acquisitions are used for each precursor scan to make up the range of 400-1000 m/z. For example, if six injections are performed over this m/z range, each containing the same number of windows as that of the injection in DDA library generation, then each window will be far smaller (Figure 4).
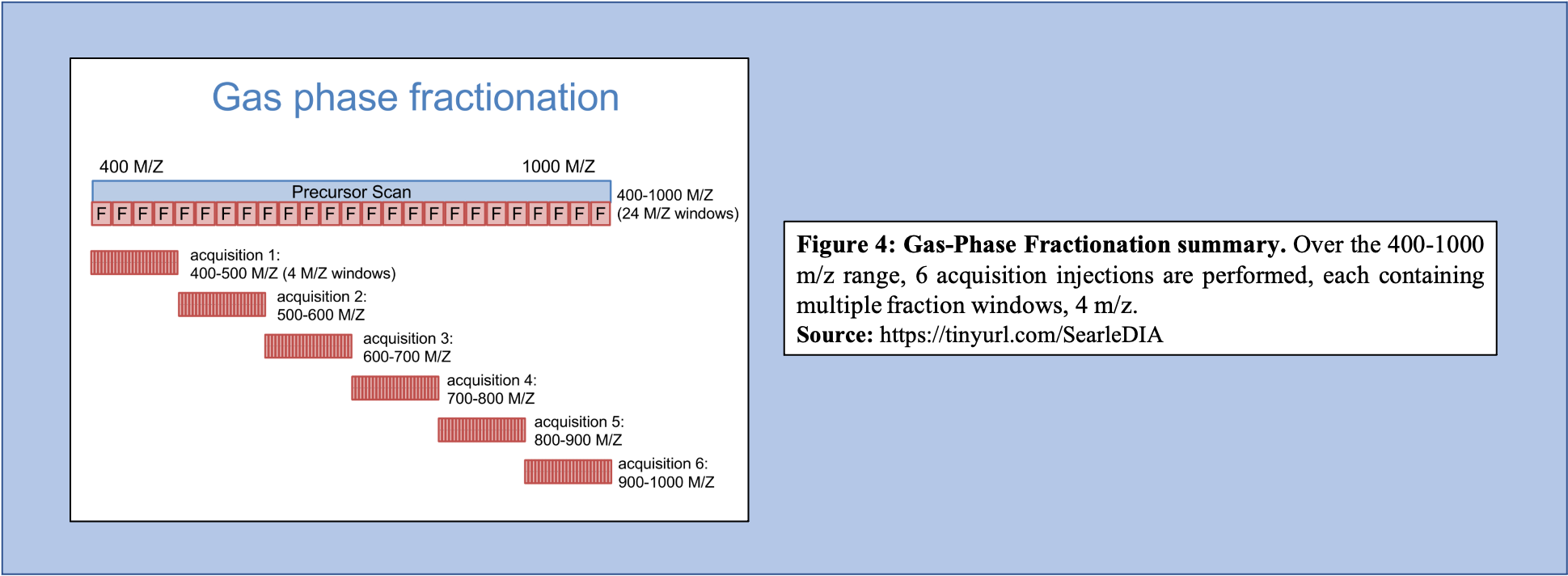 Open image in new tab
Open image in new tabAs shown in Figure 4, GPF and its multiple injections allow for a far richer and more in-depth understanding of the peptide content within the sample making it a useful tool in library generation. In addition to producing a more comprehensive picture of the sample, the GPF method can be used on pooled DIA quantitative samples (Figure 5). Therefore, the pooled sample generates a thorough library through GPF while incorporating a spectrum library to create an “On-column Chromatogram Library” from DIA sample data.
 Open image in new tab
Open image in new tabSearchToLib is the tool responsible for the generation of the Chromatogram Library in this EncyclopeDIA workflow. A library is generated using the GPF DIA dataset collection converted previously, a background proteome FASTA file, as well as a DLIB Spectral Library. Outputs from this tool include the Chromatogram Library in ELIB format, as well as a text log file.
Hands On: Building a Chromatogram Library with DIA MS/MS data.
- SearchToLib Build a Chromatogram Library from Data-Independent Acquisition (DIA) MS/MS Data ( Galaxy version 1.12.34) with the following parameters:
- param-file “Spectrum files in mzML format”:
output(output of msconvert tool)- param-file “Library: Chromatagram .ELIB or Spectrum .DLIB”:
output(Input dataset)- param-file “Background proteome protein fasta database”:
output(Input dataset)- In “Parameter Settings”:
- “Set Acquisition Options”:
No - use default options- “Set Tolerance Options”:
No - use default options- “Set Percolator Options”:
No - use default options- “Set Peak Options”:
No - use default options- “Set Window Options”:
No - use default options- “Set Modifications Options”:
No - use default options- “Set Search Options”:
No - use default optionsCommentChromatogram Library generation using SearchToLib is the step that takes the most time in this workflow. With larger datasets, more time is required to generate the Chromatogram Library and SearchToLib may take up to several days to complete.
Question
- What are the benefits to using Chromatogram Libraries compared to DDA-generated libraries?
- How does the EncyclopeDIA workflow change change in the absence of a spectral DLIB library?
- The benefit of using Chromatogram Libraries compared to DDA-generated libraries is largely found in the method of data acquisition. Because Chromatogram Libraries use pooled DIA sample data and use GPF to generate fractions, Chromatogram Libraries are found to be both very comprehensive, as well as very relevant libraries to the experimental samples that are to be analyzed. As Chromatogram Libraries take the form of an ELIB file-type, they contain additional information on retention times, peak intensities, and more compared to their DLIB DDA-generated library counterparts. Furthermore, this method also avoids the extra labor associated with performing DDA for just library generation to analyze DIA samples.
- The EncyclopeDIA Walnut workflow, a variation of the Standard EncyclopeDIA workflow (described in this tutorial), can be run in the absence of a spectral DLIB library. The step in the workflow that is most affected by the absence of the spectral DLIB library is Chromatogram Library generation using SearchToLib. The EncyclopeDIA WALNUT workflow and the changed SearchToLib step are described below.
In this Standard EncyclopeDIA workflow, SearchToLib requires three inputs:
GPF DIA MS/MS data in mzML file-type This file is required for the generation of the Chromatogram Library
Spectral Library in DLIB file type (DDA or PROSIT generated)
This Spectral Library (generated either from DDA data or via PROSIT) is incorporated in Chromatogram Library generation to build a more complete library with which to analyze the Experimental DIA data.
- Background Proteome FASTA file
In generating the Chromatogram Library, a Background Proteome FASTA file is searched against to provide context for the experiment, as this file will contain information on all proteins that could be in the sample of interest.
SearchToLib generates two output files:
- Log txt file
This file is not visualized in the workflow output as it contains the progress of the workings of SearchToLib.
- Chromatogram Library in ELIB format
As the Chromatogram Library is generated using an ELIB format, it contains additional quantification data on retention time, peak intensity, and m/z ratios compared to DDA library files, typically generated using a DLIB format. This file will serve as the Chromatogram Library ELIB File input when running EncyclopeDIA.
Analysis of DIA data with EncyclopeDIA Without DLIB Spectral Library
DIA data analysis with EncyclopeDIA is still possible without a Spectral library. Although a Spectral library is a required input for SearchToLib in the Standard EncyclopeDIA workflow, WALNUT (another form of the EncyclopeDIA workflow) can be used. When using the WALNUT workflow, the Background Proteome FASTA file is important, as this will be the primary file SearchToLib will search against in formation of the Chromatogram Library. Otherwise, the WALNUT EncyclopeDIA workflow works similarly to the Standard EncyclopeDIA workflow:
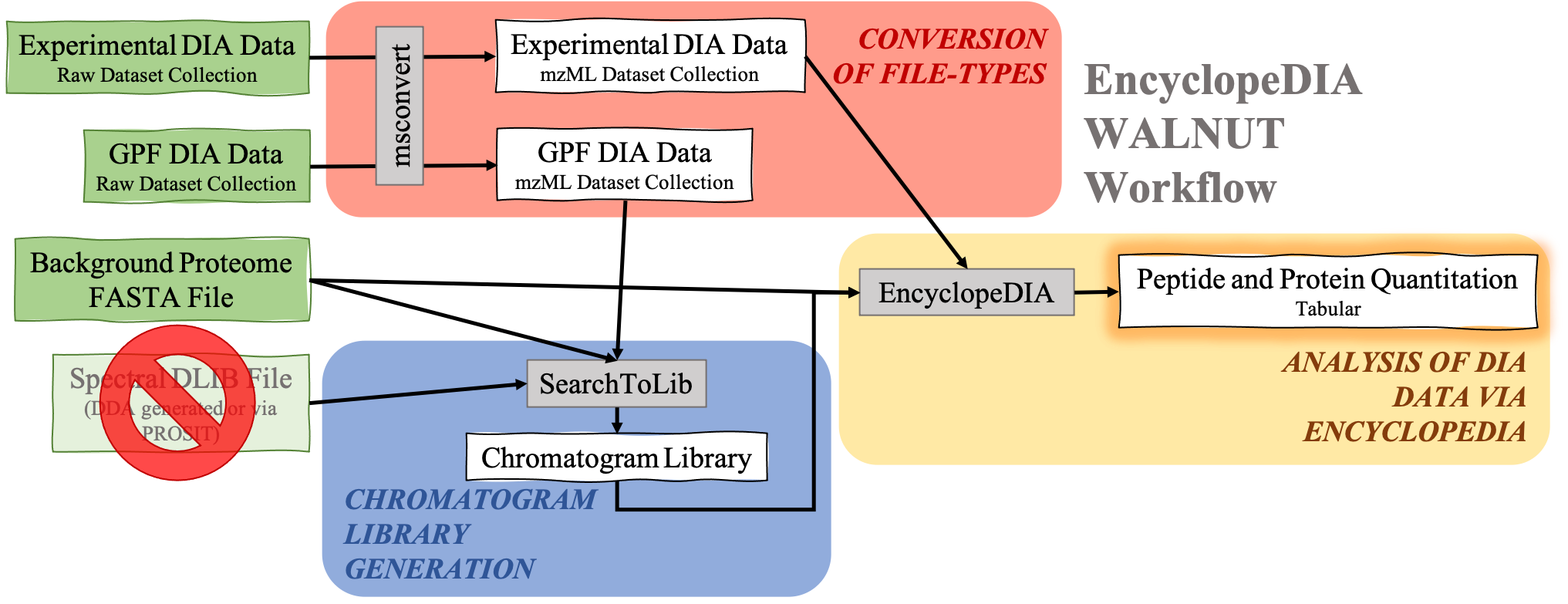 Open image in new tab
Open image in new tabHands On: Chromatogram Library generation using WALNUT variation.
- SearchToLib Build a Chromatogram Library from Data-Independent Acquisition (DIA) MS/MS Data ( Galaxy version 1.12.34) with the following parameters:
- param-file “Spectrum files in mzML format”:
output(output of msconvert tool)- param-file “Library: Chromatagram .ELIB or Spectrum .DLIB”:
Nothing selected- param-file “Background proteome protein fasta database”:
output(Input dataset)- In “Parameter Settings”:
- “Set Acquisition Options”:
No - use default options- “Set Tolerance Options”:
No - use default options- “Set Percolator Options”:
No - use default options- “Set Peak Options”:
No - use default options- “Set Window Options”:
No - use default options- “Set Modifications Options”:
No - use default options- “Set Search Options”:
No - use default optionsCommentThe biggest change between the WALNUT and the Standard EncyclopeDIA workflows is found in Chromatogram Library generation using SearchToLib.
However, there are situations in which DIA data is analyzed without the use of DIA data-generated libraries (Chromatogram Libraries) or DDA libraries. There are a few different methods and tools that can be used in cases where neither a Chromatogram library nor a DDA library can be generated.
Predicted libraries are being studied in their use in DIA experiments. Specifically, PROSIT is a tool that is used for predicted library generation and it functions by entering peptide sequences through its neural network where it estimates the fragmentation patterns as well as the retention times for the peptide Searle et al. 2020. As PROSIT generates estimates on peptide inputs, it generates a predicted library that can be used in DIA data analysis. This predicted library requires neither DIA sample data nor DDA sample data and is, therefore, a low-labor tool in library generation. Predicted libraries are still being studied in their application to DIA data analysis. Predicted libraries generally underperform compared to DDA-generated libraries; however, these libraries do significantly increase the quality of results compared to forgoing the use of a library altogether. This fact combined with their non-laborious nature means that predicted libraries can be useful in analyzing DIA data.
In the case in which a predicted library cannot be generated, DIA-Umpire is another tool that is involved in DIA data analysis in which pseudo-spectra are generated Chih-Chiang Tsou et al. 2015. This tool extracts information on coeluting fragment ions that are associated with a specific peptide. This information is used to generate a pseudo-spectrum examining the monoisotopic peak as well as its precursor signals and fragment ions that coelute. Once this information is combined and the pseudo-spectrum is generated with DIA-Umpire, this spectrum can be used relatively normally as if it were a DDA-generated library. This method of generating pseudo-spectra is relatively robust; however, it does rely on the ability to detect monoisotopic precursor peaks.
Analysis of DIA data through EncyclopeDIA
EncyclopeDIA is the tool used for DIA data analysis through searching peptides against the generated Chromatogram Library. Utilizing the generated Chromatogram library, as well as the experimental DIA data (mzML format), and the background protein database used previously, EncyclopeDIA searches the experimental DIA data against these libraries. Generated are a log .txt file and two quantitation outputs for both proteins and peptides.
Hands On: Library searching directly from DIA MS/MS data.
- EncyclopeDIA Quantify samples from Data-Independent Acquisition (DIA) MS/MS Data ( Galaxy version 1.12.34) with the following parameters:
- param-file “Spectrum files in mzML format”:
output(output of msconvert tool)- param-file “Library: Chromatagram .ELIB or Spectrum .DLIB”:
elib(output of SearchToLib tool)- param-file “Background proteome protein fasta database”:
output(Input dataset)- In “Parameter Settings”:
- “Set Acquisition Options”:
No - use default options- “Set Tolerance Options”:
No - use default options- “Set Percolator Options”:
No - use default options- “Set Peak Options”:
No - use default options- “Set Window Options”:
No - use default options- “Set Modifications Options”:
No - use default options- “Set Search Options”:
No - use default optionsCommentEncyclopeDIA will generate two important outputs: Peptide Quantitation Output, as well as Protein Quantitation Output (both .txt files). These outputs will contain information on the peptide sequences, protein IDs, and quantitation of protein and peptide fragments.
Question
- Are there any other tools available to analyze DIA data?
- Can EncyclopeDIA be used if a Chromatogram Library is not generated?
- There are other software to analyze DIA data, such as Spectronaut and Scaffold DIA. However, these softwares have not been wrapped to form tools on the GalaxyEU platform, and therefore cannot be incorporated into this workflow.
- EncyclopeDIA accepts ELIB (Chromatogram Library format) or DLIB (DDA Library format), and therefore a DDA-generated library could be used with the EncyclopeDIA tool to analyze DIA data.
As mentioned, EncyclopeDIA generates quantitative information on both peptides and proteins.
Sample output of the Peptide Quantitation Ouput:
 Open image in new tab
Open image in new tabSample output of the Protein Quantitation Output:
 Open image in new tab
Open image in new tabInputs required for EncyclopeDIA:
Chromatogram Library (.dlib)
Background Proteome FASTA file
Experimental DIA mzML dataset collection
EncyclopeDIA generated outputs:
Log.txt file
Quantification of datasets in ELIB format
Concatenated quantification of datasets in tabular format
Peptide quantitation in tabular format
Protein quantitation in tabular format
Comment: Tool VersionsThe tools are subjected to changes while being upgraded. Thus, running the workflow provided with the tutorial, the user might need to make sure they are using the latest version including the updated parameters.
Conclusion
This completes the walkthrough of the EncyclopeDIA Standard workflow.
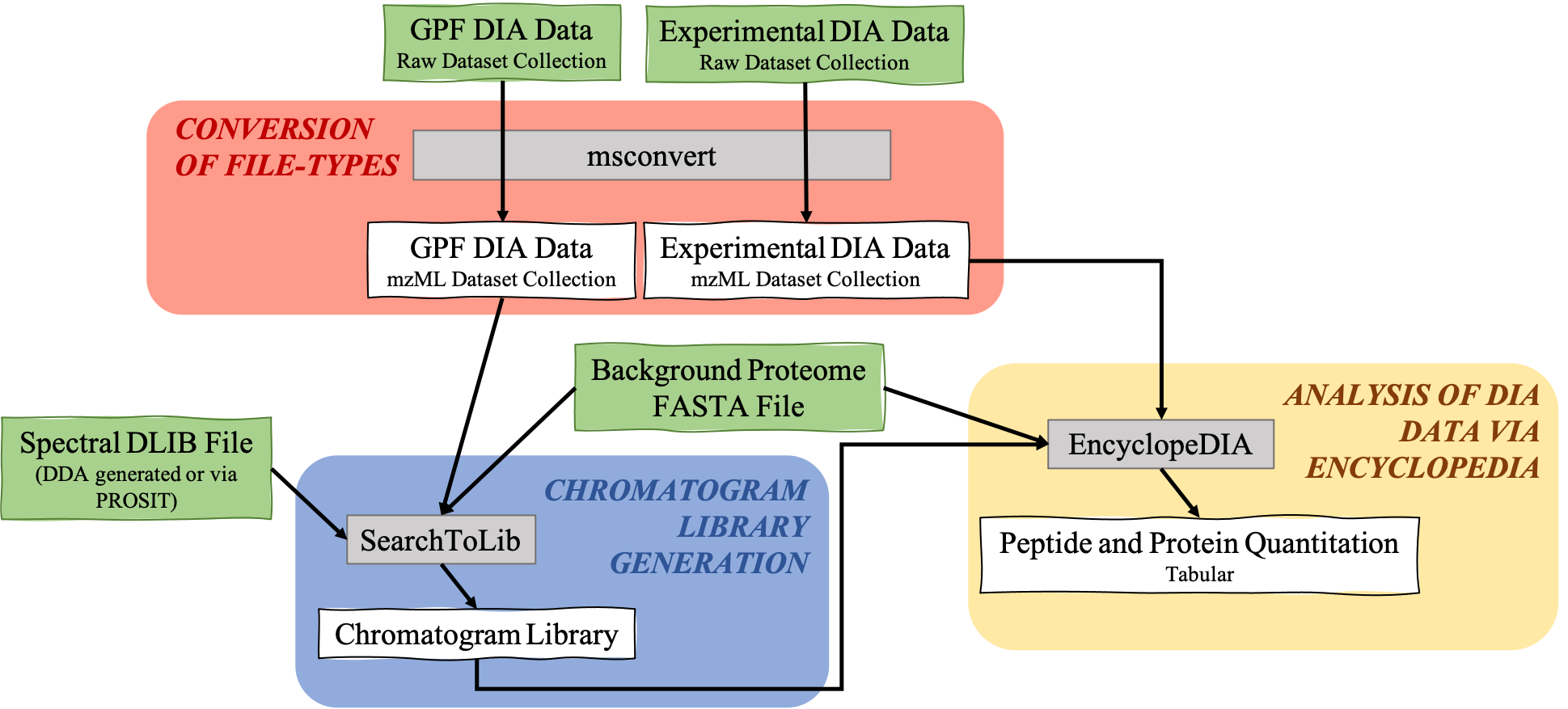 Open image in new tab
Open image in new tabThis tutorial is a guide to converting DIA data to the required input format, generation of a Chromatogram Library, and analysis of experimental DIA data using the EncyclopeDIA tool, developed by Brian Searle. This tutorial and workflow are available for use by researchers with their data; however, please note that the tool parameters and the workflow will be needed to be modified accordingly.
This workflow was developed by the Galaxy-P team at the University of Minnesota. For more information about Galaxy-P or our ongoing work, please visit us at galaxyp.org
You've Finished the Tutorial
Key points
With SearchToLib, Chromatogram Libraries can be created
Learning conversion of file types using msconvert
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
References
- Gillet, L. C., P. Navarro, S. Tate, H. Röst, N. Selevsek et al., 2012 Targeted Data Extraction of the MS/MS Spectra Generated by Data-independent Acquisition: A New Concept for Consistent and Accurate Proteome Analysis. Molecular & Cellular Proteomics 11: O111.016717. 10.1074/mcp.o111.016717
- Chih-Chiang Tsou, D. A., B. Larsen, M. Tucholska, H. Choi, A.-C. Gingras et al., 2015 DIA-Umpire: comprehensive computational framework for data-independent acquisition proteomics. Nature Methods 12: 258–264. 10.1038/nmeth.3255
- Pino, L. K., S. C. Just, M. J. MacCoss, and B. C. Searle, 2020 Acquiring and Analyzing Data Independent Acquisition Proteomics Experiments without Spectrum Libraries. 19: 1088–1103. 10.1074/mcp.p119.001913
- Searle, B. C., K. E. Swearingen, C. A. Barnes, T. Schmidt, S. Gessulat et al., 2020 Generating high quality libraries for DIA MS with empirically corrected peptide predictions. Nature Communications 11: 1548. 10.1038/s41467-020-15346-1
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Emma Leith, Subina Mehta, James Johnson, Pratik Jagtap, Timothy J. Griffin, EncyclopeDIA (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/encyclopedia/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{proteomics-encyclopedia, author = "Emma Leith and Subina Mehta and James Johnson and Pratik Jagtap and Timothy J. Griffin", title = "EncyclopeDIA (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/encyclopedia/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/proteomics/tutorials/encyclopedia/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: encyclopedia_quantify owner: galaxyp revisions: 1c5cbf8f79ce tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: encyclopedia_searchtolib owner: galaxyp revisions: 36880dfd9fa7 tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: msconvert owner: galaxyp revisions: 6153e8ada1ee tool_panel_section_label: Convert Formats tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: msconvert owner: galaxyp revisions: 28ffaaa5739f tool_panel_section_label: Convert Formats tool_shed_url: https://toolshed.g2.bx.psu.edu/