Secretome Prediction
Under Development!
This tutorial is not in its final state. The content may change a lot in the next months. Because of this status, it is also not listed in the topic pages.
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How to predict cellular protein localization based upon GO-terms?
How to combine multiple localization predictions?
Requirements:
Predict proteins in the cellular secretome by using GO-terms.
Predict proteins in the cellular secretome by using WolfPSORT.
Combine the results of both predictions.
Time estimation: 30 minutesLevel: Intermediate IntermediateSupporting Materials:Published: Apr 13, 2017Last modification: Apr 8, 2025License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00235version Revision: 15
Secretome Prediction using GO annotations and localization prediction
Introduction
The cellular secretome contains both proteins that are secreted by cells and proteins that are shed from the cellular surface. Here, we describe an approach to predict those proteins in an input list that would be expected in the cellular secretome. This approach combines Gene Ontology (GO) annotation and the WoLF PSORT algorithm for localization prediction.
We chose to include all proteins that are annotated as, or predicted to be, lysosomal proteins. Lysosomal proteins are routinely secreted by malignant and non-malignant cells in high amounts, due to “leakiness” of the mannose-6-phosphate receptor pathway [1,2]. Furthermore, we chose to exclude proteins annotated as being part of extracellular organelles, e.g. exosomes. While exosomes are secreted by malignant and non-malignant cells, exosomal proteins are expected in the secretome at very low amounts, if not especially enriched for.
For secretome prediction, we combine localization data from the Gene Ontology database with a classical protein localization prediction algorithm (WoLF PSORT). The workflow was designed for sensitivity, i.e. a protein predicted by at least one of the used tools will be included in the output. To change this, follow the instructions in the box Comment: Customizing the Workflow below.
Overview
The figure below gives an overview of the Galaxy workflow:
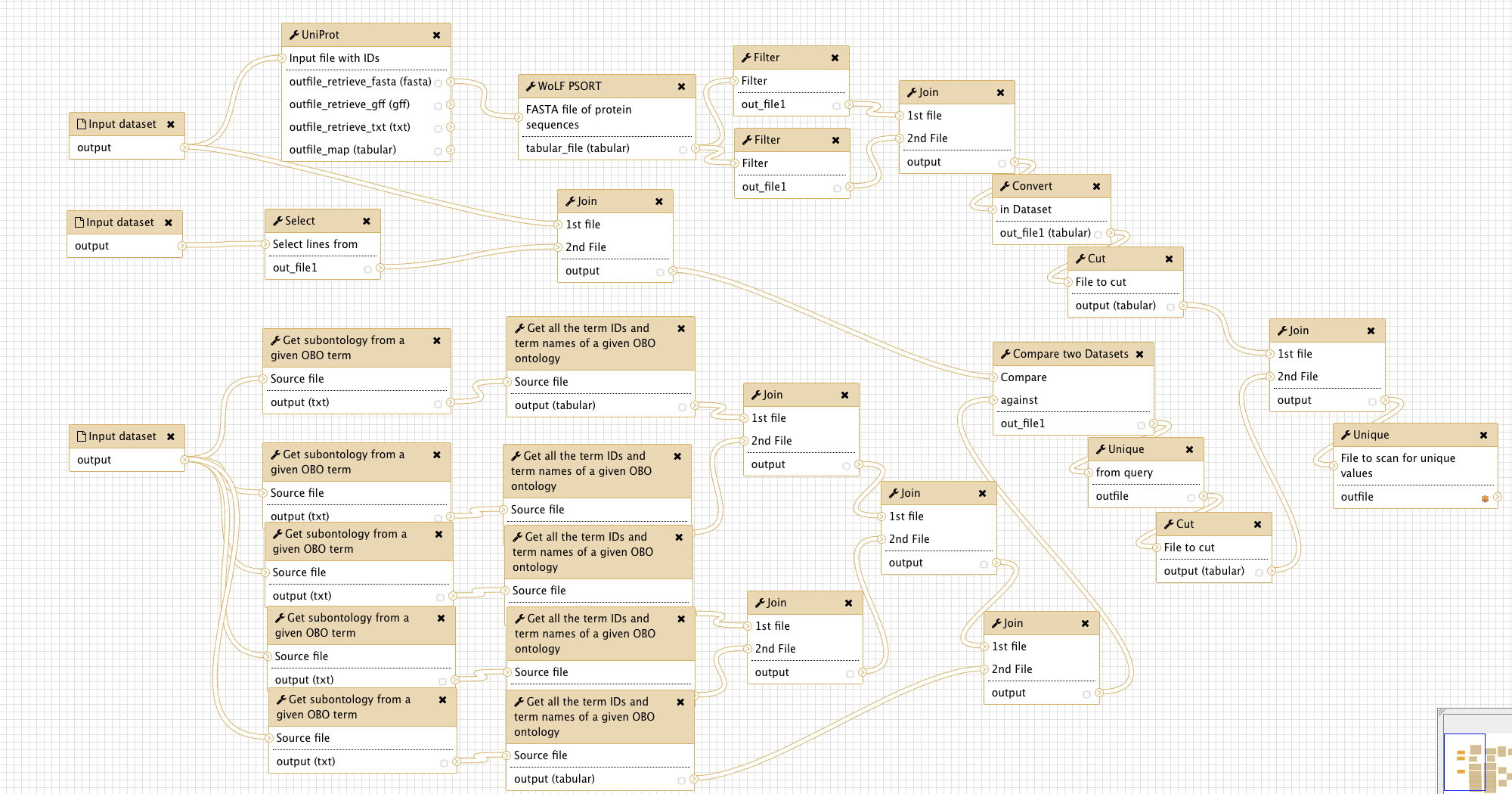
Input
The workflow needs three input files:
-
A tabular file, the first column containing uniprot accession numbers of the proteins of interest. Test data
Comment: Test dataThe provided test dataset for input 1 is a list of human proteins, identified by LC-MS/MS in the cellular supernatant of MDA-MB-231 cells. The dataset was originally published in (Sigloch et al., BBA, 2016).
-
The complete uniprot GO database for the organism of interest, available via FTP. To download the human GOA file needed for the test input, paste the following link to the Galaxy upload tool: ‘ftp://ftp.ebi.ac.uk/pub/databases/GO/goa/HUMAN/goa_human.gaf.gz’
Comment: Uniprot Gene Ontology Association (GOA) files -
The complete GO Open Biomedical Ontology (OBO), i.e. “GO term tree”, accessible at http://purl.obolibrary.org/obo/go/go.obo
Comment: Customizing the WorkflowThis workflow was designed for sensitivity, not for specificity. If you need to increase the specificity, you have the following possibilities, with decreasing efficiency:
- Switch the setting
Output lines appearing inof the last Join tool (last tool before the final Unique tool fromAll lines [-a 1 -a 2]toBoth 1st & 2nd file. Thus, your output will contain only those proteins that are equally predicted by both methods used.- (Only after doing 1.) Adding another way of localization prediction, i.e. another database or another prediction algorithm.
- Replacing WoLF PSORT tool by a more precise localization prediction tool. If you choose this approach, remember that you will probably have to adjust the settings for all tools in the workflow that are processing the WoLF PSORT tool output.
Citation
If you use this workflow directly, or any derivative of it, in work leading to a scientific publication, please cite:
F.C. Sigloch, J.D. Knopf, J. Weißer, A. Gomez-Auli, M.L. Biniossek, A. Petrera, et al., Proteomic analysis of silenced cathepsin B expression suggests non-proteolytic cathepsin B functionality, Biochim. Biophys. Acta - Mol. Cell Res. 1863 (2016) 2700–2709. doi:10.1016/j.bbamcr.2016.08.005. https://www.ncbi.nlm.nih.gov/pubmed/27526672
Literature
[1] B. Schröder, C. Wrocklage, A. Hasilik, P. Saftig, The proteome of lysosomes., Proteomics. 10 (2010) 4053–76. doi:10.1002/pmic.201000196.
[2] J. Reiser, B. Adair, T. Reinheckel, Specialized roles for cysteine cathepsins in health and disease, J. Clin. Invest. 120 (2010) 3421–3431. doi:10.1172/JCI42918.
You've Finished the Tutorial
Key points
The cellular secretome contains more than the classically secreted proteins.
Localization predictions by multiple different algorithms can improve sensitivity and/or specificity.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Florian Christoph Sigloch, Björn Grüning, Secretome Prediction (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/secretome-prediction/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{proteomics-secretome-prediction, author = "Florian Christoph Sigloch and Björn Grüning", title = "Secretome Prediction (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/secretome-prediction/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Funding
These individuals or organisations provided funding support for the development of this resource
Congratulations on successfully completing this tutorial!

You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/proteomics/tutorials/secretome-prediction/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: text_processing owner: bgruening revisions: 288462ec2630 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: 288462ec2630 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: 288462ec2630 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: uniprot_rest_interface owner: bgruening revisions: f7ebd1b4783b tool_panel_section_label: Convert Formats tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: unique owner: bgruening revisions: 7ce75adb93be tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: tmhmm_and_signalp owner: peterjc revisions: e6cc27d182a8 tool_panel_section_label: Annotation tool_shed_url: https://toolshed.g2.bx.psu.edu/