Measuring gene expression on a genome-wide scale has become common practice over the last two decades or so, with microarrays predominantly used pre-2008. With the advent of next generation sequencing technology in 2008, an increasing number of scientists use this technology to measure and understand changes in gene expression in often complex systems. As sequencing costs have decreased, using RNA-Seq to simultaneously measure the expression of tens of thousands of genes for multiple samples has never been easier. The cost of these experiments has now moved from generating the data to storing and analysing it.
There are many steps involved in analysing an RNA-Seq experiment. The analysis begins with sequencing reads (FASTQ files). These are usually aligned to a reference genome, if available. Then the number of reads mapped to each gene can be counted. This results in a table of counts, which is what we perform statistical analyses on to determine differentially expressed genes and pathways. The purpose of this tutorial is to demonstrate how to perform differential expression on count data with limma-voom. How to generate counts from reads (FASTQs) is covered in the accompanying tutorial RNA-seq reads to counts.
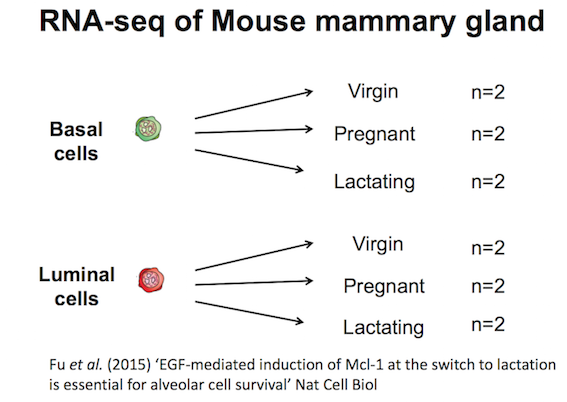
Mouse mammary gland dataset
The data for this tutorial comes from a Nature Cell Biology paper by Fu et al. 2015. Both the raw data (sequence reads) and processed data (counts) can be downloaded from Gene Expression Omnibus database (GEO) under accession number GSE60450.
This study examined the expression profiles of basal and luminal cells in the mammary gland of virgin, pregnant and lactating mice. Six groups are present, with one for each combination of cell type and mouse status. Note that two biological replicates are used here, two independent sorts of cells from the mammary glands of virgin, pregnant or lactating mice, however three replicates is usually recommended as a minimum requirement for RNA-seq. In this tutorial we will use the GEO counts file as a starting point for our analysis. Alternatively, you could create a count matrix from the raw sequence reads, as demonstrated in the RNA-seq reads to counts tutorial. The GEO count file was generated from aligning the reads to the mouse mm10 genome with the Rsubread aligner (Liao et al. 2019), followed by counting reads mapped to RefSeq genes with featureCounts (Liao et al. 2013), see the Fu paper for details.
We will use limma-voom (Law et al. 2014) for identifying differentially expressed genes here. Other popular alternatives are edgeR (Robinson et al. 2010) and DESeq2 (Love et al. 2014). Limma-voom has been shown to be perform well in terms of precision, accuracy and sensitivity (Costa-Silva et al. 2017) and, due to its speed, it’s particularly recommended for large-scale datasets with 100s of samples (Chen and Smyth 2016).
Your results may be slightly different from the ones presented in this tutorial due to differing versions of tools, reference data, external databases, or because of stochastic processes in the algorithms.
Create a new history for this RNA-seq exercise e.g. RNA-seq with limma-voom
To create a new history simply click the new-history icon at the top of the history panel:
Click on galaxy-pencil (Edit) next to the history name (which by default is “Unnamed history”)
Type the new name
Click on Save
To cancel renaming, click the galaxy-undo “Cancel” button
If you do not have the galaxy-pencil (Edit) next to the history name (which can be the case if you are using an older version of Galaxy) do the following:
Click on Unnamed history (or the current name of the history) (Click to rename history) at the top of your history panel
Type the new name
Press Enter
Import the mammary gland counts table and the associated sample information file.
To import the files, there are two options:
Option 1: From a shared data library if available (GTN - Material -> transcriptomics -> 2: RNA-seq counts to genes)
Rename the counts dataset as countdata and the sample information dataset as factordata using the galaxy-pencil (pencil) icon.
Check that the datatype is tabular.
If the datatype is not tabular, please change the file type to tabular.
Click on the galaxy-pencilpencil icon for the dataset to edit its attributes
In the central panel, click galaxy-chart-select-dataDatatypes tab on the top
In the galaxy-chart-select-dataAssign Datatype, select tabular from “New Type” dropdown
Tip: you can start typing the datatype into the field to filter the dropdown menu
Click the Save button
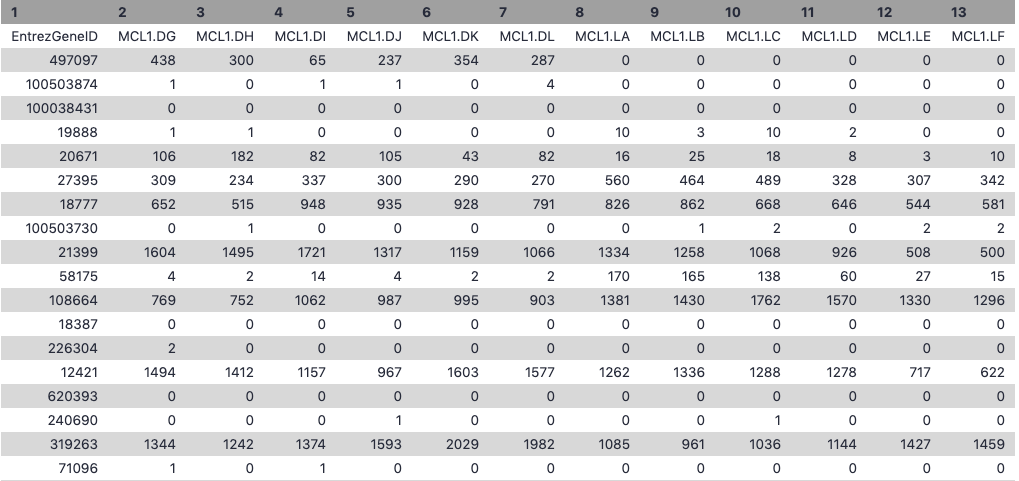
Let’s take a look at the data. The countdata file contains information about genes (one gene per row), the first column has the Entrez gene id and the remaining columns contain information about the number of reads aligning to the gene in each experimental sample. There are two replicates for each cell type and time point (detailed sample info can be found in file “GSE60450_series_matrix.txt” from the GEO website). The first few rows and columns of the seqdata file are shown below.
The factordata file contains basic information about the samples that we will need for the analysis. See below. Note that the sample ids must match exactly with the ids in the counts file.
Figure 5: Sample information file (before formatting)
To create the file, countdata, that contains only the counts for the 12 samples i.e. we’ll remove the gene length column with the Cut columns from a table (cut) tool. The sample names are also pretty long so we’ll use the >Replace Text in entire line tool to shorten these to contain only the relevant information about each sample. We will also replace the hyphen in the sample names with a dot so they match the names in the sample information file.
Hands On: Format the counts data
Cut columns from a table (cut)tool with the following parameters:
param-file“File to cut”: seqdata
param-select“Operation”: Discard
param-select“List of fields”: Select Column:2
Replace Text in entire linetool with the following parameters:
param-file“File to process”: output of Cuttool
param-text“Find pattern”: _B[A-Z0-9_]+
Replace Text in entire linetool with the following parameters:
param-file“File to process”: output of Replace Texttool
param-text“Find pattern”: -
param-text“Replace with”: .
Rename file as countdata using the galaxy-pencil (pencil) icon.
To create the file, factordata, that contains the groups information that we need for the limma-voom tool. We’ll combine the cell type and mouse status to make 6 groups e.g. we’ll combine the CellType basal with the Status pregnant for the group basalpregnant. We’ll use the Merge Columns tool to combine the cell type and mouse status columns in the sample information file, making a column with the 6 group names.
Hands On: Format the sample information file
Merge Columns togethertool with the following parameters:
param-file“Select data”: sampleinfo
param-select“Merge column”: Column: 3
param-select“with column”: Column: 4
Cut columns from a table (cut)tool with the following parameters:
param-file“File to cut”: output of Merge Columnstool
param-select“Operation”: Keep
param-select“List of fields”: Select Column:2 and Column:5
Rename file as factordata using the galaxy-pencil (pencil) icon.
Get gene annotations
Optionally, gene annotations can be provided to the limma-voom tool and if provided the annotation will be available in the output files. We’ll get gene symbols and descriptions for these genes using the Galaxy annotateMyIDs tool, which provides annotations for human, mouse, fruitfly and zebrafish.
Hands On: Get gene annotations
annotateMyIDstool with the following parameters:
param-file“File with IDs”: countdata
param-check“File has header”: Yes
param-select“Organism”: Mouse
param-select“ID Type”: Entrez
param-check “Output columns”: tick
ENTREZID
SYMBOL
GENENAME
Rename file as annodata using the galaxy-pencil (pencil) icon. The file should look like below.
Open image in new tab
Figure 6: Gene annotation file
Check the number of lines shown on the datasets in the history, there should be 27,180 lines in both. There must be the same number of lines (rows) in the counts and annotation.
Differential expression with limma-voom
Filtering to remove lowly expressed genes
It is recommended to filter for lowly expressed genes when running the limma-voom tool. Genes with very low counts across all samples provide little evidence for differential expression and they interfere with some of the statistical approximations that are used later in the pipeline. They also add to the multiple testing burden when estimating false discovery rates, reducing power to detect differentially expressed genes. These genes should be filtered out prior to further analysis.
There are a few ways to filter out lowly expressed genes. When there are biological replicates in each group, in this case we have a sample size of 2 in each group, we favour filtering on a minimum counts-per-million (CPM) threshold present in at least 2 samples. Two represents the smallest sample size for each group in our experiment. In this dataset, we choose to retain genes if they are expressed at a CPM above 0.5 in at least two samples. The CPM threshold selected can be compared to the raw count with the CpmPlots (see below).
The limma tool uses the cpm function from the edgeR package (Robinson et al. 2010) to generate the CPM values which can then be filtered. Note that by converting to CPMs we are normalizing for the different sequencing depths for each sample. A CPM of 0.5 is used as it corresponds to a count of 10-15 for the library sizes in this data set. If the count is any smaller, it is considered to be very low, indicating that the associated gene is not expressed in that sample. A requirement for expression in two or more libraries is used as each group contains two replicates. This ensures that a gene will be retained if it is only expressed in one group. Smaller CPM thresholds are usually appropriate for larger libraries. As a general rule, a good threshold can be chosen by identifying the CPM that corresponds to a count of 10, which in this case is about 0.5. You should filter with CPMs rather than filtering on the counts directly, as the latter does not account for differences in library sizes between samples.
Normalization for composition bias
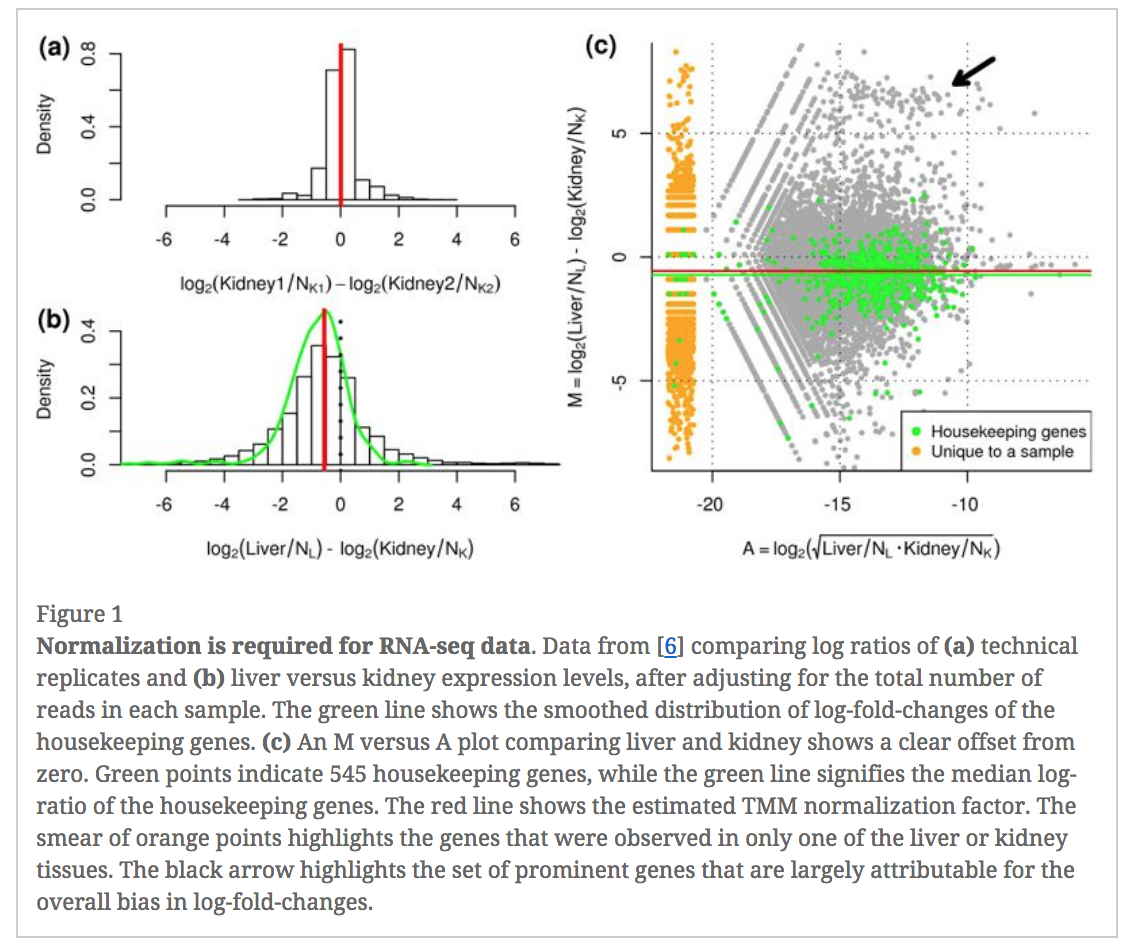
In an RNA-seq analysis, the counts are normalized for different sequencing depths between samples. Normalizing to eliminate composition biases between samples is also typically performed. Composition biases can occur, for example, if there are a few highly expressed genes dominating in some samples, leading to less reads from other genes. By default, TMM normalization (Robinson and Oshlack 2010) is performed by the limma tool using the edgeR calcNormFactors function (this can be changed under Advanced Options). TMM stands for Trimmed Mean of M values, where a weighted trimmed mean of the log expression ratios is used to scale the counts for the samples. See the figure from the TMM paper below. Note the plot (Figure 1c) that shows how a few highly expressed genes in the liver sample (where the arrow is) results in the majority of other genes in the sample having the appearance of being expressed lower in liver. The mid-line through the points is offset from the expected zero and the TMM normalization factor (red line) scales the counts to adjust for this.
Figure 7: TMM normalization (Robinson and Oshlack 2010)
Specify Contrast(s) of interest
Since we are interested in differences between groups, we need to specify which comparisons we want to test. For example, if we are interested in knowing which genes are differentially expressed between the pregnant and lactating group in the basal cells we specify basalpregnant-basallactate for the Contrast of Interest. Note that the group names in the contrast must exactly match the names of the groups in the factordata file. More than one contrast can be specified using the Insert Contrast button, so we could look at more comparisons of the groups here, but first we’ll take a look at basalpregnant-basallactate.
param-select“Count Files or Matrix?”: Single Count Matrix
param-file“Count Matrix”: Select countdata
param-select“Input factor information from file?”: Yes
param-file“Factor File”: Select factordata
param-select“Use Gene Annotations?”: Yes
param-file“Factor File”: Select annodata
param-text“Contrast of Interest”: basalpregnant-basallactate
param-select“Filter lowly expressed genes?”: Yes
param-select“Filter on CPM or Count values?”: CPM
param-text“Minimum CPM”: 0.5
param-text“Minimum Samples”: 2
Inspect the Report produced by clicking on the galaxy-eye (eye) icon
If we need to account for additional sources of variation, for example, batch, sex, genotype etc, we can input that information as additional factors. For example, if we were interested in the genes differentially expressed between the luminal and basal cell types, we could include an additional column to account for the variation due to the different stages.
Before we check out the differentially expressed genes, we can look at the Report information to check that the data is good quality and that the samples are as we would expect.
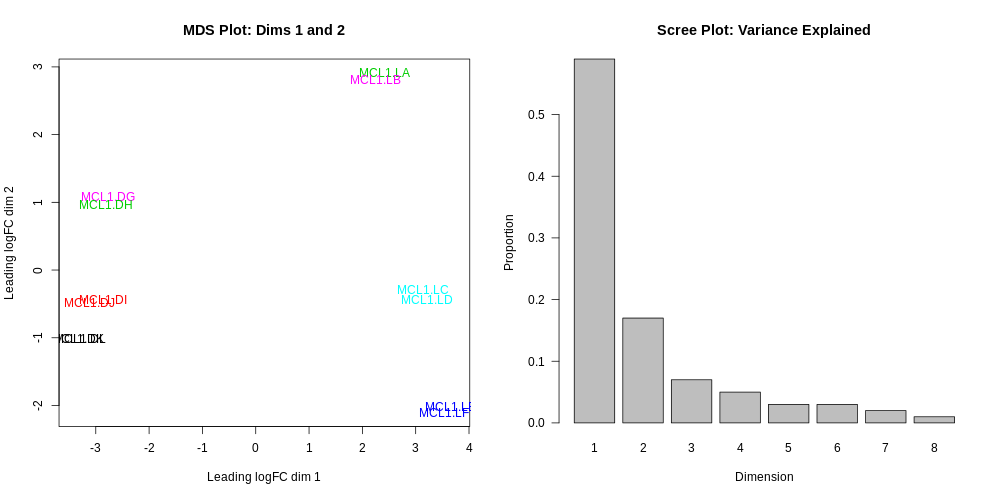
Multidimensional scaling plot
By far, one of the most important plots we make when we analyse RNA-Seq data are MDS plots. An MDS plot is a visualisation of a principal components analysis, which determines the greatest sources of variation in the data. A principal components analysis is an example of an unsupervised analysis, where we don’t need to specify the groups. If your experiment is well controlled and has worked well, what we hope to see is that the greatest sources of variation in the data are the treatments/groups we are interested in. It is also an incredibly useful tool for quality control and checking for outliers. This Galaxy limma tool outputs an MDS plot by default in the Report and a link is also provided to a PDF version (MDSPlot_CellTypeStatus.pdf). A scree plot is also produced that shows how much variation is attributed to each dimension. If there was a batch effect for example, you may see high values for additional dimensions, and you may choose to include batch as an additional factor in the differential expression analysis. The limma tool plots the first two dimensions by default (1 vs 2), however you can also plot additional dimensions 2 vs 3 and 3 vs 4 using under Output OptionsAdditional PlotsMDS Extra. These are displayed in the Report along with a link to a PDF version (MDSPlot_extra.pdf). Selecting the Glimma Interactive Plots will generate an interactive version of the MDS plot, see the plots section of the report below. If outlier samples are detected you may decide to remove them. Alternatively, you could downweight them by choosing the option in the limma tool Apply voom with sample quality weights?. The voom sample quality weighting is described in the paper Why weight? Modelling sample and observational level variability improves power in RNA-seq analyses (Liu et al. 2015).
Do you notice anything about the samples in this plot?
Two samples don’t appear to be in the right place.
It turns out that there has been a mix-up with two samples, they have been mislabelled in the sample information file. This shows how the MDS plot can also be useful to help identify if sample mix-ups may have occurred. We need to redo the limma-voom analysis with the correct sample information.
Hands On: Use the Rerun button to redo steps
Import the correct sample information file from https://zenodo.org/record/4273218/files/factordata_fixed.tsv and name as factordata_fixed
Use the Rerungalaxy-refresh button in the History to run limmatool as before with the factordata_fixed file and adding the following parameters:
Output Options
param-check“Additional Plots” tick:
Glimma Interactive Plots
Density Plots (if filtering)
CpmsVsCounts Plots (if filtering on cpms)
Box Plots (if normalising)
MDS Extra (Dims 2vs3 and 3vs4)
MD Plots for individual samples
Heatmaps (top DE genes)
Stripcharts (top DE genes)
Delete the incorrect factordata file and its limma outputs to avoid any confusion.
In the Report you should then see the correct MDS plot as below.
What is the greatest source of variation in the data (i.e. what does dimension 1 represent)?
What is the second greatest source of variation in the data?
Dimension 1 represents the variation due to cell type, basal vs luminal. Dimension 2 represents the variation due to the stages, virgin, pregnant or lactating.
Next, scroll down the Report to take a look at the Additional information and Summary of experimental data sections near the bottom. It should look similar to below. Here you can check that the correct samples have been assigned to the correct groups, what settings were used (e.g. filters, normalization method) and also how many genes were filtered out due to low expression.
Question
How many genes have been filtered out for low expression?
11375 genes were filtered out as insignificant as they were without more than 0.5 CPM in at least 2 samples.
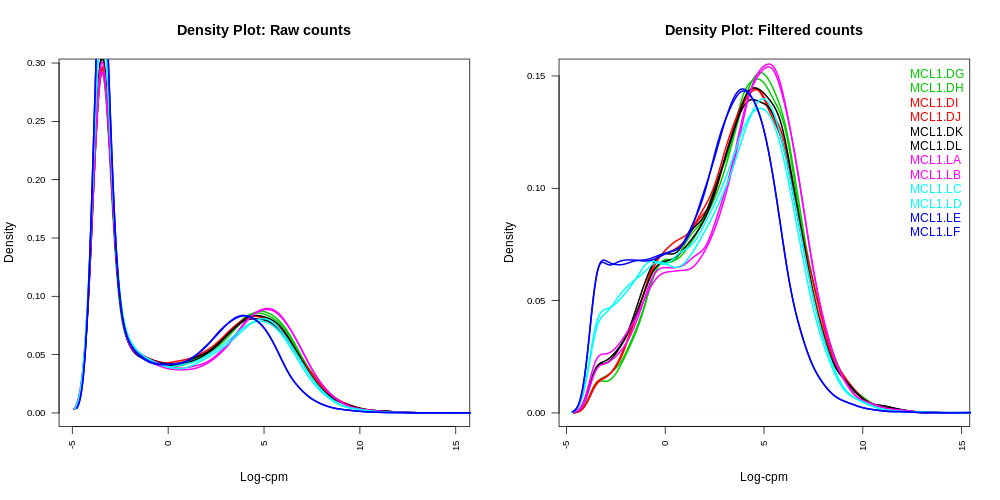
Density plots
Density plots can be output in the Report if Filter lowly expressed genes is selected. A link is also provided in the Report to a PDF version (DensityPlots.pdf). These plots allow comparison of the counts distributions before and after filtering. The samples are coloured by the groups. Count data is not normally distributed, so if we want to examine the distributions of the raw counts we need to log the counts. We typically check the distribution of the read counts on the log2 scale. A CPM value of 1 is equivalent to a log-CPM value of 0 and the CPM we used of 0.5 is equivalent to a log-CPM of -1. It can be seen in the Raw counts (before filtering) plot below, that a large proportion of genes within each sample are not expressed or lowly-expressed, and the Filtered counts plot shows our filter of CPM of 0.5 (in at least 2 samples) removes a lot of these uninformative genes.
We can also have a look more closely to see whether our threshold of 0.5 CPM does indeed correspond to a count of about 10-15 reads in each sample with the plots of CPM versus raw counts.
Click on the CpmPlots.pdf link in the Report. You should see 12 plots, one for each sample. Two of the plots are shown below. From these plots we can see that 0.5 CPM is equivalent to ~10 counts in each of the 12 samples, so 0.5 seems to be an appropriate threshold for this dataset (these samples all have sequencing depth of 20-30 million, see the Library information file below, so a CPM value of 0.5 would be ~10 counts).
A threshold of 1 CPM in at least minimum group sample size is a good rule of thumb for samples with about 10 million reads. For larger library sizes increase the CPM theshold and for smaller library sizes decrease it. Check the CpmPlots to see if the selected threshold looks appropriate for the samples (equivalent to ~10 reads).
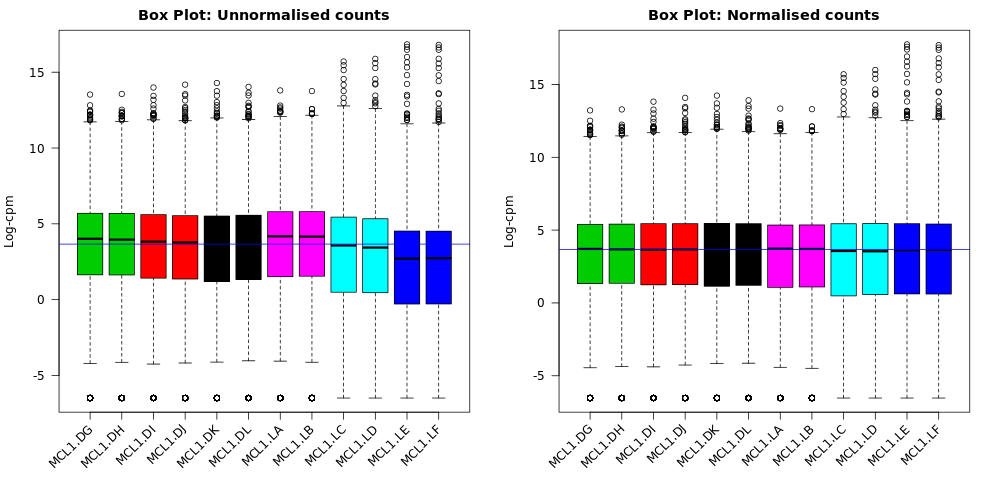
Box plots
We can also use box plots to check the distributions of counts in the samples. Box plots can be selected to be output by the Galaxy limma-voom tool if normalization is applied (TMM is applied by default). The plots are output in the Report and a link is also provided to a PDF version (BoxPlots.pdf). The samples are coloured by the groups. With the box plots for these samples we can see that overall the distributions are not identical but still not very different. If a sample is really far above or below the blue horizontal line we may need to investigate that sample further.
Compare the box plots before and after TMM normalisation. Can you see any differences?
After the normalization more of the samples are closer to the median horizontal line.
The TMM normalization generates normalization factors, where the product of these factors and the library sizes defines the effective library size. TMM normalization (and most scaling normalization methods) scale relative to one sample. The normalization factors multiply to unity across all libraries. A normalization factor below one indicates that the library size will be scaled down, as there is more suppression (i.e., composition bias) in that library relative to the other libraries. This is also equivalent to scaling the counts upwards in that sample. Conversely, a factor above one scales up the library size and is equivalent to downscaling the counts. We can see the normalization factors for these samples in the Library information file if we select to output it with “Output Library information file?”: Yes. Click on the galaxy-eye (eye) icon to view.
Which sample has the largest normalization factor? Which sample has the smallest?
MCL1.LA has the largest normalization factor and MCL1.LE the smallest.
It is considered good practice to make mean-difference (MD) plots for all the samples as a quality check, as described in this edgeR workflow article. These plots allow expression profiles of individual samples to be explored more closely. An MD plot shows the log-fold change between a sample against the average expression across all the other samples. This visualisation can help you see if there are genes highly upregulated or downregulated in a sample. If we look at mean difference plots for these samples, we should be able to see the composition bias problem. The mean-difference plots show average expression (mean: x-axis) against log-fold-changes (difference: y-axis).
Click on the MDPlots_Samples.pdf link in the Report. You should see 12 MD plots, one for each sample. Let’s take a look at the plots for the two samples MCL1.LA and MCL1.LE that had the largest and smallest normalization factors. The MD plots on the left below show the counts normalized for library size and the plots on the right show the counts after the TMM normalization has been applied. MCL1.LA had the largest normalization factor and was above the median line in the unnormalized by TMM box plots. MCL1.LE had the smallest normalization factor and was below the median line in the box plots. These MD plots help show the composition bias problem has been addressed.
Figure 16: MD Plots for MCL1.LA before and after TMM normalizationOpen image in new tab
Figure 17: MD Plots for MCL1.LE before and after TMM normalization
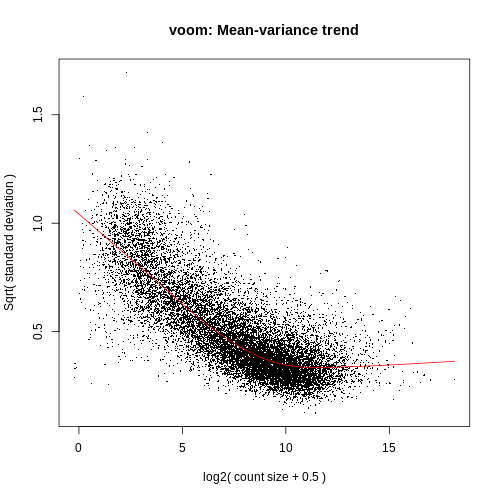
Voom variance plot
This plot is generated by the voom method and displayed in the Report along with a link to a PDF version (VoomPlot.pdf). Each dot represents a gene and it shows the mean-variance relationship of the genes in the dataset. This plot can help show if low counts have been filtered adequately and if there is a lot of variation in the data, as shown in the More details on Voom variance plots box below.
The SA plot below plots log2 residual standard deviations against mean log-CPM values. The average log2 residual standard deviation is marked by a horizontal blue line. This plot shows how the dependence between the means and variances has been removed after the voom weights are applied to the data.
Figure 1: Mean-variance relationships. Gene-wise means and variances of RNA-seq data are represented by black points with a LOWESS trend. Plots are ordered by increasing levels of biological variation in datasets. (a) voom trend for HBRR and UHRR genes for Samples A, B, C and D of the SEQC project; technical variation only. (b) C57BL/6J and DBA mouse experiment; low-level biological variation. (c) Simulation study in the presence of 100 upregulating genes and 100 downregulating genes; moderate-level biological variation. (d) Nigerian lymphoblastoid cell lines; high-level biological variation. (e) Drosophila melanogaster embryonic developmental stages; very high biological variation due to systematic differences between samples. (f) LOWESS voom trends for datasets (a)–(e). HBRR, Ambion’s Human Brain Reference RNA; LOWESS, locally weighted regression; UHRR, Stratagene’s Universal Human Reference RNA.
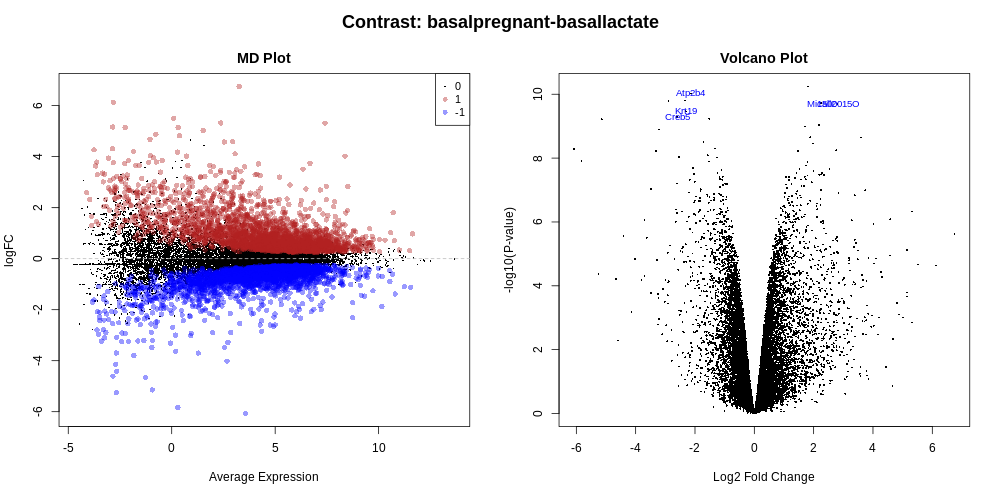
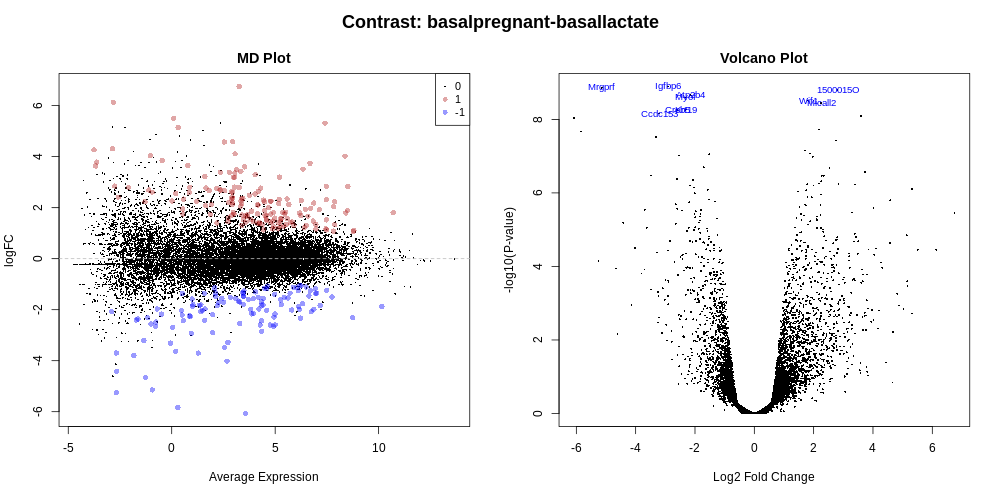
MD and Volcano plots for DE results
Genome-wide plots that are useful for checking differentially expressed (DE) results are MD plots (or MA plots) and Volcano plots. There are functions in limma for generating these plots and they are used by this tool. These plots are output by default and shown in the Report along with a link to PDF versions (MDPlot_basalpregnant-basallactate.pdf and VolcanoPlot_basalpregnant-basallactate.pdf). In the volcano plot the top genes (by adjusted p-value) are highlighted. The number of top genes is 10 by default and the user can specify the number of top genes to view (up to 100) under Advanced Options. For further information on volcano plots see the Volcano Plot tutorial
The MD Plot highlighted genes are significant at an adjusted p-value (adj.P) threshold of 0.05 and exhibit log2-fold-change (lfc) of at least 0. These thresholds can be changed under Advanced Options.
Question
How many genes are differentially expressed at the default thresholds of adj.P=0.05 and lfc=0?
The number of DE genes at these adj.P and lfc thresholds is shown in the table in the Report as below.
Comment: on adjusted P value
A note about deciding how many genes are significant: In order to decide which genes are differentially expressed, we usually take a cut-off (e.g. 0.05 or 0.01) on the adjusted p-value, NOT the raw p-value. This is because we are testing many genes (more than 15000 genes here), and the chances of finding differentially expressed genes is very high when you do that many tests. Hence we need to control the false discovery rate, which is the adjusted p-value column in the results table. What this means is that, if we choose an adjusted p-value cut-off of 0.05, and if 100 genes are significant at a 5% false discovery rate, we are willing to accept that 5 will be false positives.
Testing relative to a threshold (TREAT)
When there is a lot of differential expression, sometimes we may want to cut-off on a fold change threshold, as well as a p-value threshold, so that we follow up on the most biologically significant genes. However, it is not recommended to simply rank by p-value and then discard genes with small logFC’s, as this has been shown to increase the false discovery rate. In other words, you are not controlling the false discovery rate at 5% any more. There is a function called treat in limma that performs this style of analysis correctly (McCarthy and Smyth 2009). TREAT will simply take a user-specified log fold change cut-off and recalculate the moderated t-statistics and p-values with the new information about logFC. There are thousands of genes differentially expressed in this basalpregnant-basallactate comparison, so let’s rerun the analysis applying TREAT and similar thresholds to what was used in the Fu paper: an adjusted P value of 0.01 (1% false discovery rate) and a log-fold-change cutoff of 0.58 (equivalent to a fold change of 1.5).
Hands On: Testing relative to a threshold (TREAT)
Use the Rerungalaxy-refresh button in the History to rerun limmatool with the following parameters:
“Advanced Options”
param-text“Minimum Log2 Fold Change”: 0.58
param-text“P-Value Adjusted Threshold”: 0.01
param-check“Test significance relative to a fold-change threshold (TREAT)”: Yes
Add a tag #treat to the Report output and inspect the report
Datasets can be tagged. This simplifies the tracking of datasets across the Galaxy interface. Tags can contain any combination of letters or numbers but cannot contain spaces.
To tag a dataset:
Click on the dataset to expand it
Click on Add Tagsgalaxy-tags
Add tag text. Tags starting with # will be automatically propagated to the outputs of tools using this dataset (see below).
Press Enter
Check that the tag appears below the dataset name
Tags beginning with # are special!
They are called Name tags. The unique feature of these tags is that they propagate: if a dataset is labelled with a name tag, all derivatives (children) of this dataset will automatically inherit this tag (see below). The figure below explains why this is so useful. Consider the following analysis (numbers in parenthesis correspond to dataset numbers in the figure below):
a set of forward and reverse reads (datasets 1 and 2) is mapped against a reference using Bowtie2 generating dataset 3;
dataset 3 is used to calculate read coverage using BedTools Genome Coverageseparately for + and - strands. This generates two datasets (4 and 5 for plus and minus, respectively);
datasets 4 and 5 are used as inputs to Macs2 broadCall datasets generating datasets 6 and 8;
datasets 6 and 8 are intersected with coordinates of genes (dataset 9) using BedTools Intersect generating datasets 10 and 11.
Now consider that this analysis is done without name tags. This is shown on the left side of the figure. It is hard to trace which datasets contain “plus” data versus “minus” data. For example, does dataset 10 contain “plus” data or “minus” data? Probably “minus” but are you sure? In the case of a small history like the one shown here, it is possible to trace this manually but as the size of a history grows it will become very challenging.
The right side of the figure shows exactly the same analysis, but using name tags. When the analysis was conducted datasets 4 and 5 were tagged with #plus and #minus, respectively. When they were used as inputs to Macs2 resulting datasets 6 and 8 automatically inherited them and so on… As a result it is straightforward to trace both branches (plus and minus) of this analysis.
In addition to the plots already discussed, it is recommended to have a look at the expression levels of the individual samples for the genes of interest, before following up on the DE genes with further lab work. The Galaxy limma tool can auto-generate heatmaps of the top genes to show the expression levels across the samples. This enables a quick view of the expression of the top differentially expressed genes and can help show if expression is consistent amongst replicates in the groups.
Heatmap of top genes
Click on the Heatmap_basalpregnant-basallactate.pdf link in the Report. You should see a plot like below.
The limma-voom tool can also auto-generate stripcharts to view the expression of the top genes across the groups. Click on the Stripcharts_basalpregnant-basallactate.pdf link in the Report. You should see 10 plots, one for each top gene. Four are shown below. Note that here you can see if replicates tend to group together and how the expression compares to the other groups.
Interactive versions of the MD and Volcano plots can be output by the limma-voom tool via the Glimma package (Su et al. 2017), if a gene annotation file is provided and Glimma Interactive Plots is selected. Links to the Glimma html pages are generated in the Report.
Let’s take a look at the interactive MD plot. Click on the Glimma_MDPlot_basalpregnant-basallactate.html link in the Report. You should see a two-panel interactive MD plot like below. The left plot shows the log-fold-change vs average expression. The right plot shows the expression levels of a particular gene of each sample by groups (similar to the stripcharts). Hovering over points on left plot will plot expression level for corresponding gene, clicking on points will fix the expression plot to gene. Clicking on rows on the table has the same effect as clicking on the corresponding gene in the plot.
Hands On: Search for a gene of interest
Egf was a gene identifed as very highly expressed in the Fu paper and confirmed with qRT-PCR, see Fig. 6c from the paper below.
Notice that in the plot on the right above, showing Egf expression for all samples, we can see it is highly expressed in the luminal lactate group but not the other samples.
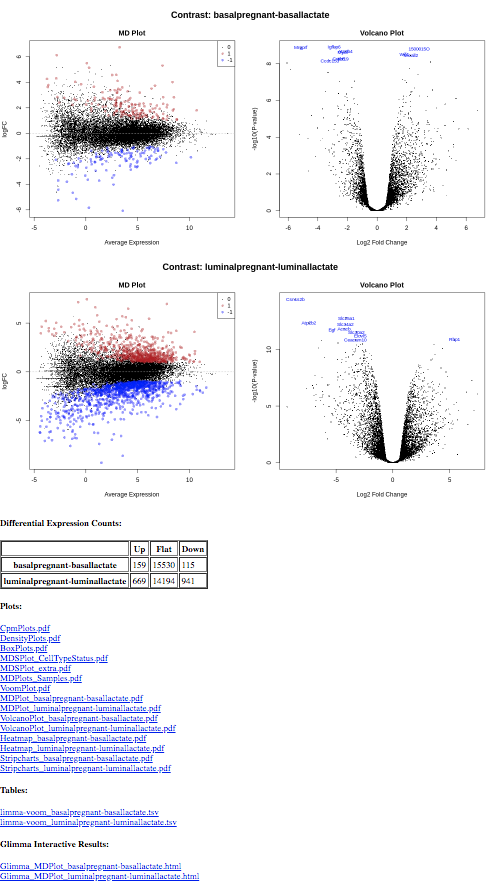
Multiple contrasts can be run with the limma tool. For example, we can compare the pregnant and lactating conditions for both the basal and luminal cells. So let’s rerun the limma-voom TREAT analysis (adj.P <0.01 and lfc=0.58) and this time use the Insert Contrast button to include the additional contrast luminalpregnant - luminallactate. We can then see how the number of differentially expressed genes in the luminal cells compares to the basal cells.
Hands On: Run multiple contrasts
Use the Rerungalaxy-refresh button in the History to rerun the limmatool#treat analysis adding the following parameters (i.e. run with 2 contrasts):
param-text“Contrast of Interest”: basalpregnant-basallactate
param-text“Contrast of Interest”: luminalpregnant-luminallactate
Add a tag #multiple-contrasts to the Report output and inspect the report
You should find that there are more genes differentially expressed for the luminal cells than the basal. There are ~274 genes DE in basal cells versus ~ 1610 in the luminal cells.
The tables of differentially expressed genes are output as links in the Report (limma-voom_basalpregnant-basallactate.tsv and limma-voom_luminalpregnant-luminallactate.tsv), see below, and also as datasets in the history (DE tables). With multiple contrasts, a plot for each contrast is generated for relevant plots, as shown below. This enables a quick and easy visual comparison of the contrasts.
In this tutorial we have seen how counts files can be converted into differentially expressed genes with limma-voom. This follows on from the accompanying tutorial, RNA-seq reads to counts, that showed how to generate counts from the raw reads (FASTQs) for this dataset. In this part we have seen ways to visualise the count data, and QC checks that can be performed to help assess the quality and results. We have also reproduced results similar to what the authors found in the original paper with this dataset. For further reading on analysis of RNA-seq count data and the methods used here, see the articles; RNA-seq analysis is easy as 1-2-3 with limma, Glimma and edgeR (Law et al. 2018) and From reads to genes to pathways: differential expression analysis of RNA-Seq experiments using Rsubread and the edgeR quasi-likelihood pipeline (Chen and Smyth 2016).
You've Finished the Tutorial
Please also consider filling out the Feedback Form as well!
Key points
The limma-voom tool can be used to perform differential expression and output useful plots
Multiple comparisons can be input and compared
Results can be interactively explored with limma-voom via Glimma
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channels
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
References
McCarthy, D. J., and G. K. Smyth, 2009 Testing significance relative to a fold-change threshold is a TREAT. Bioinformatics 25: 765–771. 10.1093/bioinformatics/btp053
Robinson, M. D., D. J. McCarthy, and G. K. Smyth, 2010 edgeR: a Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics 26: 139–140.
Robinson, M. D., and A. Oshlack, 2010 A scaling normalization method for differential expression analysis of RNA-seq data. Genome biology 11: 1–9.
Law, C. W., Y. Chen, W. Shi, and G. K. Smyth, 2014 voom: precision weights unlock linear model analysis tools for RNA-seq read counts. Genome Biology 15: R29. 10.1186/gb-2014-15-2-r29
Fu, N. Y., A. C. Rios, B. Pal, R. Soetanto, A. T. L. Lun et al., 2015 EGF-mediated induction of Mcl-1 at the switch to lactation is essential for alveolar cell survival. Nature Cell Biology 17: 365–375. 10.1038/ncb3117
Liu, R., A. Z. Holik, S. Su, N. Jansz, K. Chen et al., 2015 Why weight? Modelling sample and observational level variability improves power in RNA-seq analyses. Nucleic Acids Research 43: e97. 10.1093/nar/gkv412
Chen, Y., and G. K. Smyth, 2016 It’s DE-licious: a recipe for differential expression analyses of RNA-seq experiments using quasi-likelihood methods in edgeR, pp. 391–416 inMethods in Molecular Biology, Springer. This book chapter explains the glmQLFit and glmQLFTest functions, which are alternatives to glmFit and glmLRT. They replace the chi-square approximation to the likelihood ratio statistic with a quasi-likelihood F-test, resulting in more conservative and rigorous type I error rate control.. 10.1007/978-1-4939-3578-9_19
Costa-Silva, J., D. Domingues, and F. M. Lopes, 2017 RNA-Seq differential expression analysis: An extended review and a software tool (Z. Wei, Ed.). PLOS ONE 12: e0190152. 10.1371/journal.pone.0190152
Su, S., C. W. Law, C. Ah-Cann, M.-L. Asselin-Labat, M. E. Blewitt et al., 2017 Glimma: interactive graphics for gene expression analysis (B. Berger, Ed.). Bioinformatics 33: 2050–2052. 10.1093/bioinformatics/btx094
Law, C. W., M. Alhamdoosh, S. Su, X. Dong, L. Tian et al., 2018 RNA-seq analysis is easy as 1-2-3 with limma, Glimma and edgeR. F1000Research 5: 1408. 10.12688/f1000research.9005.3
Liao, Y., G. K. Smyth, and W. Shi, 2019 The R package Rsubread is easier, faster, cheaper and better for alignment and quantification of RNA sequencing reads. Nucleic Acids Research 47: e47–e47. 10.1093/nar/gkz114
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{transcriptomics-rna-seq-counts-to-genes,
author = "Maria Doyle and Belinda Phipson and Jovana Maksimovic and Anna Trigos and Matt Ritchie and Harriet Dashnow and Shian Su and Charity Law",
title = "2: RNA-seq counts to genes (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/transcriptomics/tutorials/rna-seq-counts-to-genes/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Congratulations on successfully completing this tutorial!
Do you want to extend your knowledge?
Follow one of our recommended follow-up trainings:
5 stars:
Liked: seeing and knowing how to generate all the plots is very informative
June 2025
5 stars:
Liked: It was easy to follow and had a lot of new content and information. Additionally, it was very practical and gave a lot of helpful information for research and how to utitlise RNA-seq for it
Disliked: The powerpoint could be handed out to workshop participants.
March 2025
5 stars:
Liked: Thank you very much for the excellent tutorial.
November 2024
5 stars:
Liked: making different plots :)
5 stars:
Liked: the method of normalization
5 stars:
Liked: help full tutor
Disliked: A video of this tutorial available before the work shop would be the great help for many pupils especially who are international students and have different educational system background.
October 2024
5 stars:
Liked: It was very easy to follow
Disliked: More background information of specific details available if wanted by the user.
4 stars:
Liked: easy to follow
October 2023
5 stars:
Liked: Easy to follow
Disliked: -
December 2022
5 stars:
Liked: Everything was well-annotated. Thank you so much!
Disliked: I want to see ''How to DESeq2 Results File (DEG List) with Tabular format open in Excel?''.
September 2021
4 stars:
Liked: Good explanation!
Disliked: Explanation on how to understand the figures in depth
April 2021
4 stars:
Liked: easy to follow
Disliked: interactive plots could not be opened https://usegalaxy.org/datasets/bbd44e69cb8906b52089f52da217dea4/display/glimma_basalpregnant-basallactate/MD-Plot.html
5 stars:
Liked: I very much enjoy this tutorial! coming back from extensive R experience using limma, DEseq, still find this Galaxy thing makes things easier
March 2021
5 stars:
Liked: It was really clear and easy to follow.
August 2019
5 stars:
Liked: Easy to follow and showed what our plots/table should look like
April 2019
5 stars:
Liked: Clear, comprehensive, great screenshots
Disliked: Nothing so far
Questions:
 Open image in new tab
Open image in new tab

 Open image in new tab
Open image in new tab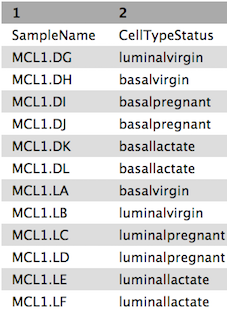 Open image in new tab
Open image in new tabOpen image in new tab
Open image in new tab
Open image in new tab
 Open image in new tab
Open image in new tabOpen image in new tab
 Open image in new tab
Open image in new tab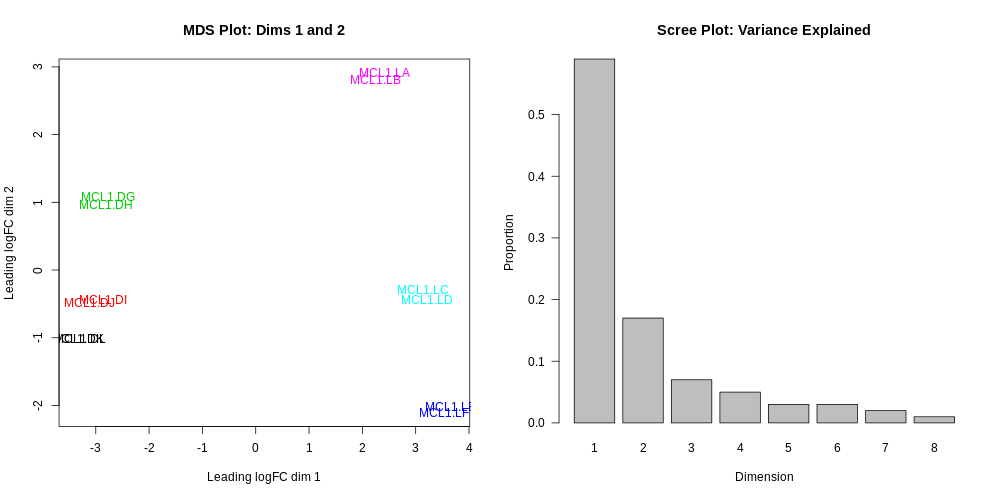 Open image in new tab
Open image in new tab
 Open image in new tab
Open image in new tab Open image in new tab
Open image in new tabOpen image in new tab
 Open image in new tab
Open image in new tabOpen image in new tab
Open image in new tab
Open image in new tab
 Open image in new tab
Open image in new tab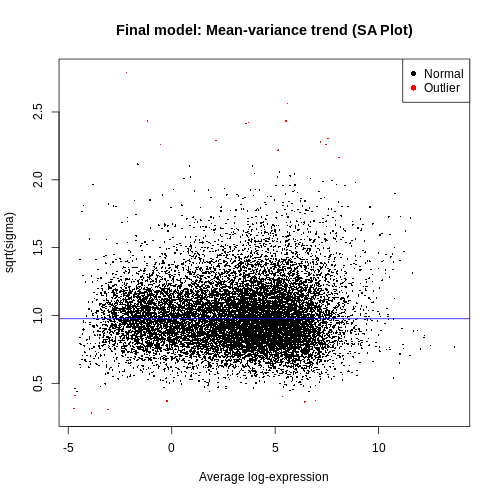 Open image in new tab
Open image in new tabOpen image in new tab
Open image in new tab
Open image in new tab
 Open image in new tab
Open image in new tab

 Open image in new tab
Open image in new tab Open image in new tab
Open image in new tab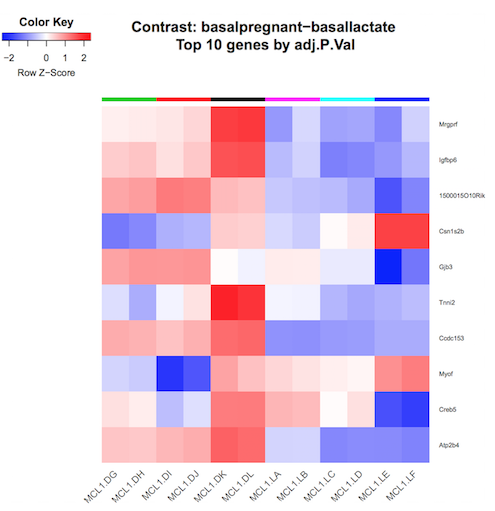 Open image in new tab
Open image in new tab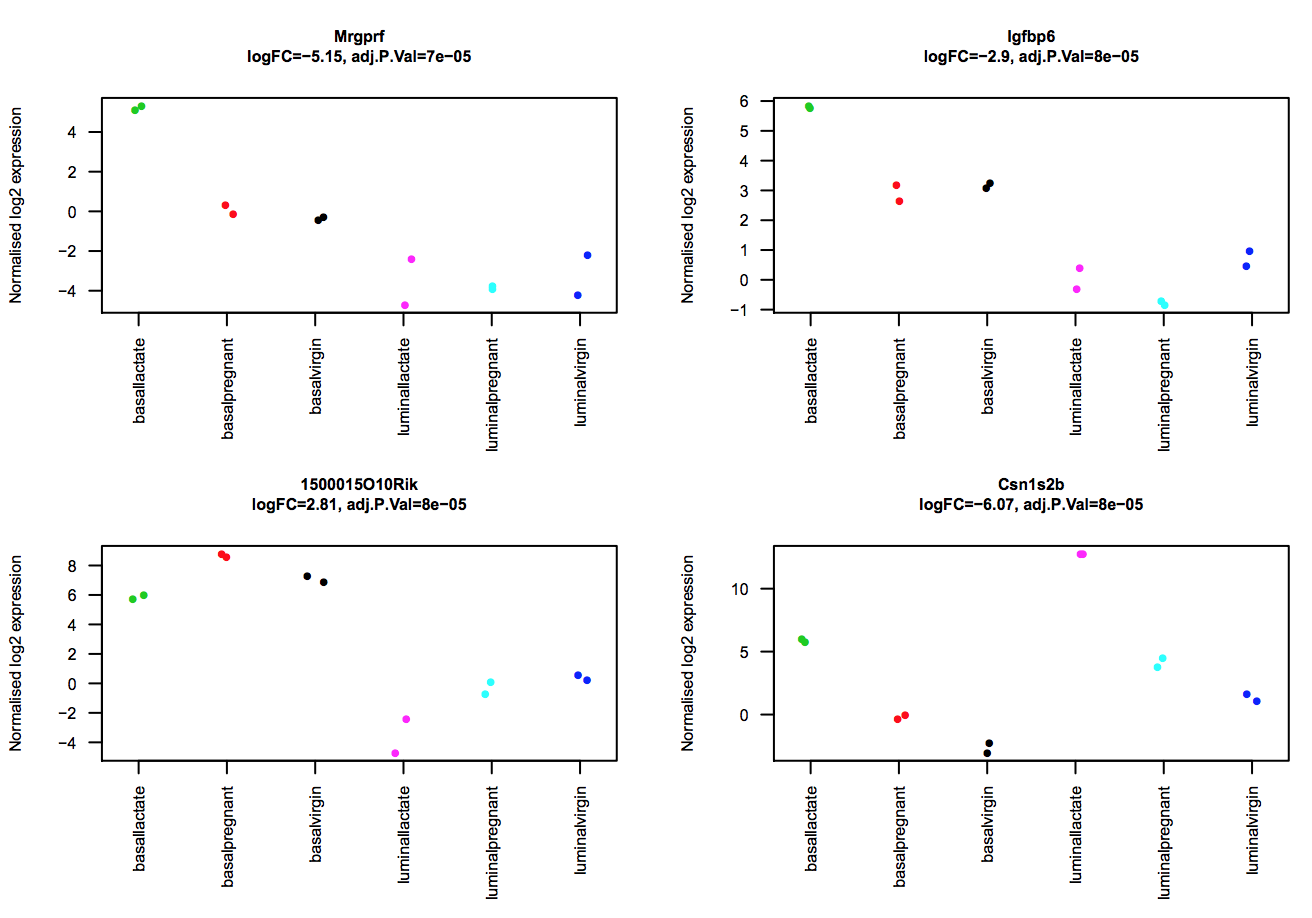 Open image in new tab
Open image in new tabOpen image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
 Open image in new tab
Open image in new tab