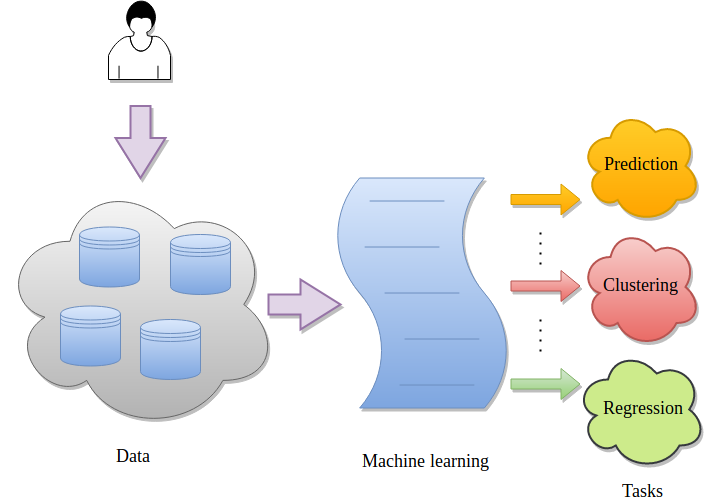
Machine learning uses techniques from statistics, mathematics and computer science to make computer programs learn from data. It is one of the most popular fields of computer science and finds applications in multiple streams of data analysis such as classification, regression, clustering, dimensionality reduction, density estimation and many more. Some real-life applications are spam filtering, medical diagnosis, autonomous driving, recommendation systems, facial recognition, stock prices prediction and many more. The following image shows a basic flow of any machine learning task. Data is provided by a user to a machine learning algorithm for analysis.
There are multiple ways in which machine learning can be used to perform data analysis. They depend on the nature of data and the kind of data analysis. The following image shows the most popular ones. In supervised learning techniques, the categories of data records are known beforehand. But in unsupervised learning, the categories of data records are not known.
The following image shows how a classification task is performed. The complete data is divided into training and test sets. The training set is used by a classifier to learn features. It results in a trained model and its robustness (of learning) is evaluated using the test set (unseen by the classifier during the training).
The datasets required for this tutorial contain 9 features of breast cells which include the thickness of clump, cell-size, cell-shape and so on (more information). In addition to these features, the training dataset contains one more column as target. It has a binary value (0 or 1) for each row. 0 indicates no breast cancer and 1 indicates breast cancer. The test dataset does not contain the target column.
Hands On: Data upload
Create a new history for this tutorial.
To create a new history simply click the new-history icon at the top of the history panel:
Import the following datasets and choose the type of data as tabular.
Figure 5: Training data (breast-w_train) with targets (9 features and one target).Open image in new tab
Figure 6: Test data (breast-w_test) (9 features and no target).
Train a classifier
In this step, we will use the SVM (support vector machine) classifier for training on the breast-w_train dataset. The classifier learns a mapping between each row and its category. SVM is a memory efficient classifier which needs only those data points which lie on the decision boundaries among different classes to predict a class for a new sample. The rest of the data points can be thrown away. We will use the LinearSVC variant of SVM which is faster. Other variants SVC and NuSVC have high running time for large datasets. The last column of the training dataset contains a category/class for each row. The classifier learns a mapping between data row and its category which is called a trained model. The trained model is used to predict the categories of the unseen data.
Hands On: Train a classifier
Support vector machines (SVMs) for classification ( Galaxy version 1.0.11.2) with the following parameters to train:
“Select a Classification Task”: Train a model
“Classifier type”: Linear Support Vector Classification
“Choose how to select data by column”: All columns EXCLUDING some by column header name(s)
“Type header name(s)”: target
param-file“Dataset containing class labels or target values”: breast-w_train tabular file
“Does the dataset contain header”: Yes
“Choose how to select data by column”: Select columns by column header name(s)
“Type header name(s):”: target
Predict using a trained model
The previous step produced a trained model (a zip archive) which we will now use to predict classes for the test data (breast-w_test).
Hands On: Predict using a trained model
Support vector machines (SVMs) for classification ( Galaxy version 1.0.11.2) with the following parameters:
“Select a Classification Task”: Load a model and predict
param-file“Models”: the h5mlm dataset produced by Support vector machines (SVMs) for classificationtool
param-file“Data (tabular)”: breast-w_test file
“Does the dataset contain header”: Yes
“Select the type of prediction”: Predict class labels
See predictions
The last column of the predicted dataset shows the category of each row. A row either got 0 (no breast cancer) or 1 (breast cancer) as its predicted category.
Hands On: See the predicted column
Click on the galaxy-eye (eye) icon of the dataset created by the previous step.
The last column of the table shows the predicted category (target) for each row.
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{statistics-machinelearning,
author = "Anup Kumar",
title = "Basics of machine learning (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/statistics/tutorials/machinelearning/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Funding
These individuals or organisations provided funding support for the development of this resource
5 stars:
Liked: I like the advanced concept of machine learning that helps me to make predictions on test data with the help of trained data using an SVM classifier. It can help me in the future in predicting disease or non-disease conditions.
Disliked: Everything is fine. I hope in the future I will get to learn more new skills related to ML with the help of this training network.
5 stars:
Liked: Support Vector Machines (SVMs) have truly impressed me with their effectiveness in classification tasks. As a student exploring machine learning, I decided to implement SVMs for my classification model, and the results were remarkable. The ability of SVMs to find the optimal hyperplane that maximizes the margin between classes significantly improved my model's accuracy. I was particularly amazed by how well SVMs handled high-dimensional data, allowing me to achieve better performance compared to other algorithms I had tried. This experience has deepened my appreciation for SVMs and their powerful capabilities in tackling complex classification problems.
Disliked: I have diligently followed all the necessary steps to complete this workflow. However, I encountered an issue related to parameter settings, which has resulted in the trained model file from the SVMs for classification (specifically, the linear SVMs) showing no datasets retrieved. Consequently, I am unable to proceed with the prediction step. To ensure a smoother process in the future, I would appreciate any guidance or improvements on this aspect so I can successfully complete the workflow without any hindrances. Thank you for your assistance!
4 stars:
Liked: The Support and ease of using the Tools
Disliked: can Add a video or add a some more notes about silly mistakes
June 2025
4 stars:
Liked: Easy to follow
Disliked: to be more applicable
May 2025
4 stars:
Liked: Step-by-step hands-on procedures to follow
Disliked: Use more simple terms to explain the concepts for beginners
5 stars:
Liked: The easy way to apply ML tools
Disliked: Due to the simplicity of this tutorial, i didn't observe any issue. Everything ran smoothly and they were very understandable
5 stars:
Disliked: maybe adding vidio or secreenshots
4 stars:
Liked: Everything about the course. It's an amazing start.
Disliked: More challenging datasets would be nice
4 stars:
Disliked: The only thing it comes to my mind is to make sure that small changes in the parameters tuning are made very clear. During the parameters loading of the model training everything is the same but the option to "Choose how to select data by column" and someone can oversight the fact that it is different from "Choose how to select data by column"
5 stars:
Liked: I really appreciated the hands-on, code-free interface using Galaxy, which made machine learning accessible even without a programming background. The use of a real-world dataset (breast cancer) was especially meaningful to me as a biomedical science student. It helped bridge the gap between theory and clinical relevance. I also liked the clear step-by-step guidance, the availability of slides, datasets, and pre-built workflows, and the ability to repeat the entire analysis at my own pace. The tutorial strikes a great balance between simplicity and depth, and it’s especially useful for students like me who are exploring AI applications in biomedical research.
Disliked: While the tutorial is very beginner-friendly and well-structured, I believe it could be improved by adding a section that explains the machine learning concepts used in more biological or clinical terms. For example, explaining why Support Vector Machines (SVM) are suited for biomedical data classification or what each feature in the breast cancer dataset biologically represents (like the significance of "clump thickness"). Also, a visual summary of the workflow (maybe a downloadable infographic or flowchart showing each step: input → model training → prediction → evaluation) would help in retaining the big-picture logic. A short video walkthrough or animated explanation might also make it more engaging for visual learners.
February 2024
5 stars:
Liked: very useful for beginners; straightforward
July 2023
5 stars:
Liked: Using Galaxy is not trivial without initial training, but the initial training is simple enough to get everything you need to follow. I have found no other way to acquire bioinformatics expertise in such a wide diversity of tools and analyses in a unified and practical way, just by clicking, and with easy access to any amount of data.
Disliked: Can't say yet.
October 2021
4 stars:
Liked: simple enough to follow
Disliked: It would be nice if a bit more background of machine learning is described.
December 2020
5 stars:
Liked: concise, clear fast to perform
April 2020
5 stars:
Liked: Strict, explicit instructions on what settings to enter into which category, leaving no room for ambiguity.
Disliked: Specifying where exactly to find "Support vector machines (SVMs) for classification". This entry shows up both under Statistics and Machine Learning, and with no immediate indication of which one to use - likely because they're both the same tool.
July 2019
4 stars:
Liked: Easy way to use machine learning
Disliked: maybe more information or link for understand each advanced parameters
March 2019
4 stars:
Liked: This was a helpful example for how machine learning can be applied to a real-world dataset.
Disliked: Add more info on how to access the SVM Classifier tool. This tool does not seem to be available in the US Galaxy instance, but it is available in the EU Galaxy instance.
Questions:
 Open image in new tab
Open image in new tab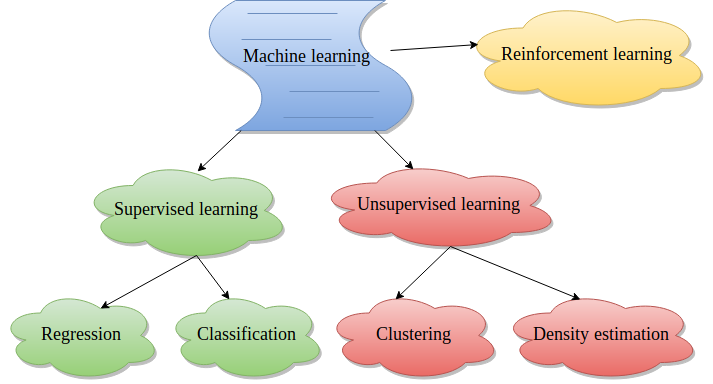 Open image in new tab
Open image in new tab Open image in new tab
Open image in new tab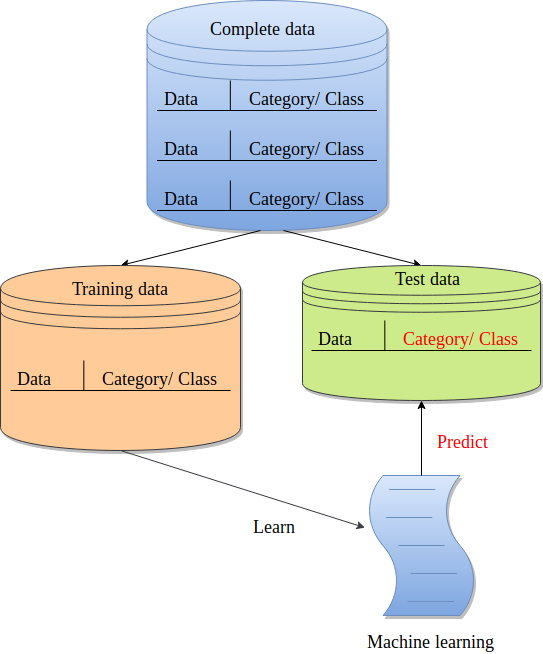 Open image in new tab
Open image in new tabOpen image in new tab
Open image in new tab




