De novo transcriptome reconstruction with RNA-Seq
| Author(s) |
|
| Editor(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
What genes are differentially expressed between G1E cells and megakaryocytes?
How can we generate a transcriptome de novo from RNA sequencing data?
Requirements:
Analysis of RNA sequencing data using a reference genome
Reconstruction of transcripts without reference transcriptome (de novo)
Analysis of differentially expressed genes
- Introduction to Galaxy Analyses
- slides Slides: Quality Control
- tutorial Hands-on: Quality Control
- slides Slides: Mapping
- tutorial Hands-on: Mapping
Time estimation: 6 hoursSupporting Materials:Published: Feb 19, 2017Last modification: Jun 14, 2024License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00289rating Rating: 3.0 (2 recent ratings, 19 all time)version Revision: 36
The data provided here are part of a Galaxy tutorial that analyzes RNA-seq data from a study published by Wu et al. in 2014 DOI:10.1101/gr.164830.113. The goal of this study was to investigate “the dynamics of occupancy and the role in gene regulation of the transcription factor Tal1, a critical regulator of hematopoiesis, at multiple stages of hematopoietic differentiation.” To this end, RNA-seq libraries were constructed from multiple mouse cell types including G1E - a GATA-null immortalized cell line derived from targeted disruption of GATA-1 in mouse embryonic stem cells - and megakaryocytes. This RNA-seq data was used to determine differential gene expression between G1E and megakaryocytes and later correlated with Tal1 occupancy. This dataset (GEO Accession: GSE51338) consists of biological replicate, paired-end, poly(A) selected RNA-seq libraries. Because of the long processing time for the large original files, we have downsampled the original raw data files to include only reads that align to chromosome 19 and a subset of interesting genomic loci identified by Wu et al.
Analysis strategy
The goal of this exercise is to identify what transcripts are present in the G1E and megakaryocyte cellular states and which transcripts are differentially expressed between the two states. We will use a de novo transcript reconstruction strategy to infer transcript structures from the mapped reads in the absence of the actual annotated transcript structures. This will allow us to identify novel transcripts and novel isoforms of known transcripts, as well as identify differentially expressed transcripts.
AgendaIn this tutorial, we will deal with:
Data upload
Due to the large size of this dataset, we have downsampled it to only include reads mapping to chromosome 19 and certain loci with relevance to hematopoeisis. This data is available at Zenodo, where you can find the forward and reverse reads corresponding to replicate RNA-seq libraries from G1E and megakaryocyte cells and an annotation file of RefSeq transcripts we will use to generate our transcriptome database.
Hands On: Data upload
Create a new history for this RNA-seq exercise
To create a new history simply click the new-history icon at the top of the history panel:
- Click on galaxy-pencil (Edit) next to the history name (which by default is “Unnamed history”)
- Type the new name
- Click on Save
- To cancel renaming, click the galaxy-undo “Cancel” button
If you do not have the galaxy-pencil (Edit) next to the history name (which can be the case if you are using an older version of Galaxy) do the following:
- Click on Unnamed history (or the current name of the history) (Click to rename history) at the top of your history panel
- Type the new name
- Press Enter
- Open the data upload manager (Get Data -> Upload file)
- Copy and paste the links for the reads and annotation file
- Select Paste/Fetch Data
- Paste the link(s) into the text field
- Change the datatype of the read files to fastqsanger
- Change the datatype of the annotation file to gtf and assign the Genome as mm10
- Press Start
Rename the files in your history to retain just the necessary information (e.g. “G1E R1 forward reads”)
Import the files from Zenodo
https://zenodo.org/record/583140/files/G1E_rep1_forward_read_%28SRR549355_1%29 https://zenodo.org/record/583140/files/G1E_rep1_reverse_read_%28SRR549355_2%29 https://zenodo.org/record/583140/files/G1E_rep2_forward_read_%28SRR549356_1%29 https://zenodo.org/record/583140/files/G1E_rep2_reverse_read_%28SRR549356_2%29 https://zenodo.org/record/583140/files/Megakaryocyte_rep1_forward_read_%28SRR549357_1%29 https://zenodo.org/record/583140/files/Megakaryocyte_rep1_reverse_read_%28SRR549357_2%29 https://zenodo.org/record/583140/files/Megakaryocyte_rep2_forward_read_%28SRR549358_1%29 https://zenodo.org/record/583140/files/Megakaryocyte_rep2_reverse_read_%28SRR549358_2%29 https://zenodo.org/record/583140/files/RefSeq_reference_GTF_%28DSv2%29You will need to fetch the link to the annotation file yourself ;)
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window


Quality control
For quality control, we use similar tools as described in NGS-QC tutorial: FastQC and Trimmomatic.
Hands On: Quality control
FastQC tool: Run
FastQCon the forward and reverse read files to assess the quality of the reads.Question
- What is the read length?
- Is there anything interesting about the quality of the base calls based on the position in the reads?
- The read length is 99 bp
- The quality of base calls declines throughout a sequencing run.
Trimmomatic tool: Trim off the low quality bases from the ends of the reads to increase mapping efficiency. Run
Trimmomaticon each pair of forward and reverse reads with the following settings:
- “Single-end or paired-end reads?”:
Paired-end (two separate input files)
- param-file “Input FASTQ file (R1/first of pair)”:
G1E_rep1 forward read- param-file “Input FASTQ file (R2/second of pair)”:
G1E_rep1 reverse read- “Perform initial ILLUMINACLIP step?”:
NoFastQC tool: Re-run
FastQCon trimmed reads and inspect the differences.Question
- What is the read length?
- Is there anything interesting about the quality of the base calls based on the position in the reads?
- The read lengths range from 1 to 99 bp after trimming
- The average quality of base calls does not drop off as sharply at the 3’ ends of reads.
Trimmomatic tool: Run
Trimmomaticon the remaining forward/reverse read pairs with the same parameters.
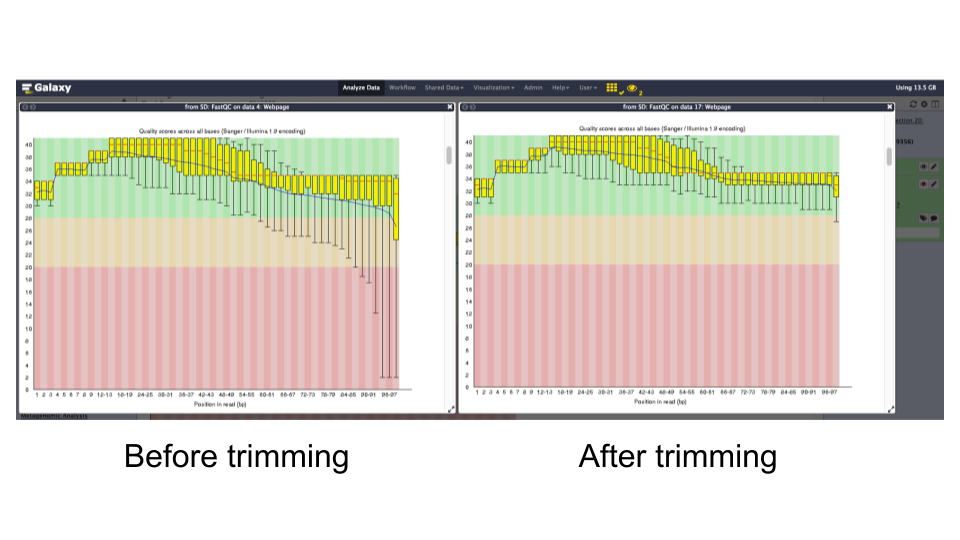
Now that we have trimmed our reads and are fortunate that there is a reference genome assembly for mouse, we will align our trimmed reads to the genome.
CommentInstead of running a single tool multiple times on all your data, would you rather run a single tool on multiple datasets at once? Check out the dataset collections feature of Galaxy!
Mapping
To make sense of the reads, their positions within mouse genome must be determined. This process is known as aligning or ‘mapping’ the reads to the reference genome.
CommentDo you want to learn more about the principles behind mapping? Follow our training
In the case of a eukaryotic transcriptome, most reads originate from processed mRNAs lacking introns. Therefore, they cannot be simply mapped back to the genome as we normally do for reads derived from DNA sequences. Instead, the reads must be separated into two categories:
- Reads contained within mature exons - these align perfectly to the reference genome
- Reads that span splice junctions in the mature mRNA - these align with gaps to the reference genome
Spliced mappers have been developed to efficiently map transcript-derived reads against genomes. HISAT is an accurate and fast tool for mapping spliced reads to a genome. Another popular spliced aligner is TopHat, but we will be using HISAT in this tutorial.
CommentAs it is sometimes quite difficult to determine which settings correspond to those of other programs, the following table might be helpful to identify the library type:
Library type Infer Experiment TopHat HISAT htseq-count featureCounts PE 1++,1–,2+-,2-+ FR Second Strand FR yes 1 PE 1+-,1-+,2++,2– FR First Strand RF reverse 2 SE ++,– FR Second Strand F yes 1 SE +-,-+ FR First Strand R reverse 2 SE,PE undecided FR Unstranded default no 0
Hands On: Spliced mapping
- HISAT2 tool: Run
HISAT2on one forward/reverse read pair and modify the following settings:
- “Source for the reference genome”:
Use a built-in genome
- param-file “Select a reference genome”:
Mouse (Mus Musculus): mm10- “Single-end or paired-end reads?”:
Paired-end
- param-file “FASTA/Q file #1”: Trimmomatic on G1E_rep1 forward read (R1 paired)
- param-file “FASTA/Q file #2”: Trimmomatic on G1E_rep1 reverse read (R2 paired)
- “Specify strand information”:
Forward(FR)- “Advanced options”
- “Spliced alignment options”
- “Penalty for non-canonical splice sites”: ‘3’
- “Penalty function for long introns with canonical splice sites”: ‘Constant [f(x) = B]’’
- “Constant term (B)”: ‘0.0’
- “Penalty function for long introns with non-canonical splice sites”: ‘Constant [f(x) = B]’’
- “Transcriptome assembly reporting”: ‘Report alignments tailored for transcript assemblers including StringTie’
- HISAT2 tool: Run
HISAT2on the remaining forward/reverse read pairs with the same parameters.
De novo transcript reconstruction
Now that we have mapped our reads to the mouse genome with HISAT, we want to determine transcript structures that are represented by the aligned reads. This is called de novo transcriptome reconstruction. This unbiased approach permits the comprehensive identification of all transcripts present in a sample, including annotated genes, novel isoforms of annotated genes, and novel genes. While common gene/transcript databases are quite large, they are not comprehensive, and the de novo transcriptome reconstruction approach ensures complete transcriptome(s) identification from the experimental samples. The leading tool for transcript reconstruction is Stringtie. Here, we will use Stringtie to predict transcript structures based on the reads aligned by HISAT.
Hands On: Transcriptome reconstruction
- Stringtie tool: Run
Stringtieon theHISAT2alignments using the default parameters.
- Use batch mode to run all four samples from one tool form.
- param-file “Specify strand information”:
Forward (FR)
Transcriptome assembly
We just generated four transcriptomes with Stringtie representing each of the four RNA-seq libraries we are analyzing. Since these were generated in the absence of a reference transcriptome, and we ultimately would like to know what transcript structure corresponds to which annotated transcript (if any), we have to make a transcriptome database. We will use the tool Stringtie - Merge to combine redundant transcript structures across the four samples and the RefSeq reference. Once we have merged our transcript structures, we will use GFFcompare to annotate the transcripts of our newly created transcriptome so we know the relationship of each transcript to the RefSeq reference.
Hands On: Transcriptome assembly
- Stringtie-merge tool: Run
Stringtie-mergeon theStringtieassembled transcripts along with the RefSeq annotation file we imported earlier.
- param-file “Transcripts”:
all fourStringtieassemblies- param-file “Reference annotation to include in the merging”:
RefSeq_reference_GTF- GFFCompare tool: Run
GFFCompareon theStringtie-mergegenerated transcriptome along with the RefSeq annotation file.
- param-file “GTF inputs for comparison”:
output of Stringtie-merge- “Use Reference Annotation”:
Yes
- “Choose the source for the reference annotation”:
History
- param-file “Reference Annotation”:
RefSeq_reference_GTF- “Use Sequence Data”:
Yes
- “Choose the source for the reference list”:
Locally cached
- “Using reference genome”: ‘Mouse (Mus Musculus): mm10’
Comment: Note: Transcript categorization used by `GFFcompare`
Class code Transcript category = Annotated in reference j Novel isoform of reference u Intergenic x Anti-sense r Repetitive c Contained in exon of reference s Anti-sense spliced intronic e Single exon transfrag overlapping a reference exon and at least 10 bp of a reference intron, indicating a possible pre-mRNA fragment. i A transfrag falling entirely within a reference intron o Generic exonic overlap with a reference transcript p Possible polymerase run-on fragment (within 2Kbases of a reference transcript)
Analysis of the differential gene expression
We just generated a transriptome database that represents the transcripts present in the G1E and megakaryocytes samples. This database provides the location of our transcripts with non-redundant identifiers, as well as information regarding the origin of the transcript.
We now want to identify which transcripts are differentially expressed between the G1E and megakaryocyte cellular states. To do this we will implement a counting approach using FeatureCounts to count reads per transcript. Then we will provide this information to DESeq2 to generate normalized transcript counts (abundance estimates) and significance testing for differential expression.
Count the number of reads per transcript
To compare the abundance of transcripts between different cellular states, the first essential step is to quantify the number of reads per transcript. FeatureCounts is one of the most popular tools for counting reads in genomic features. In our case, we’ll be using FeatureCounts to count reads aligning in exons of our GFFCompare generated transcriptome database.
The recommended mode is “union”, which counts overlaps even if a read only shares parts of its sequence with a genomic feature and disregards reads that overlap more than one feature.
Hands On: Counting the number of reads per transcript
FeatureCounts tool: Run
FeatureCountson the aligned reads (HISAT2output) using theGFFComparetranscriptome database as the annotation file.
- param-file “Alignment file”:
four HISAT2 aligned read files- “Specify strand information”:
Stranded (Forward)- param-file “Gene annotation file”:
in your history
- “Gene annotation file”:
the annotated transcripts GTF file output by GFFCompare- “Options for paired-end reads”
- “Count fragments instead of reads”:
Enabled; fragments (or templates) wil be counted instead of reads- “Advanced options”
- “GFF gene identifier”:
transcript_id
Perform differential gene expression testing
Transcript expression is estimated from read counts, and attempts are made to correct for variability in measurements using replicates. This is absolutely essential to obtaining accurate results. We recommend having at least two biological replicates.
DESeq2 is a great tool for differential gene expression analysis. It accepts read counts produced by FeatureCounts and applies size factor normalization:
- Computation for each gene of the geometric mean of read counts across all samples
- Division of every gene count by the geometric mean
- Use of the median of these ratios as sample’s size factor for normalization
Hands On
- DESeq2 tool: Run
DESeq2with the following parameters:
- “1: Factor”
- “1: Factor level”:
G1E
- param-file “Counts file(s)”:
featureCount files corresponding to the two G1E replicates- “2: Factor level”:
Mega
- param-file “Counts file(s)”:
featureCount files corresponding to the two Mega replicatesCommentYou can select several files by holding down the CTRL (or COMMAND) key and clicking on the desired files
- “Visualising the analysis results”: Yes
- “Output normalized counts table”: Yes
The first output of DESeq2 is a tabular file. The columns are:
- Gene identifiers
- Mean normalized counts, averaged over all samples from both conditions
- Logarithm (base 2) of the fold change (the values correspond to up- or downregulation relative to the condition listed as Factor level 1)
- Standard error estimate for the log2 fold change estimate
- Wald statistic
- p-value for the statistical significance of this change
- p-value adjusted for multiple testing with the Benjamini-Hochberg procedure which controls false discovery rate (FDR)
Hands On
Filter tool: Run
Filterto extract genes with a significant change in gene expression (adjusted p-value less than 0.05) between treated and untreated samplesQuestionHow many transcripts have a significant change in expression between these conditions?
To filter, use “c7<0.05”. And we get 249 transcripts with a significant change in gene expression between the G1E and megakaryocyte cellular states.
Filter tool: Determine how many transcripts are up or down regulated in the G1E state.
CommentRename your datasets for the downstream analyses
QuestionAre there more upregulated or downregulated genes in the treated samples?
To obtain the up-regulated genes in the G1E state, we filter the previously generated file (with the significant change in transcript expression) with the expression “c3>0” (the log2 fold changes must be greater than 0). We obtain 102 genes (40.9% of the genes with a significant change in gene expression). For the down-regulated genes in the G1E state, we did the inverse and we find 149 transcripts (59% of the genes with a significant change in transcript expression).
In addition to the list of genes, DESeq2 outputs a graphical summary of the results, useful to evaluate the quality of the experiment:
-
Histogram of p-values for all tests
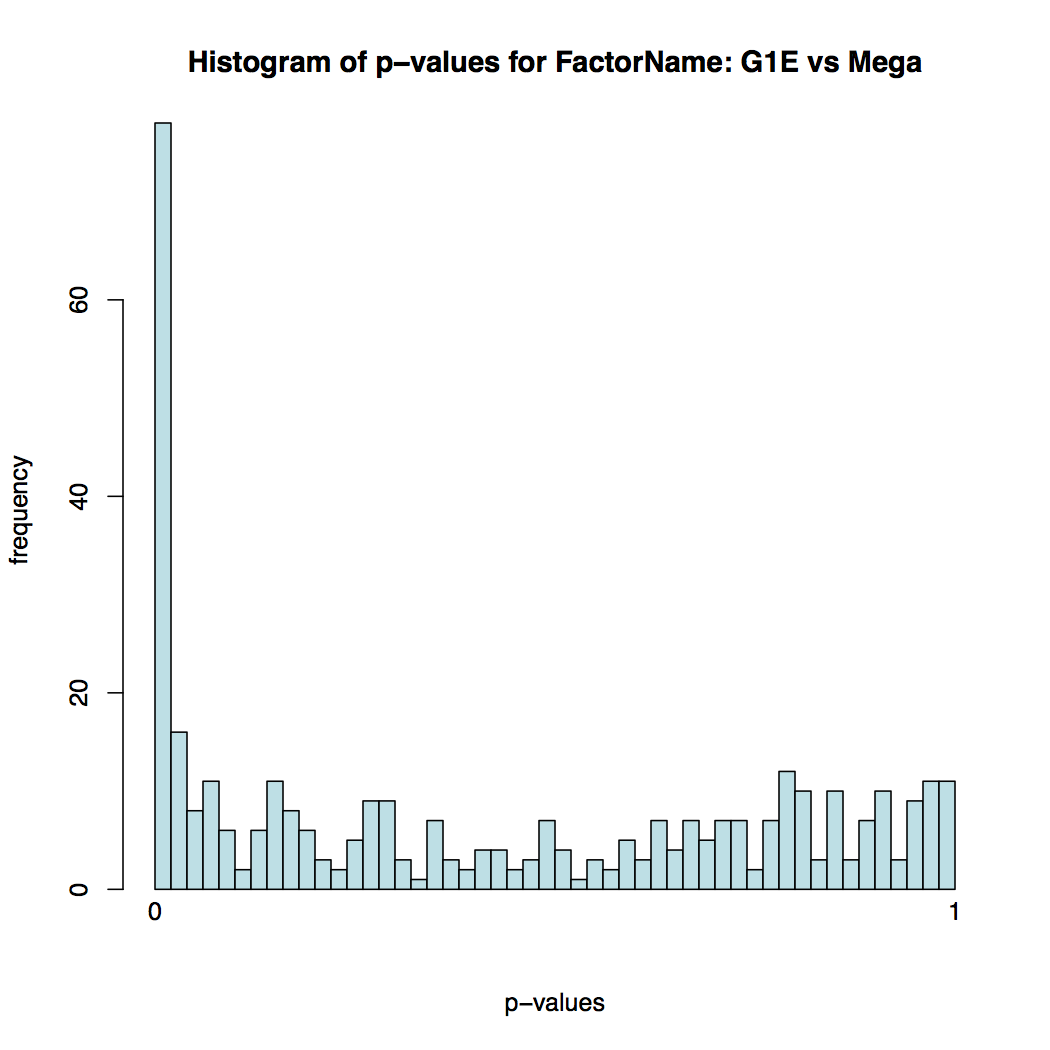
-
MA plot: global view of the relationship between the expression change of conditions (log ratios, M), the average expression strength of the genes (average mean, A), and the ability of the algorithm to detect differential gene expression. The genes that passed the significance threshold (adjusted p-value < 0.1) are colored in red.
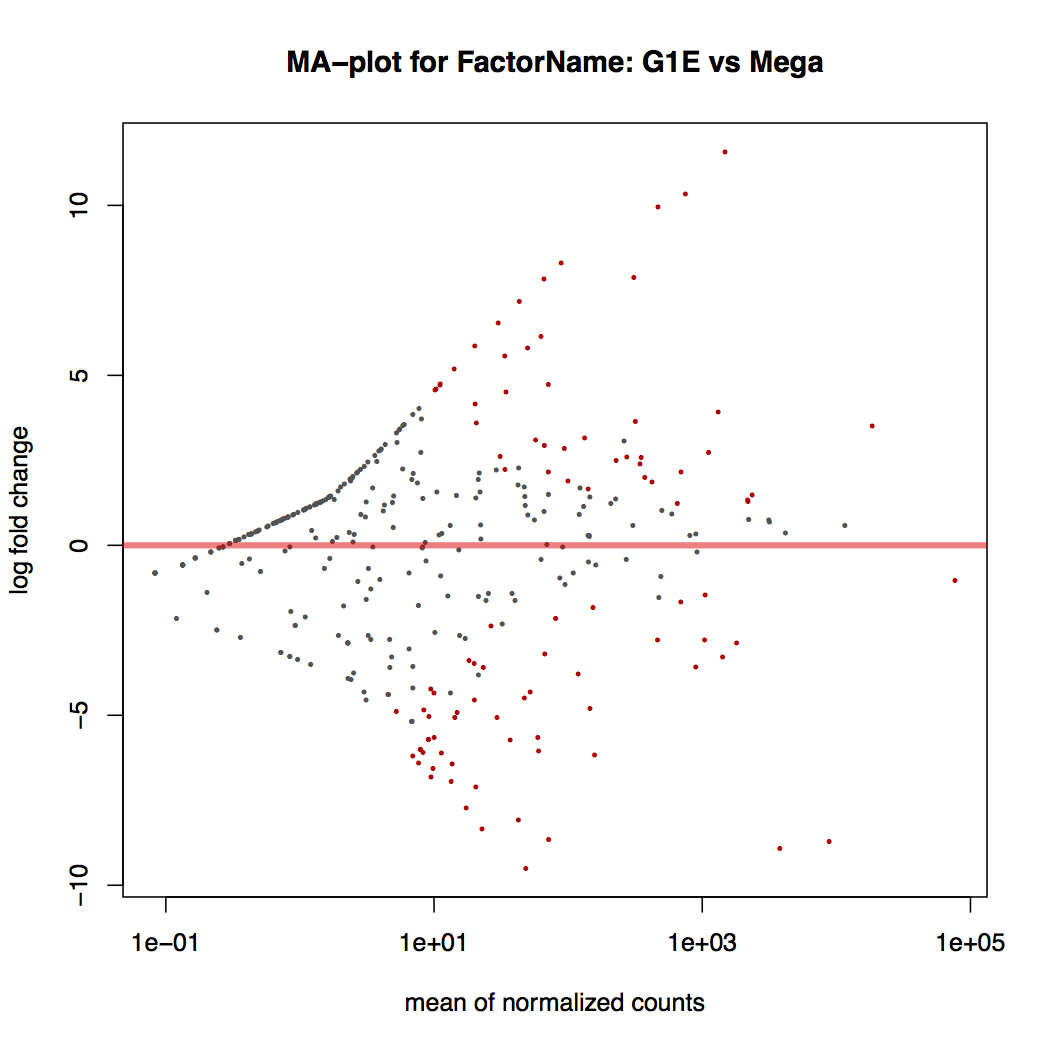
-
Principal Component Analysis (PCA) and the first two axes
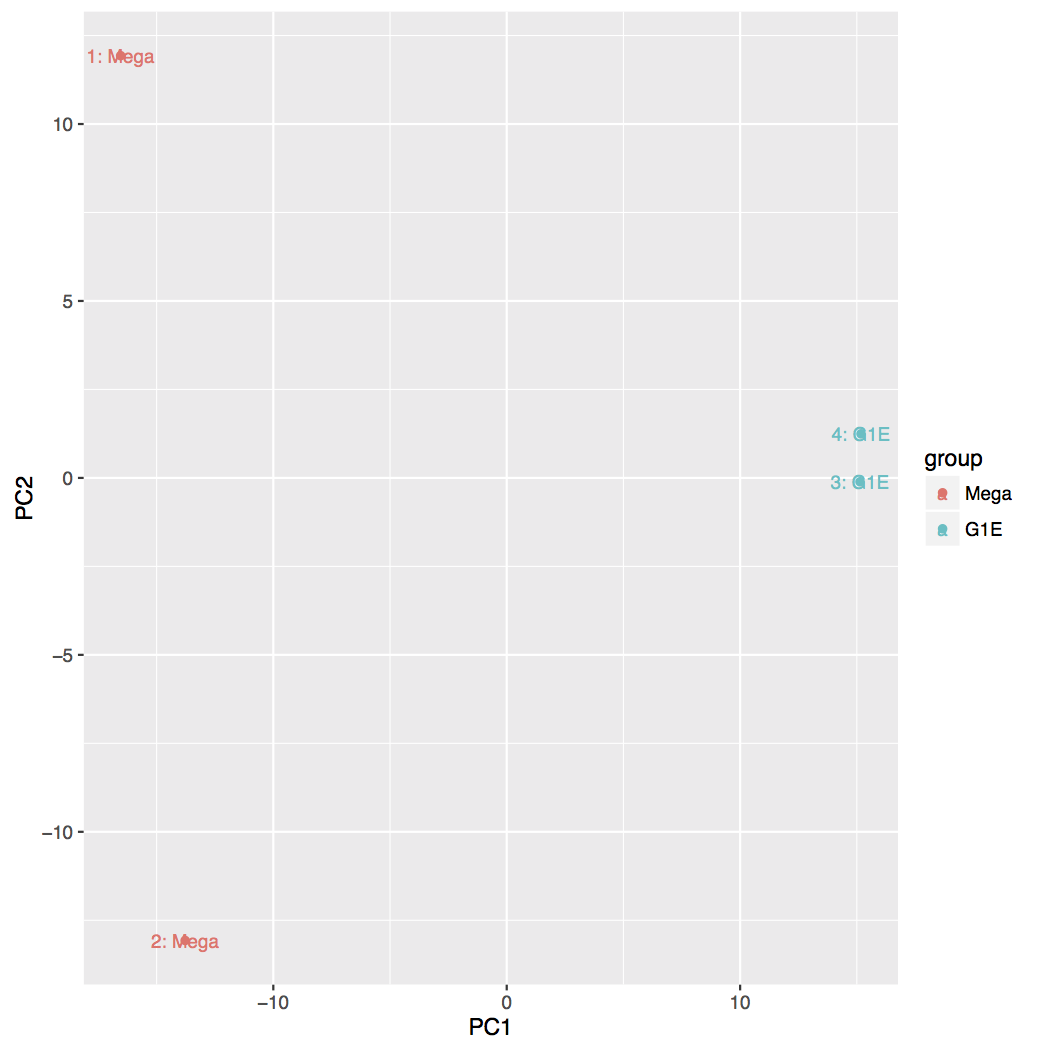
Each replicate is plotted as an individual data point. This type of plot is useful for visualizing the overall effect of experimental covariates and batch effects.
-
Heatmap of sample-to-sample distance matrix: overview over similarities and dissimilarities between samples
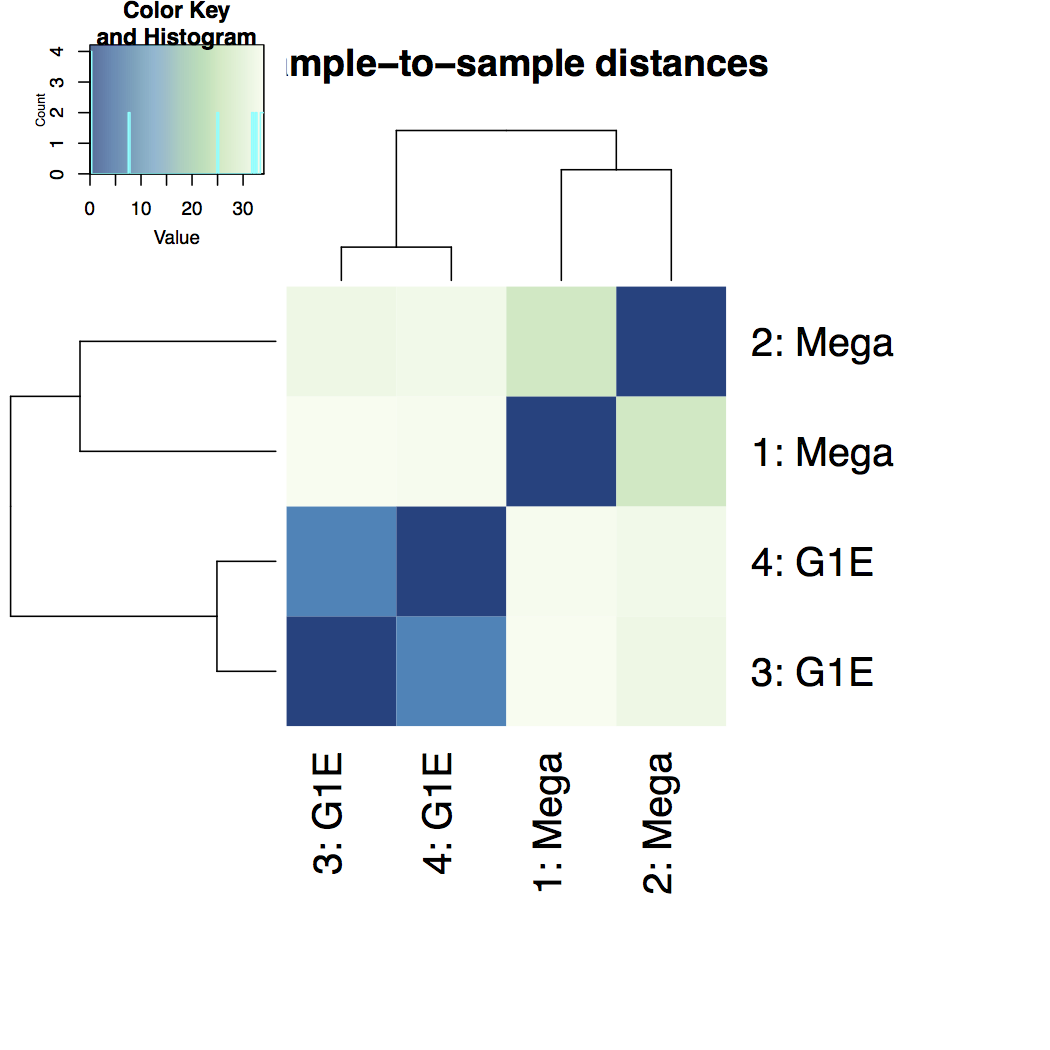
-
Dispersion estimates: gene-wise estimates (black), the fitted values (red), and the final maximum a posteriori estimates used in testing (blue)
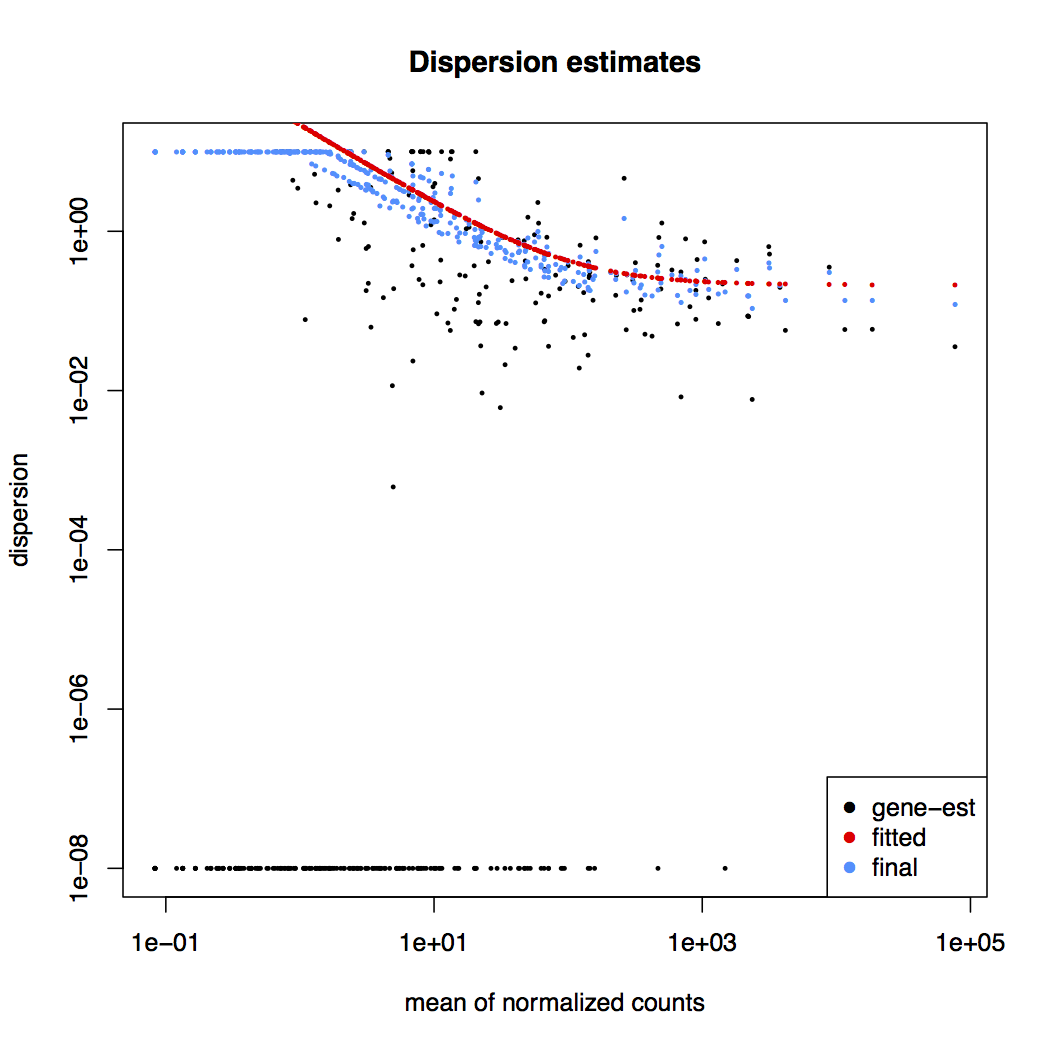
This dispersion plot is typical, with the final estimates shrunk from the gene-wise estimates towards the fitted estimates. Some gene-wise estimates are flagged as outliers and not shrunk towards the fitted value. The amount of shrinkage can be more or less than seen here, depending on the sample size, the number of coefficients, the row mean and the variability of the gene-wise estimates.
For more information about DESeq2 and its outputs, you can have a look at DESeq2 documentation.
Visualization
Now that we have a list of transcript expression levels and their differential expression levels, it is time to visually inspect our transcript structures and the reads they were predicted from. It is a good practice to visually inspect (and present) loci with transcripts of interest. Fortunately, there is a built-in genome browser in Galaxy, Trackster, that make this task simple (and even fun!).
In this last section, we will convert our aligned read data from BAM format to bigWig format to simplify observing where our stranded RNA-seq data aligned to. We’ll then initiate a session on Trackster, load it with our data, and visually inspect our interesting loci.
Hands On: Converting aligned read files to bigWig format
- bamCoverage tool: Run
bamCoverageon all four aligned read files (HISAT2output) with the following parameters:
- “Bin size in bases”: ‘1’
- “Effective genome size”: ‘mm9 (2150570000)’’
- “Advanced options”
- “Only include reads originating from fragments from the forward or reverse strand”: ‘forward’
Rename tool: Rename the outputs to reflect the origin of the reads and that they represent the reads mapping to the PLUS strand.
- bamCoverage tool: Repeat Step 1 except changing the following parameter:
- “Only include reads originating from fragments from the forward or reverse strand”: ‘reverse’
- Rename tool: Rename the outputs to reflect the origin of the reads and that they represent the reads mapping to the MINUS strand.
Hands On: Trackster based visualization
- Viz tool: On the center console at the top of the Galaxy interface, choose “ Visualization” -> “New track browser”
- Name your visualization someting descriptive under “Browser name:”
- Choose “Mouse Dec. 2011 (GRCm38/mm10) (mm10)” as the “Reference genome build (dbkey)
- Click “Create” to initiate your Trackster session
- Viz tool: Click “Add datasets to visualization”
- Select the “RefSeq GTF mm10” file
- Select the output files from
Stringtie- Select the output file from
GFFCompare- Select the output files from
bamCoveragetool: Using the grey labels on the left side of each track, drag and arrange the track order to your preference.
- tool: Hover over the grey label on the left side of the “RefSeq GTF mm10” track and click the “Edit settings” icon.
- Adjust the block color to blue (#0000ff) and antisense strand color to red (#ff0000)
tool: Repeat the previous step on the output files from
StringTieandGFFCompare.- tool: Hover over the grey label on the left side of the “G1E R1 plus” track and click the “Edit settings” icon.
- Adjust the color to blue (#0000ff)
tool: Repeat the previous step on the other three bigWig files representing the plus strand.
- tool: Hover over the grey label on the left side of the “G1E R1 minus” track and click the “Edit settings” icon.
- Adjust the color to red (#ff0000)
tool: Repeat the previous step on the other three bigWig files representing the minus strand.
- tool: Adjust the track height of the bigWig files to be consistent for each set of plus strand and minus strand tracks.
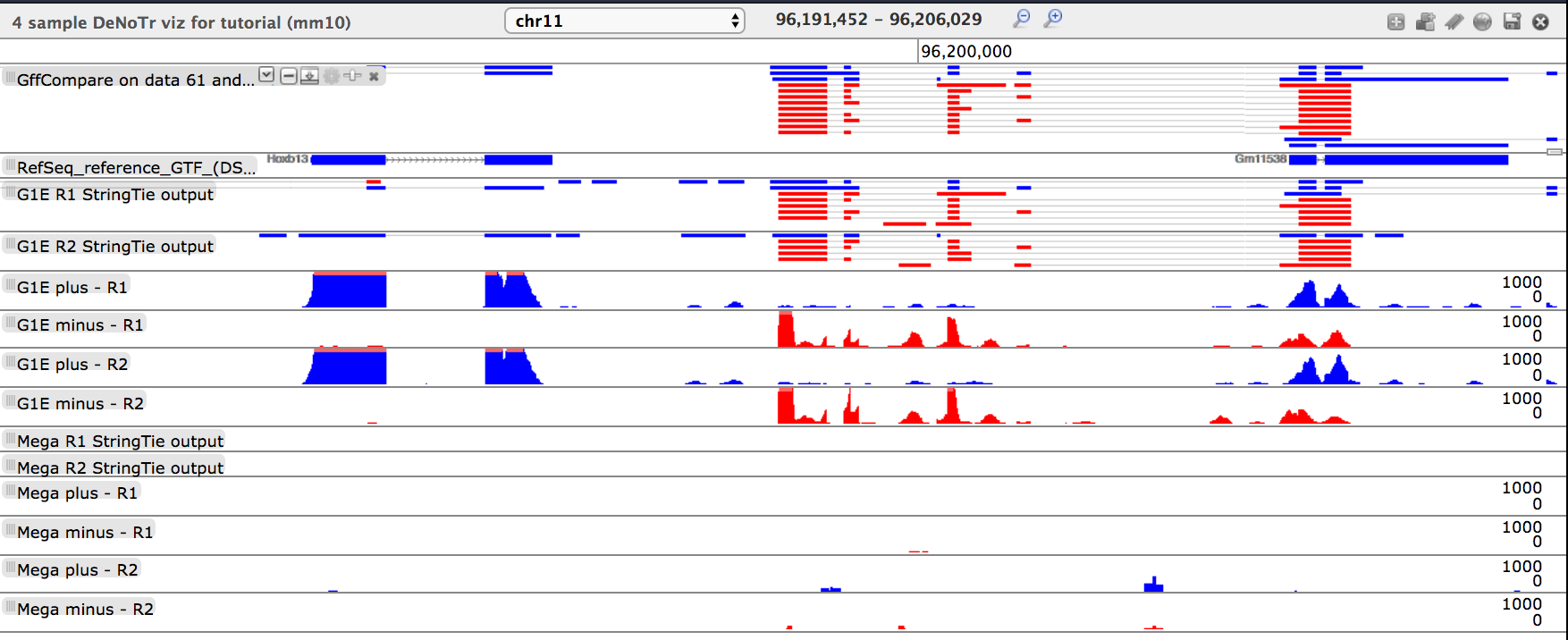
- tool: Direct Trackster to the coordinates: chr11:96191452-96206029, what do you see?
Questionwhat do you see?
- There are two clusters of transcripts that are exclusively expressed in the G1E background
- The left-most transcript is the Hoxb13 transcript
- The center cluster of transcripts are not present in the RefSeq annotation and are determined by
GFFCompareto be “u” and “x”
Conclusion
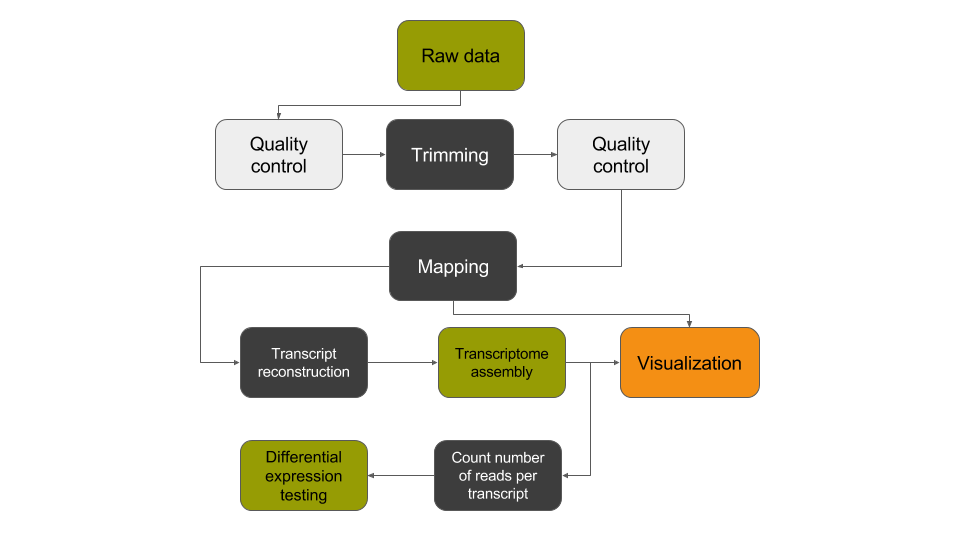
In this tutorial, we have analyzed RNA sequencing data to extract useful information, such as which genes are expressed in the G1E and megakaryocyte cellular states and which of these genes are differentially expressed between the two cellular states. In addition, we identified unannotated genes that are expressed in a cell-state dependent manner and at a locus with relevance to differentiation and development. To identify these transcripts, we analyzed RNA sequence datasets using a de novo transcriptome reconstruction RNA-seq data analysis approach. This approach can be summed up with the following scheme:
You've Finished the Tutorial
Key points
De novo transcriptome reconstruction is the ideal approach for identifying differentially expressed known and novel transcripts.
Differential gene expression testing is improved with the use of replicate experiments and deep sequence coverage.
Visualizing data on a genome browser is a great way to display interesting patterns of differential expression.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Mallory Freeberg, Mo Heydarian, De novo transcriptome reconstruction with RNA-Seq (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/transcriptomics/tutorials/de-novo/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{transcriptomics-de-novo, author = "Mallory Freeberg and Mo Heydarian", title = "De novo transcriptome reconstruction with RNA-Seq (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/transcriptomics/tutorials/de-novo/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/transcriptomics/tutorials/de-novo/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: deeptools_bam_coverage owner: bgruening revisions: 7a7fd0f5f15d tool_panel_section_label: deepTools tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: fastqc owner: devteam revisions: e7b2202befea tool_panel_section_label: FASTA/FASTQ tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: deseq2 owner: iuc revisions: '0696db066a5b' tool_panel_section_label: RNA Analysis tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: featurecounts owner: iuc revisions: a37612abf7f9 tool_panel_section_label: RNA Analysis tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: gffcompare owner: iuc revisions: 0f710191a66d tool_panel_section_label: Filter and Sort tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: hisat2 owner: iuc revisions: a86e80d3c09c tool_panel_section_label: Mapping tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: stringtie owner: iuc revisions: eba36e001f45 tool_panel_section_label: RNA Analysis tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: stringtie owner: iuc revisions: eba36e001f45 tool_panel_section_label: RNA Analysis tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: trimmomatic owner: pjbriggs revisions: 898b67846b47 tool_panel_section_label: FASTA/FASTQ tool_shed_url: https://toolshed.g2.bx.psu.edu/