Mass spectrometry: LC-MS analysis
| Author(s) |
|
| Editor(s) | |
| Reviewers |
|
OverviewQuestions:
Objectives:
What are the main steps of untargeted LC-MS data processing for metabolomic analysis?
How to conduct metabolomic data analysis from preprocessing to annotation using Galaxy?
Requirements:
To comprehend the diversity of LC-MS metabolomic data analysis.
To get familiar with the main steps constituting a metabolomic workflow for untargeted LC-MS analysis.
To evaluate the potential of a workflow approach when dealing with LC-MS metabolomic data.
Time estimation: 3 hoursSupporting Materials:
- Datasets
- Workflows
- galaxy-history-answer Answer Histories
- FAQs
- instances Available on these Galaxies
Published: Jul 2, 2019Last modification: Sep 21, 2025License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00195rating Rating: 4.0 (1 recent ratings, 8 all time)version Revision: 13
You may already know that there are different types of -omic sciences; out of these, metabolomics is most closely related to phenotypes. Metabolomics involves the study of different types of matrices, such as blood, urine, tissues, in various organisms including plants. It focuses on studying the very small molecules which are called metabolites, to better understand matters linked to the metabolism. However, studying metabolites is not a piece of cake since it requires several critical steps which still have some major bottlenecks. Metabolomics is still quite a young science, and has many kinds of specific challenges.
One of the three main technologies used to perform metabolomic analysis is Liquid-Chromatography Mass Spectrometry (LC-MS). Data analysis for this technology requires a large variety of steps, ranging from extracting information from the raw data, to statistical analysis and annotation. To be able to perform a complete LC-MS analysis in a single environment, the Wokflow4Metabolomics team provides Galaxy tools dedicated to metabolomics. This tutorial explains the main steps involved in untargeted LC-MS data processing for metabolomic analysis, and shows how to conduct metabolomic data analysis from preprocessing to annotation using Galaxy.
To illustrate this approach, we will use data from Thévenot et al. 2015. The objectives of this paper was to analyze the influence of age, body mass index, and gender on the urine metabolome. To do so, the authors collected samples from 183 employees from the French Alternative Energies and Atomic Energy Commission (CEA) and performed LC-HRMS LTQ-Orbitrap (negative ionization mode) analyses.
Since the original dataset takes a few hours to be processed, we chose to take a limited subset of individuals for this tutorial. This will allow you to perform an example of metabolomic workflow, from pre-processing to annotation, in a limited time, even though the results obtained may not be reliable from a scientific point of view due to the small sample size. Nevertheless, the chosen diversity of sample will allow you to explore the basics of a metabolomic workflow.
We chose a subset of 9 samples, composed of 6 biological samples and 3 quality-control pooled samples (QC pools - mix of all biological samples).
To analyze these data, we will then follow a light version of the LC-MS workflow, developed by the Wokflow4metabolomics group (Giacomoni et al. 2014, Guitton et al. 2017). The workflow is composed of 4 main parts:
- Preprocessing extracts ions from raw data
- Data processing checks the quality of data and transforms it to something relevant
- Statistical Analysis highlights interesting information inside the data
- Annotation puts a name on selected variables
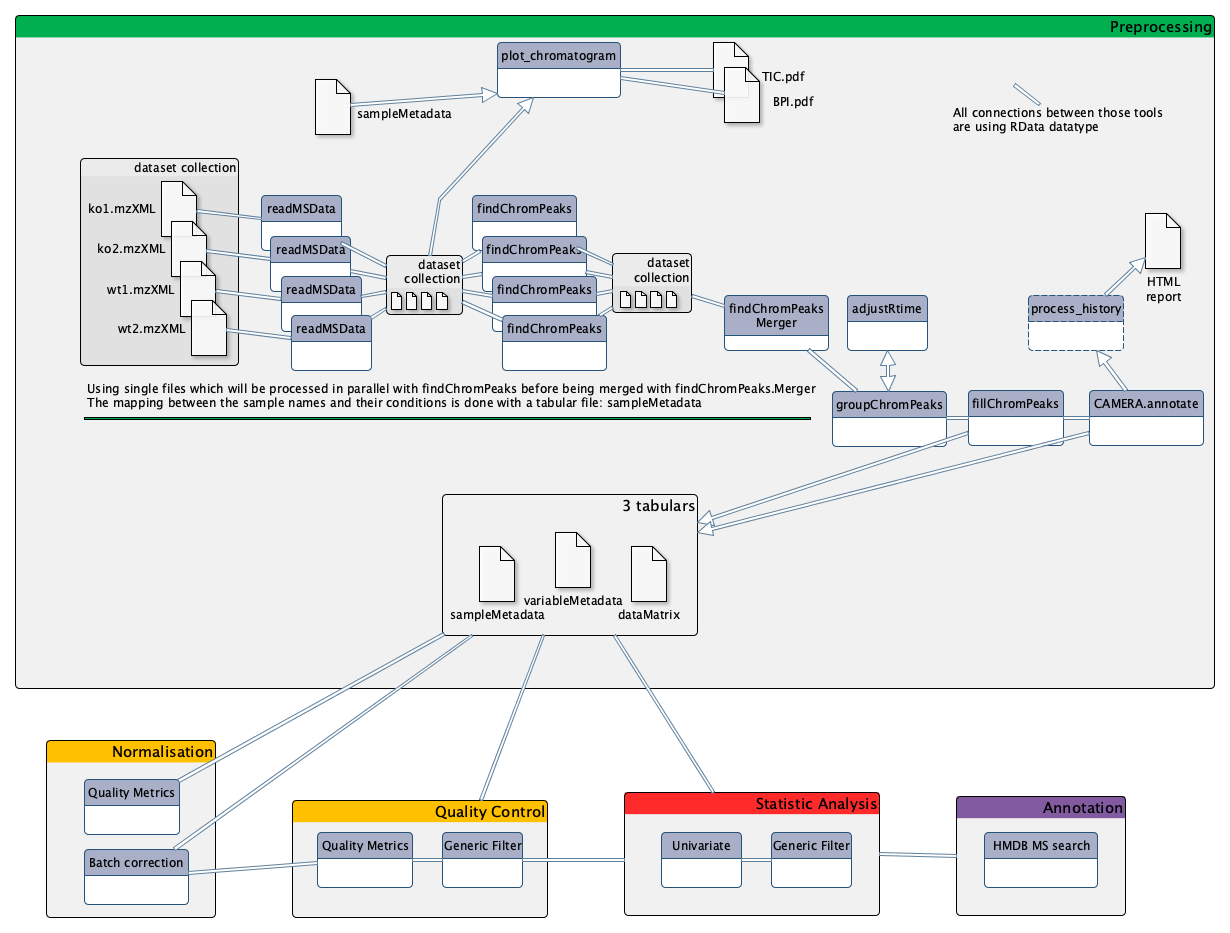
AgendaIn this tutorial, we will cover:
- Preprocessing with XCMS
- Importing the LC/MS data into Galaxy
- Data preparation for XCMS: MSnbase readMSData
- Importing a sample metadata file
- Getting an overview of your samples’ chromatograms
- First XCMS step: peak picking
- Gathering the different samples in one Rdata file
- Second XCMS step: determining shared ions across samples
- Optional XCMS step: retention time correction
- Final XCMS step: integrating areas of missing peaks
- Annotation with CAMERA [Optional]
- Stopover: debriefing and preparation for next steps
- Data processing: quality checks, normalisation, data filtering
- Statistical analysis to find variables of interest
- Annotation
- Conclusion
Preprocessing with XCMS
The first step in the workflow is the pre-processing of the raw data with XCMS (Smith et al. 2006).
XCMS tool is a free and open source software dedicated to pre-processing of any type of mass spectrometry acquisition files from low to high resolution, including FT-MS data coupled with different kind of chromatography (liquid or gas). This software is used worldwide by a huge community of specialists in metabolomics using mass spectrometry methods.
This software is based on different algorithms that have been published, and is provided and maintained using R software.
MSnbase readMSData tool, prior to XCMS tool is able to read files with open format as mzXML, mzMl, mzData and netCDF, which are independent of the constructors’ formats. The XCMS tool package itself is composed of R functions able to extract, filter, align and fill gap, with the possibility to annotate isotopes,
adducts and fragments using the R package CAMERA (Carsten Kuhl 2017). This set of functions gives modularity, and thus is particularly well
adapted to define workflows, one of the key points of Galaxy.
Importing the LC/MS data into Galaxy
In metabolomics studies, the number of samples can vary a lot (from a handful to several hundreds). Thus, extracting your data from the raw files can be very fast, or take quite a long time. To optimise the computation time as much as possible, the W4M core team chose to develop tools that can run single raw files for the first steps of pre-processing in parallel, since the initial actions in the extraction process treat files independently.
Since the first steps can be run on each file independently, the use of Dataset collections in Galaxy is recommended, to avoid having to launch jobs manually for each sample. You can start using the dataset collection option from the very beginning of your analysis, when uploading your data into Galaxy.
Hands On: Data upload the mzXML with Get data
Create a new history for this tutorial
To create a new history simply click the new-history icon at the top of the history panel:
- Import the 9
mzXMLfiles into a collection namedsacurine
- Option 1: from a shared data library (ask your instructor)
- Option 2: from Zenodo using the URLs given below
https://zenodo.org/record/3244991/files/HU_neg_048.mzML https://zenodo.org/record/3244991/files/HU_neg_090.mzML https://zenodo.org/record/3244991/files/HU_neg_123.mzML https://zenodo.org/record/3244991/files/HU_neg_157.mzML https://zenodo.org/record/3244991/files/HU_neg_173.mzML https://zenodo.org/record/3244991/files/HU_neg_192.mzML https://zenodo.org/record/3244991/files/QC1_002.mzML https://zenodo.org/record/3244991/files/QC1_008.mzML https://zenodo.org/record/3244991/files/QC1_014.mzML
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
Click on Collection on the top
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Change Type (set all): from “Auto-detect” to
mzmlPress Start
Click on Build when available
Enter a name for the collection
- sacurine
- Click on Create list (and wait a bit)
As an alternative to uploading the data from a URL or your computer, the files may also have been made available from a shared data library:
- Go into Libraries (left panel)
- Navigate to the correct folder as indicated by your instructor.
- On most Galaxies tutorial data will be provided in a folder named GTN - Material –> Topic Name -> Tutorial Name.
- Select the desired files
- Click on Add to History galaxy-dropdown near the top and select as a Collection from the dropdown menu
In the pop-up window, choose
- “Select history”: the history you want to import the data to (or create a new one)
- Click on Import
- Make sure your data is in a collection. Make sure it is named
sacurine
- If you forgot to select the collection option during import, you can create the collection now:
- Click on galaxy-selector Select Items at the top of the history panel
- Check all the datasets in your history you would like to include
Click n of N selected and choose Advanced Build List
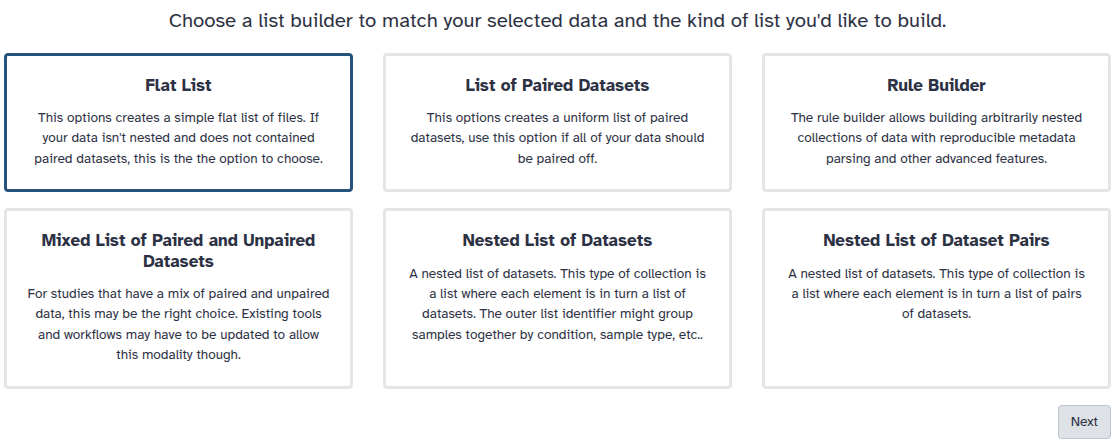
You are in collection building wizard. Choose Flat List and click ‘Next’ button at the right bottom corner.
Double clcik on the file names to edit. For example, remove file extensions or common prefix/suffixes to cleanup the names.
- Enter a name for your collection
- Click Build to build your collection
- Click on the checkmark icon at the top of your history again


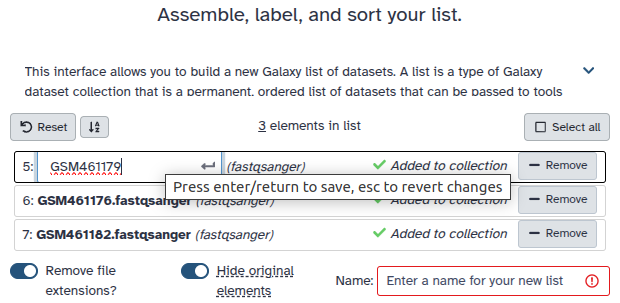
You should have in your history a green Dataset collection (sacurine) with 9 datasets in mzml format.
Their size can be checked by clicking on the information icon galaxy-info on the individual datasets
Data preparation for XCMS: MSnbase readMSData
This first step is only meant to read your mzXML file and generate an object usable by XCMS tool.
MSnbase readMSData tool takes as input your raw files and prepares RData files for the first XCMS step.
Hands On: MSnbase readMSData
- MSnbase readMSData ( Galaxy version 2.16.1+galaxy2) with the following parameters:
- “File(s) from your history containing your chromatograms”: the
sacurinedataset collection
- Click on param-collection Dataset collection in front of the input parameter you want to supply the collection to.
- Select the collection you want to use from the list
QuestionWhat do you get as output?
- A Dataset collection containing 9 dataset.
- The datasets are some RData objects with the rdata.msnbase.raw datatype.
Now that you have prepared your data, you can begin with the first XCMS extraction step: peakpicking. However, before beginning to extract meaningful information from your raw data, you may be interested in visualising your chromatograms. This can be of particular interest if you want to check whether you should consider discarding some range of your analytical sequence (some scan or retention time (RT) ranges).
To do so, you can use a tool that is called xcms plot chromatogram tool that will plot each sample’s chromatogram (see dedicated section further). However, to use this tool, you may need additional information about your samples for colouring purpose. Thus, you may need to upload into Galaxy a table containing metadata of your samples (a sampleMetadata file).
Importing a sample metadata file
What we referenced here as a sampleMetadata file corresponds to a table containing information about your samples (= sample metadata).
A sample metadata file contains various information for each of your raw files:
- Classes which will be used during the preprocessing steps
- Analytical batches which will be useful for a batch correction step, along with sample types (pool/sample) and injection order
- Different experimental conditions which can be used for statistics
- Any information about samples that you want to keep, in a column format
The content of your sample metadata file has to be filled by you, since it is not contained in your raw data. Note that you can either:
- Upload an existing metadata file
- Use a template to create one (because it can be painful to get the sample list without misspelling or omission)
- Generate a template with the xcms get a sampleMetadata file tool tool
- Fill it using your favorite table editor (Excel, LibreOffice etc.)
- Upload it within Galaxy
In the case of this tutorial, we already prepared a sampleMetadata file with all the necessary information. Below is an optional hands-on explaining how to get a template to fill, with the two following advantages:
- You will have the exact list of the samples you used in Galaxy, with the exact identifiers (i.e. exact sample names)
- You will have a file with the right format (tabulation-separated text file) that only needs to be filled with the information you want.
Hands On: xcms get a sampleMetadata file
- xcms get a sampleMetadata file ( Galaxy version 3.12.0+galaxy1) with the following parameters:
- param-collection “RData file”: the
sacurine.raw.RDatacollection output from MSnbase readMSData toolAn easy step for an easy sampleMetadata filling!
From this tool, you will obtain a
tabularfile (meaning a tab-separated text file) with a first column of identifiers and a second column called class which is empty for the moment (only ‘.’ for each sample). You can now download this file by clicking on the galaxy-save icon.
Prepare your sampleMetadata file
The sampleMetadata file is a tab-separated table, in text format. This table has to be filled by the user. You can use any software you find appropriate to construct your table, as long as you save your file in a compatible format. For example, you can use a spreadsheet software such as Microsoft Excel or LibreOffice.
Warning: Important: Save your table in the correct formatThe file has to be a
.txtor a.tsv(tab-separated values). Neither.xlsxnor.odtare supported. If you use a spreadsheet software, be sure to change the default format to Text (Tab delimited) or equivalent.
Once your sampleMetadata table is ready, you can proceed to the upload. In this tutorial we already prepared the table for you ;)
For this tutorial, we already provide the sampleMetadata file, so you only have to upload it to Galaxy. Below we explain how we filled this file from the template we generated in Galaxy.
First, we used xcms get a sampleMetadata file tool as mentioned in the previous tip box.
We obtained the following table:
sample_name class QC1_014 . QC1_008 . QC1_002 . HU_neg_192 . HU_neg_173 . HU_neg_157 . HU_neg_123 . HU_neg_090 . HU_neg_048 . We used a spreadsheet software to open the file. First, we completed the class column. You will see in further XCMS steps that this second column matters.
sample_name class QC1_014 QC QC1_008 QC QC1_002 QC HU_neg_192 sample HU_neg_173 sample HU_neg_157 sample HU_neg_123 sample HU_neg_090 sample HU_neg_048 sample With this column, we will be able to colour the samples depending on the sample type (QC or sample). Next, we added columns with interesting or needed information, as following:
sample_name class polarity sampleType injectionOrder batch osmolality sampling age bmi gender QC1_014 QC 0 pool 185 ne1 NA NA NA NA NA QC1_008 QC 0 pool 105 ne1 NA NA NA NA NA QC1_002 QC 0 pool 27 ne1 NA NA NA NA NA HU_neg_192 sample 0 sample 165 ne1 1184 8 31 24.22 Male HU_neg_173 sample 0 sample 148 ne1 182 7 55 20.28 Female HU_neg_157 sample 0 sample 137 ne1 504 7 43 21.95 Female HU_neg_123 sample 0 sample 100 ne1 808 5 49 24.39 Male HU_neg_090 sample 0 sample 75 ne1 787 4 46 19.79 Male HU_neg_048 sample 0 sample 39 ne1 997 3 39 19.49 Female In particular, the
batch,sampleTypeandinjectionOrdercolumns are mandatory to correct the data from signal drift (see later in the tutorial). Once we completed the table filling, we saved the file, minding to stick with the original format. Then, our sampleMetadata was ready to be uploaded into Galaxy.
Upload the sampleMetada file with ‘Get data’
Hands On: Upload the sampleMetada
- Import the
sampleMetadata_completed.tsvfile from Zenodo or from a shared data library (ask your instructor)https://zenodo.org/record/3244991/files/sampleMetadata_completed.tsv
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window
As an alternative to uploading the data from a URL or your computer, the files may also have been made available from a shared data library:
- Go into Libraries (left panel)
- Navigate to the correct folder as indicated by your instructor.
- On most Galaxies tutorial data will be provided in a folder named GTN - Material –> Topic Name -> Tutorial Name.
- Select the desired files
- Click on Add to History galaxy-dropdown near the top and select as Datasets from the dropdown menu
In the pop-up window, choose
- “Select history”: the history you want to import the data to (or create a new one)
- Click on Import
- Check the data type of your imported files.
- The datatype should be
tabular, if this is not the case, please change the datatype now
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select your desired datatype from “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button
CommentHere we provided the sampleMetadata file so we know that the upload led to a ‘tabular’ file. But from experience we also know that it can happen that, when uploading a sampleMetadata table, a user obtains other inappropriate types of data. This is generally due to the file not following all the requirements about the format (e.g. wrong separator, or lines with different numbers of columns). Thus, we highly recommend that you always take a second to check the data type after the upload. This way you can handle the problem right away if you happen to get one of these obvious issues.
Rename your sampleMetadata file with a shorter name ‘sampleMetadata_completed.tsv’
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, change the Name field
- Click the Save button

Question
- How many columns should I have in my sampleMetadata file?
- What kind of class can I have?
- At least 2, with the identifiers and the class column. But as many as you need to describe the potential variability of your samples (e.g. the person in charge of the sample preparation, the temperature…). The statistical analysis will expose the relevant parameters.
- Sample, QC, blank… The class (the 2nd column) is useful for the preprocessing step with XCMS to detect the metabolite across the samples. So it can be important to separate very different types of samples, as biological ones and blank ones for example. If you don’t have any specific class that you want to consider in XCMS preprocessing, just fill everywhere with
sampleor a dot.for example.
Getting an overview of your samples’ chromatograms
You may be interested in getting an overview of what your samples’ chromatograms look like, for example to see if some of your samples have distinct overall characteristics, e.g. unexpected chromatographic peaks or huge overall intensity.
You can use the sampleMedata file we previously uploaded to add some group colours to your samples when visualising your chromatograms. The tool automatically takes the second column as colour groups when a file is provided.
Note that you can also check the chromatograms at any moment during the workflow, in particular at the following steps:
- After MSnbase readMSData tool to help you to define retention time ranges that you may want to discard from the very beginning (“Specta Filters” in findChromPeaks tool)
- After adjustRtime tool to check the result of the correction (and potentially rerun adjustRtime with other settings)
Hands On: xcms plot chromatogram
- xcms plot chromatogram ( Galaxy version 3.12.0+galaxy1) with the following parameters:
- “RData file”:
sacurine.raw.RData(collection)- “Sample metadata file”:
sampleMetadata_completed.tsvyou uploaded previously
- Click on param-collection Dataset collection in front of the input parameter you want to supply the collection to.
- Select the collection you want to use from the list
CommentIf you use this tool at a later step of XCMS workflow while having provided, in the Merger step (see further in this tutorial), a sampleMetadata with a second column containing groups, you will get colouring according to these groups even without providing a sampleMetadata file as a ‘plot chromatogram’ parameter.
This tool generates Base Peak Intensity Chromatograms (BPIs) and Total Ion Chromatograms (TICs). If you provide groups as we do here, you obtain two plots: one with colours based on provided groups, one with one colour per sample.
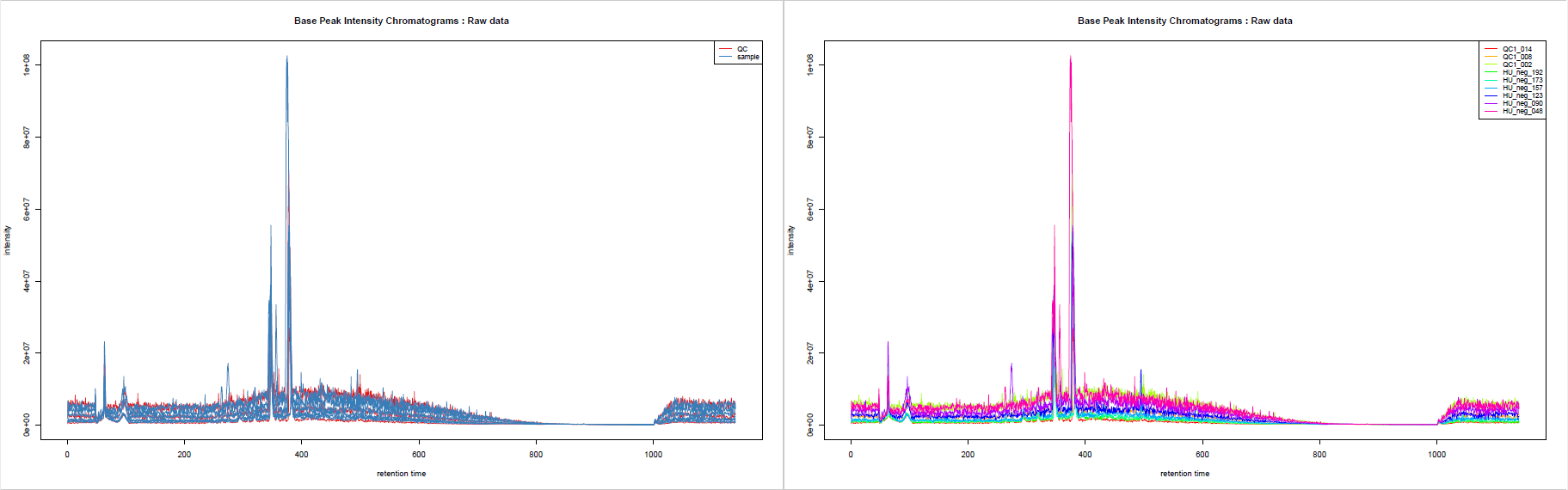
First XCMS step: peak picking
Now that your data is ready for XCMS processing, the first step is to extract peaks from each of your data files independently. The idea here is, for each peak, to proceed to chromatographic peak detection.
The XCMS solution provides two different algorithms to perform chromatographic peak detection: matchedFilter and centWave. The matchedFilter strategy is the first one provided by the XCMS R package. It is compatible with any LC-MS device, but was developed at a time when high resolution mass spectrometry was not common standard yet. On the other side, the centWave algorithm (Tautenhahn et al. 2008) was specifically developed for high resolution mass spectrometry, dedicated to data in centroid mode. In this tutorial, you will practice using the centWave algorithm.
Comment: How the centWave algorithm worksRemember that these steps are performed for each of your data files independently.
- Firstly, the algorithm detects series of scans with close values of m/z. They are called ‘region of interest’ (ROI). The m/z deviation is defined by the user. The tolerance value should be set according to the mass spectrometer accuracy.
- On these regions of interest, a second derivative of a Gaussian model is applied to these consecutive scans in order to define the extracted ion chromatographic peak. The Gaussian model is defined by the peak width which corresponds to the standard deviation of the Gaussian model. Depending on the shape, the peak is added to the peak list of the current sample.
At the end of the algorithm, a list of peaks is obtained for each sample. This list is then considered to represent the content of your sample; if an existing peak is not considered a peak at this step, then it can not be considered in the next steps of pre-processing.
Let’s try performing the peakpicking step with the xcms findChromPeaks (xcmsSet) tool
Hands On: xcms findChromPeaks (xcmsSet)
- xcms findChromPeaks (xcmsSet) ( Galaxy version 3.12.0+galaxy1) with the following parameters:
- “RData file”:
sacurine.raw.RData(collection)- “Extraction method for peaks detection”:
CentWave - chromatographic peak detection using the centWave method
- “Max tolerated ppm m/z deviation in consecutive scans in ppm”:
3- “Min,Max peak width in seconds”:
5,20- In Advanced Options:
- “Prefilter step for for the first analysis step (ROI detection)”:
3,5000- “Noise filter”:
1000You can leave the other parameters with their default values.
CommentAlong with the parameters used in the core centWave algorithm, XCMS provides other filtering options allowing you to get rid of ions that you don’t want to consider. For example, you can use Spectra Filters allowing you to discard some RT or M/z ranges, or Noise filter (as in this hands-on) not to use low intensity measures in the ROI detection step.
At this step, you obtain a dataset collection containing one RData file per sample, with independent lists of ions. Although this
is already a nice result, what you may want now is to get all this files together to identify which ions are shared between samples.
To do so, XCMS provides a function that is called groupChromPeaks (or group). But before proceeding to this grouping step, first you
need to group your individual RData files into a single one.
Gathering the different samples in one Rdata file
A dedicated tool exists to merge the different RData files into a single one: xcms findChromPeaks Merger tool. Although you can simply take as
input your dataset collection alone, the tool also provides de possibility to take into account a sampleMetadata file. Indeed,
depending of your analytical sequence, you may want to treat part of your samples a different way when proceeding to the grouping step using xcms groupChromPeaks (group) tool.
This can be the case for example if you have in your analytical sequence some blank samples (your injection solvent) that you want to extract along with your biological samples to be able to use them as a reference for noise estimation and noise filtering. The fact that these blank samples have different characteristics compared to your biological samples can be of importance when setting parameters of your grouping step. You will see what this is all about in the ‘grouping’ section of this tutorial, but in the workflow order, it is at this step that you need to provide the needed information if you want distinction in your grouping step.
In the case of our tutorial data, we do not want to separate the samples according to groups, so we do not provide the sampleMetadata when executing the Merger tool.
Hands On: xcms findChromPeaks Merger
- xcms findChromPeaks Merger ( Galaxy version 3.12.0+galaxy1) with the following parameters:
- “RData file”:
sacurine.raw.xset.RData(collection)- “Sample metadata file”:
Nothing selected
- Click on param-collection Dataset collection in front of the input parameter you want to supply the collection to.
- Select the collection you want to use from the list
The tool generates a single RData file containing information from all the samples in your dataset collection input.
Second XCMS step: determining shared ions across samples
The first peak picking step gave us lists of ions for each sample. However, what we want now is a single matrix of ions intensities for all samples. To obtain such a table, we need to determine, among the individual ion lists, which ions are the same. This is the aim of the present step, called ‘grouping’.
The group function aligns ions extracted with close retention time and close m/z values in the different samples. In order to define this similarity, we have to define on one hand a m/z window and on the other hand a retention time window. A binning is then performed in the mass domain. The size of the bins is called width of overlapping m/z slices. You have to set it according to your mass spectrometer resolution.
Then, a kernel density estimator algorithm is used to detect region of retention time with high density of ions. This algorithm uses a Gaussian model to group together peaks with similar retention time.
The inclusion of ions in a group is defined by the standard deviation of the Gaussian model, called bandwidth. This parameter has a large weight on the resulting matrix. It must be chosen according to the quality of the chromatography. To be valid, the number of ions in a group must be greater than a given number of samples. Either a percentage of the total number of samples or an absolute value of samples can be given. This is defined by the user.
Hands On: xcms groupChromPeaks (group)
- xcms groupChromPeaks (group) ( Galaxy version 3.12.0+galaxy1) with the following parameters:
- “RData file”:
xset.merged.RData- “Method to use for grouping”:
PeakDensity - peak grouping based on time dimension peak densities
- “Bandwidth”:
5.0- “Width of overlapping m/z slices”:
0.01
This grouping step is very important because it defines the data matrix which will be used especially for the statistical analyses. User has to check the effect of parameter values on the result.
In order to check the result of the grouping function, a pdf file is created. It provides one plot per m/z slice found in the data. Each picture represents the peak density across samples, plotting the corresponding Gaussian model which width is defined by the bandwidth parameter. Each red dot corresponds to a sample. The plot allows to assess the quality of alignment. The grey areas’ width is associated with the bandwidth parameter.
Here is an example of two m/z slides obtained from the hands-on:
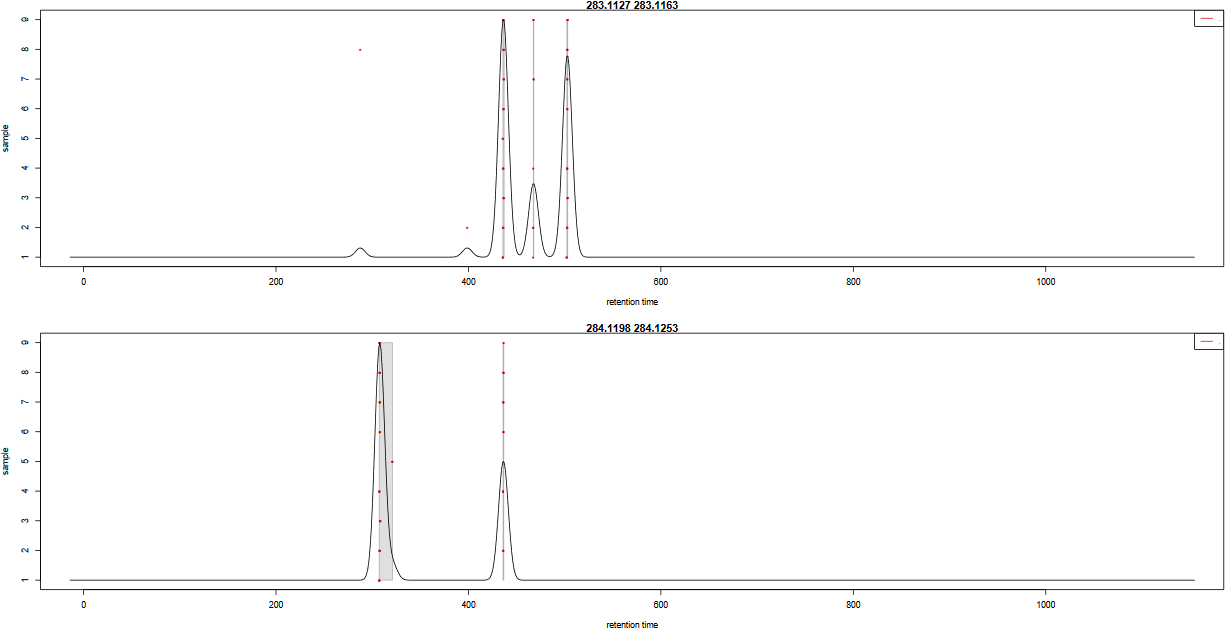
Question
- Look at the
283.1127 - 283.1163m/z slice. How many peak groups are considered? Can you explain why some peaks are not affected to peak groups?- Look at the
284.1198 - 284.1253m/z slice. What do you think could have happened if you had used a smaller bandwidth value?
- There are 3 peak groups in this m/z slice. The two peaks that are not assigned to peak groups are alone in their retention time area. Thus, the number of samples under the corresponding density peaks does not reach the minimum fraction of samples set by the user (0.5) to consider a peak group.
- If the bandwidth value had been set to a smaller value, the density peak width would have been smaller. With a small-enough bandwidth value, there could have been two density peaks instead of one under the current first density peak. Thus, the sample in line 5 would have been out of the previous peak group, thus not assigned to any peak group due to the 0.5 minimum fraction limit.
When looking at the plots from plotChromPeakDensity.pdf, we can notice that in some cases there seems to be a small drift of retention time for some samples. This phenomenon is well known with LC-MS techniques. To be able to attribute correct groups for peaks, it may be needed to perform some retention time correction accross samples. Thus, the idea is (when needed) to apply a retention time strategy on the output of your grouping step, then to perform a second grouping step on the corrected data.
Optional XCMS step: retention time correction
Sometimes with LC-MS techniques, a deviation in retention time occurs from a sample to another. In particular, this is likely to be observed when you inject large sequences of samples.
This optional step aims to correct retention time drift for each peak among samples. The correction is based on what is called well behaved peaks, that are peaks found in all samples or at least in most of the samples.
Sometimes it is difficult to find enough peaks present in all samples. The user can define a percentage of the total number of samples in which a peak should be found to be considered a well behaved peak. This parameter is called minimum required fraction of samples.
On the contrary, you may have peak groups with more detected peaks than the total number of samples. Those peaks are called additional peaks. If you do not want to consider peak groups with too much additional peaks as ‘well behaved peaks’, you can use the ‘maximal number of additional peaks’ parameter to put them aside.
The algorithm uses statistical smoothing methods. You can choose between linear or loess regression.
Hands On: xcms adjustRtime (retcor)
- xcms adjustRtime (retcor) ( Galaxy version 3.12.0+galaxy1) with the following parameters:
- “RData file”:
xset.merged.groupChromPeaks.RData- “Method to use for retention time correction”:
PeakGroups - retention time correction based on aligment of features (peak groups) present in most/all samples.
- “Minimum required fraction of samples in which peaks for the peak group were identified”:
0.8299You can leave the other parameters to default values.
CommentIf you have a very large number of samples (e.g. a thousand), it might be impossible to find peaks that are present in 100% of your samples. If that is the case and you still set a very high value for the minimum required fraction of samples, the tool can not complete successfully the retention time correction. A special attention should also be given to this parameter when you expect a large number of peaks not to be present in part of your samples (e.g. when dealing with some blank samples).
This tool generates a plot output that you can use to visualise how retention time was applied across the samples and along the chromatogram. It also allows you to check whether the well behaved peaks were distributed homogeneously along the chromatogram.
Apart from the plots generated by the adjustRtime tool, you can check the impact of the retention time correction by comparing the chromatogram you obtained previously to a new one generated after correction.
Hands On: xcms plot chromatogram
- xcms plot chromatogram ( Galaxy version 3.12.0+galaxy1) with the following parameters:
- “RData file”:
xset.merged.groupChromPeaks.adjustRtime.RDataCommentAs in the previous ‘plot chromatogram’, you can use your completed sampleMetadata file to get colours.
The retention time correction step is not mandatory. However, when it is used retention time are modified. Consequently, applying this step on your data requires to complete it with an additional ‘grouping’ step using the xcms groupChromPeaks (group) tool tool again.
Parameters for this second group step are expected to be similar to the first group step. Nonetheless, since retention times are supposed to be less variable inside a same peak group now, in some cases it can be relevant to lower a little the bandwidth parameter.
Hands On: second 'xcms groupChromPeaks (group)'
- xcms groupChromPeaks (group) ( Galaxy version 3.12.0+galaxy1) with the following parameters:
- “RData file”:
xset.merged.groupChromPeaks.adjustRtime.RData- “Method to use for grouping”:
PeakDensity - peak grouping based on time dimension peak densities
- “Bandwidth”:
5.0- “Width of overlapping m/z slices”:
0.01- “Get the Peak List”:
Yes
- “Convert retention time (seconds) into minutes”:
Yes- “Number of decimal places for retention time values reported in ions’ identifiers.”:
2- “Replace the remain NA by 0 in the dataMatrix”:
NoCommentWhen performing this second grouping (or at the first one if you do not plan to perform retention time correction), you can take this opportunity to check how your peak table looks like at this point of the XCMS extraction. For this, you can set the ‘Get the Peak List’ option to
Yes.
It is possible to use the retention time correction and grouping step in an iterative way if needed. Once you perform your last adjustRtime step and thus your last grouping step, you will obtain your final peak list (i.e. final list of ions).
Question
- How many ions did you obtained with the final grouping step?
- Open the dataMatrix file you obtained with the final grouping. This table corresponds to intensities for each ion and each sample. What do you notice when looking at the intensity of the first ion regarding the first sample?
- The final grouping step led to 5815 ions.
- The first ion (M58T69) has a ‘NA’ value for the first sample (QC1_014). This is also the case for several other ions and samples.
At this point of the XCMS extraction workflow, the peak list may contain NA when peaks where not considered peaks in only some of the samples in the first ‘findChromPeaks’ step. This does not necessary means that no peak exists for these samples. For example, sometimes peaks are of very low intensity for some samples and were not kept as peaks because of that in the first ‘findChromPeaks’ step.
To be able to get the information that may actually exist behind NAs, there is an additional XCMS step that is called fillChromPeaks.
CommentBefore performing the ‘fillChromPeaks’ step, it is highly recommended to first have a look at your data concerning the distribution of NAs in your data. Indeed, this will allow you to check whether your results are consistent with your expectations; if not you may want to go back to some of your parameter choices in previous XCMS steps. To perform your NA diagnosis, you can use the variableMetadata file and dataMatrix file that you obtained with the last grouping step with the ‘Get the Peak List’ option to
Yes. The variableMetadata file contains information about your ions: you will find information about the number of peaks detected for each ion. The dataMatrix files contains the intensities for each ion and each sample; you can get an overview of it using the Intensity Check tool module.
Final XCMS step: integrating areas of missing peaks
The idea of the XCMS step is to integrate signal in the mz-rt area of an ion (chromatographic peak group) for samples in which no chromatographic peak for this ion was identified.
Hands On: xcms fillChromPeaks (fillPeaks)
- xcms fillChromPeaks (fillPeaks) ( Galaxy version 3.12.0+galaxy1) with the following parameters:
- “RData file”:
xset.merged.groupChromPeaks.*.RData- In “Peak List”:
- “Convert retention time (seconds) into minutes”:
Yes- “Number of decimal places for retention time values reported in ions’ identifiers.”:
2CommentThe “Reported intensity values” parameter is important here. It defines how the intensity will be computed. You have three choices:
- into : integration of peaks (i.e. areas under the peaks)
- maxo : maximum height of peaks
- intb : integration of peaks with baseline subtraction
With this ‘fillChromPeaks’ step, you obtain your final intensity table. At this step, you have everything mandatory to begin analysing your data:
- A sampleMetadata file (if not done yet, to be completed with information about your samples)
- A dataMatrix file (with the intensities)
- A variableMetadata file (with information about ions such as retention times, m/z)
Nonetheless, before proceeding with the next step in the workflow (processing and filtering of your data), you can add an optional step with the CAMERA.annotate tool module. This tool uses the CAMERA R package to perform a first annotation of your data based on XCMS outputs.
Annotation with CAMERA [Optional]
This last step provides annotation of isotopes, adducts and neutral losses. It gives also some basic univariate statistics in case you considered several groups for your XCMS extraction.
There is a huge number of parameters that will not be detailed in this short tutorial. However most of the default values can be kept here for a first attempt to run this function. Nevertheless, a few parameters have to be set at each run:
- The polarity has to be set since it affects annotation.
- For statistical analysis, you have to define if you have two or more conditions to compare. These conditions had to be defined in the sample metadata uploaded previously and taken into account in the XCMS workflow.
- You can define how many significant ions will be used for extracted ions chromatogram (EIC) plot. These plots will be included in a pdf file.
Apart from the PDF file, the main three outcomes from CAMERA.annotate tool are three columns added in the variableMetadata file:
- isotopes: the name says everything
- adduct: same here; this column is filled only in the ‘All functions’ mode
- pcgroup: this stands for Pearson’s correlation group; it corresponds to groups of ions that match regarding retention time and intensity correlations, leading to think that maybe they could come from the same original metabolite.
Hands On: CAMERA.annotate
- CAMERA.annotate ( Galaxy version 2.2.7+camera1.48.0-galaxy1) with the following parameters:
- “RData file”:
xset.merged.groupChromPeaks.*.fillChromPeaks.RData- In “Annotate Isotopes [findIsotopes]”:
- “Max. ion charge”:
2- “Mode”:
Only groupFWHM and findIsotopes functions [quick]- In “Export options”:
- “Convert retention time (seconds) into minutes”:
Yes- “Number of decimal places for retention time values reported in ions’ identifiers.”:
2CommentAs said previously, there are quite a few parameters in this tool, some of them having very high impact on your annotations. In particular, the Mode parameter will influence a lot your results regarding pcgroups, and adducts (that will not be computed otherwise).
The information given by this tool is not mandatory for the next step of the metabolomic workflow. Commonly, annotation is considered a later step in the pipeline, but since CAMERA uses the outputs of XCMS, if you want to use it you better do it at this step, allowing you to have the corresponding information in your variableMetadata file for later use.
Stopover: debriefing and preparation for next steps
At the end of the Preprocessing step, you should have three tabulation-separated tables:
- A sampleMetadata file given and completed by the user
- A dataMatrix file from XCMS.fillChromPeaks
- A variableMetadata file from either XCMS.fillChromPeaks or CAMERA.annotate
Concerning the sampleMetadata file, for the next steps of the workflow, there are four columns that are mandatory to go through all the analysis:
injectionOrder: a numerical column of injection ordersampleType: specifies if a QC pool or a sample (codedpoolorsample)batch: a categorical column indicating the batches of analysis (if only one, must be a constant)- your variable(s) of interest: here we will consider as an example the Body Mass Index (
bmi)
CommentThe preprocessing part of this analysis can be quite time-consuming, and already corresponds to quite a few number of steps, depending of your analysis. It can also generate several versions of your 3 tables, with only one of interest for each at the end of the extraction process. We highly recommend, at this step of the metabolomic workflow, to split your analysis by beginning a new Galaxy history with only the 3 tables you need. This will help you in limiting selecting the wrong dataset in further analyses, and bring a little tidiness for future review of your analysis process.
To begin a new history with the 3 tables from your current history, you can use the functionality ‘copy dataset’ and copy it into a new history.
We also recommend you to rename your 3 tables before proceeding with the next steps of the metabolomic workflow. Indeed, you may have notice that the XCMS tools generate output names that contain the different XCMS steps you used, allowing easy traceability while browsing your history. However, knowing that the next steps of analysis are also going to extend the 3 tables’ names, if you keep the original names it will become very long and thus may reduce the names’ readability. Hence, we highly recommend you to rename them with something short, e.g. ‘sampleMetadata’, ‘variableMetadata’ and ‘dataMatrix’, or anything not too long that you may find convenient.
Hands On: Copying the 3 tables into a new history and renaming them
Create a new history with the 3 tables
There 3 ways to copy datasets between histories
From the original history
- Click on the galaxy-gear icon which is on the top of the list of datasets in the history panel
- Click on Copy Datasets
Select the desired files
“New history named:”
Sacurine Processing- Validate by ‘Copy History Items’
- Click on the new history name in the green box that have just appear to switch to this history
Using the galaxy-columns Show Histories Side-by-Side
- Click on the galaxy-dropdown dropdown arrow top right of the history panel (History options)
- Click on galaxy-columns Show Histories Side-by-Side
- If your target history is not present
- Click on ‘Select histories’
- Click on your target history
- Validate by ‘Change Selected’
- Drag the dataset to copy from its original history
- Drop it in the target history
From the target history
- Click on User in the top bar
- Click on Datasets
- Search for the dataset to copy
- Click on its name
- Click on Copy to current History
Rename the 3 tables with shorter names:
xset.merged.groupChromPeaks.adjustRtime.groupChromPeaks.fillpeaks.dataMatrix.tsv-> dataMatrix.tsvxset.merged.groupChromPeaks.*.fillChromPeaks.annotate.variableMetadata.tsv-> variableMetadata.tsv
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, change the Name field
- Click the Save button
Data processing: quality checks, normalisation, data filtering
In the previous step of the LC-MS workflow, you saw how to extract features from your acquisition files. This data is shaped in a format allowing the use of various standard statistical methods. However, being able to perform a statistical analysis does not mean necessarily being able to highlight relevant information. Indeed, data are often affected by various sources of unwanted variability. It can limit the effectiveness of statistical methods, leading sometimes to difficulties in revealing investigated effects. Identifying such variability can help analyzing your data at its full potential.
In this tutorial, we chose to limit the data processing to 3 steps:
- overview of the variability in the data
- signal drift correction
- filtering of unreliable variables based on coefficients of variation
CommentTo get a little more information regarding data processing, do not hesitate to visit the usemetabo.oc platform: Link to LC-MS processing step
Step 1: global variability in the data
Commonly, LC-MS analyses generate a significant number of variables (hundreds to thousands). Getting a complete view of such dataset may not be an easy task, but getting a glimpse of it is possible using some common unsupervised multivariate analysis. One of the most commonly used method is the Principal Components Analysis (PCA). You can get a basic PCA along with over useful information using the Quality Metrics tool tool.
Hands On: Using Quality Metrics to get an overview of your data
- Quality Metrics ( Galaxy version 2.2.8) with the following parameters:
- “Data matrix file”:
dataMatrix.tsv- “Sample metadata file”:
sampleMetadata_completed.tsv- “Variable metadata file”:
variableMetadata.tsv
For a first overview of your data, you can focus on the graphical output of this tool: Quality_Metrics_figure.pdf. It provides a variety of useful information:
- Summary of the intensities in the dataMatrix file (information.txt file and plot top center paragraph)
- View of these intensities with a color scale (plot bottom right panel)
- 2-components PCA score plot to check for clusters or outliers (plot top left panel)
- Sum of intensities per sample according to injection order to check the presence of signal drift or batch effect (plot top center panel)
- Z-scores for intensity distribution and proportion of missing values (plot bottom left panel)
- Ions’ standard deviation (sd) and mean values (plot top right panel)
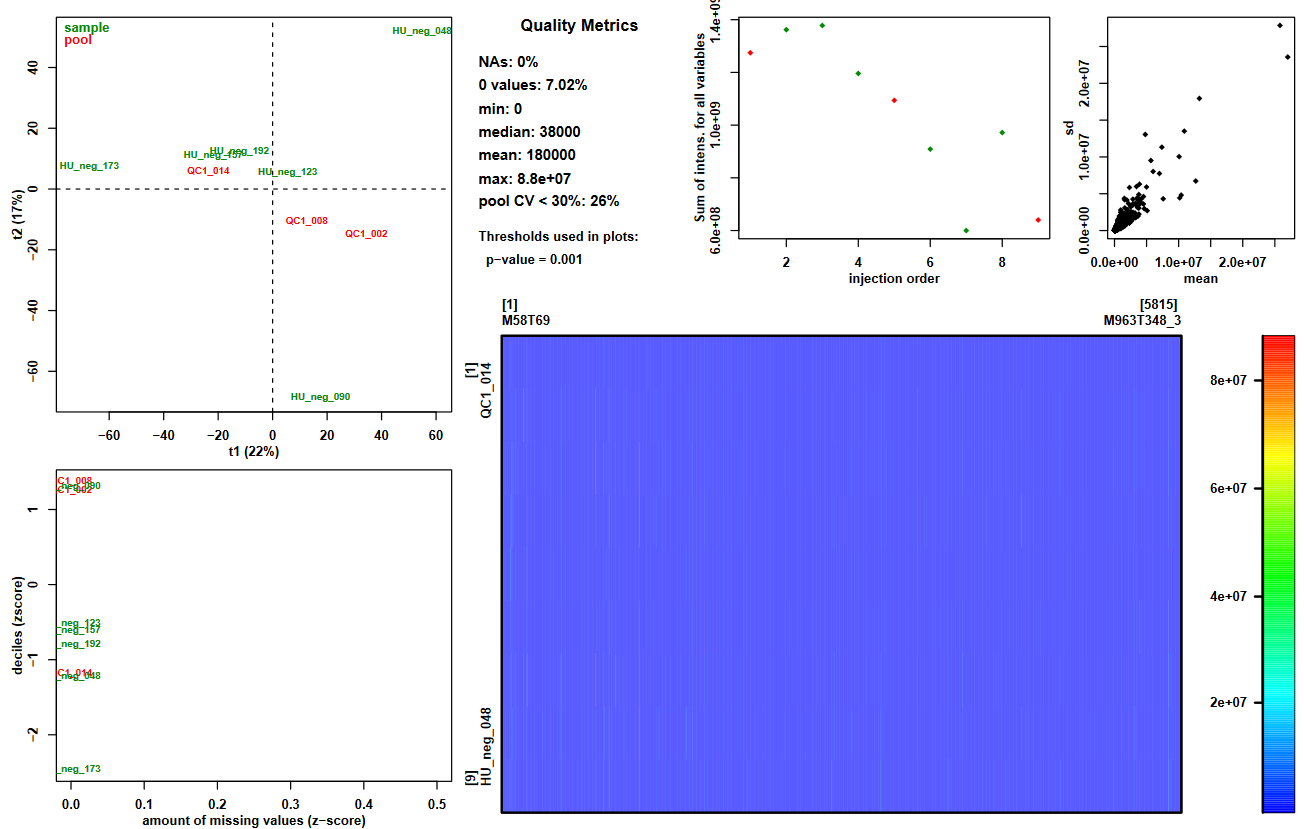
Question: cross-referencing informationLook at the ‘Quality_Metrics_figure.pdf’ file.
- Look at the proportion of ions with a pool coefficient of variation <30%. Knowing that pools are identical samples, and that values with a CV > 30% can not be considered stables, what can you conclude about your dataset regarding the possibility to compare intensities between samples?
- Look at the sum of intensities per sample according to injection order. What major information do you observe on the plot? Can this observation help you understand the CV results you just looked at?
- Now look at the PCA plot. Can you explain the first component (t1)? Use the previous plot to help you.
- You can read on the plot that pool CV < 30%: 26%, meaning that the pool values are stable only for a quarter of the ions in your dataset. If the pooled samples are not stable, this means that you can observe differences between samples even when there are no biological differences. Thus, comparing samples becomes difficult and has high risk of being unreliable. Consequently, with only a quarter of the ions being stable regarding pool intensities, performing statistical analyses on this full dataset would probably lead to unreliable results.
- We can see in the figure that the global intensity of samples seems to decrease with the injection order. In particular, the fact that the pooled samples’ intensities decrease leads us to suspect a signal drift due to the clogging effect of successive injection of samples. This signal drift could be the reason why so many ions in the dataset led to high CV values for pools, since it prevents at least part of the ions to be stable regarding pools’ intensities.
- If we look closely at the samples’ identifiers on the plot, it seems that the lowest numbers in IDs are at the right side of the first component. Knowing that these numbers correspond to an order in the injection sequence, we can link it to the previous picture’s samples. Then, what we can observe is that the order of samples in the first component of PCA from right to left corresponds approximately to the decreasing order of sums of intensities. Thus, we can conclude that the main variability in the dataset may be due to the signal drift.
Step 2: handling the signal drift observed all through the analytical sequence
It is known that when injecting successively a large number of samples, the system tends to get dirty, and this may cause a measure drift. To prevent inability to catch signal anymore, in case of large injection series, the sequence is generally divided into several batches and the source is cleaned between batches. Unfortunately, these signal drift and batch design can add significant variability in data, making sample comparison complicated. In case data is impacted by these effects, it is highly recommended to normalise the data to get rid of these unwanted variabilities.
In our case study, we saw that the data seemed to be affected by signal drift. Thus, we will use the Batch_correction tool tool to get rid of it.
Hands On: Data normalisation
- Batch_correction ( Galaxy version 3.0.0) with the following parameters:
- “Data matrix file”:
dataMatrix.tsv- “Sample metadata file”:
sampleMetadata_completed.tsv- “Variable metadata file”:
variableMetadata.tsv- “Type of regression model “:
linear
- “Factor of interest “:
genderCommentThe choice of type of regression model to use depends on several parameters. In this case-study, since we only have 3 pools, there are only two possible choices: linear or all loess sample When possible, we recommend to use pools to correct the signal drift, that is why we chose to run the tool with linear.
What transformation has this tool done to the ions’ intensities?
For each ion independently, the normalisation process works as described in the following picture:
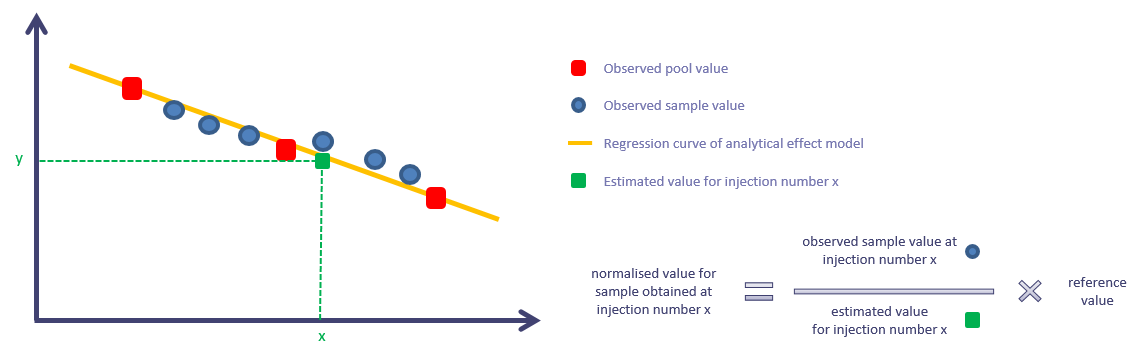
The methodology is meant to correct for signal drift. In the tool, it is combined with a correction for batch effect. Thus, if your sequence is divided into several batches, the idea is to obtain something similar to the following picture:
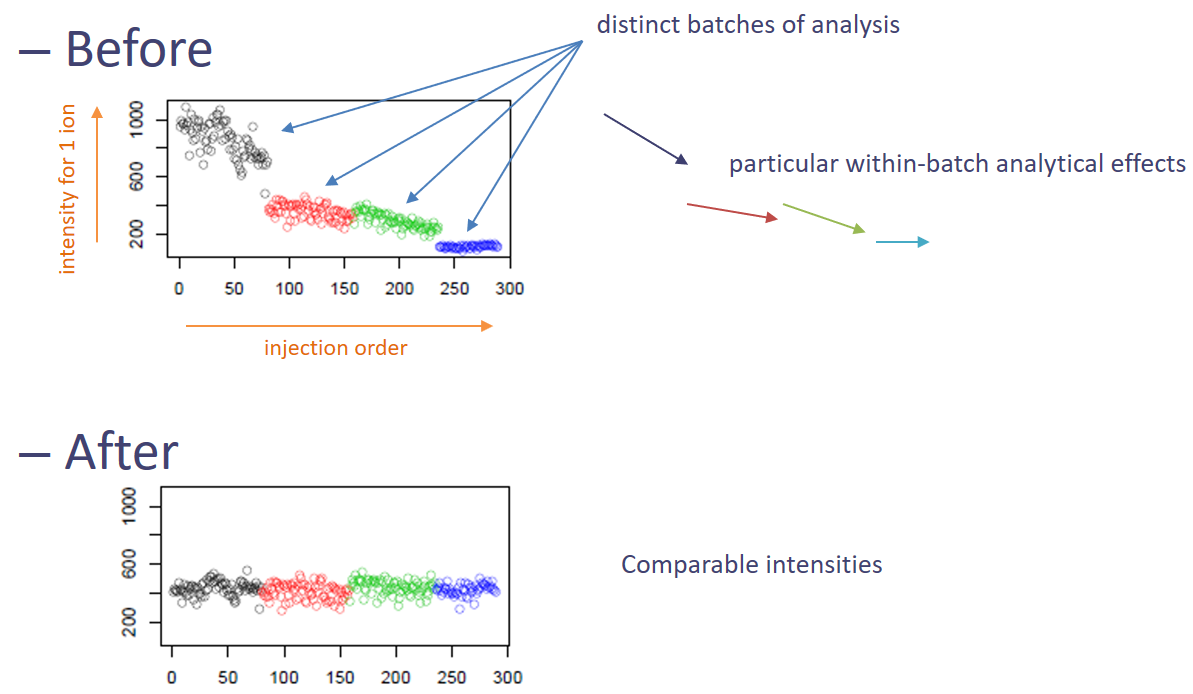
In the case of linear regression model, the tool performs some tests before applying the normalisation for quality purposes. For some ions, if the normalisation process would have led to inconsistent results, the concerned ions are not corrected for signal drift. This kind of quality checks depends on the type of regression model you use. Please refer to the tool’s help section for more information!
Step 3: getting rid of unreliable variables using CV
Now that the data is corrected for signal drift, we expect to have stable intensities within pools. But is this always the case? Truth is, even when correcting ions, we may not manage to get rid of analytical effect for 100% of ions. And even if we could, LC-MS data may contain noise signal, or ions that are not reliable as they are too noisy. Thus, it is possible that the data still contains unusable ions.
To filter the ions not reliable enough, we can consider CVs as a filtering indicator. The Quality Metrics tool tool provides different CV indicators depending on what is in your sample list. In particular, in the present case-study, it can compute pool CVs as previously seen, but also a ratio between pool CVs and sample CVs. This is particularly of interest since we can expect that, whatever the pool CV value, it will be lower than the corresponding sample CV value, since biological samples are supposed to be affected by biological variability. Thus, we can filter the ions that do not respect this particular condition.
Hands On: CV calculation
- Quality Metrics ( Galaxy version 2.2.8) with the following parameters:
- “Data matrix file”:
BC_linear_dataMatrix.tsv- “Sample metadata file”:
sampleMetadata_completed.tsv- “Variable metadata file”:
BC_linear_variableMetadata.tsvCommentDo not forget you need to use this tool again, since this time indicators will be computed on normalised intensities. What we are going to use this time is the tabular output, but while you are at it you can always check the pdf file.
The tool provides a variableMetadata tabular output, containing all the computed CV values. You can then use these values to filter your data using the Generic_Filter tool tool.
Hands On: Data filtering
- Generic_Filter ( Galaxy version 2020.01) with the following parameters:
- “Data matrix file”:
BC_linear_dataMatrix.tsv- “Sample metadata file”:
sampleMetadata_completed.tsvorQuality Metrics_sampleMetadata_completed.tsv- “Variable metadata file”:
Quality Metrics_BC_linear_variableMetadata.tsv- “Deleting samples and/or variables according to Numerical values”:
yes
- param-repeat “Identify the parameter to filter “
- “On file”:
Variable metadata- “Name of the column to filter”:
poolCV_over_sampleCV- “Interval of values to remove”:
upper
- “Remove all values upper than”:
1.0- param-repeat “Insert Identify the parameter to filter “
- “On file”:
Variable metadata- “Name of the column to filter”:
pool_CV- “Interval of values to remove”:
upper
- “Remove all values upper than”:
0.3- “Deleting samples and/or variables according to Qualitative values”:
yes
- param-repeat “Removing a level in factor”
- “Name of the column to filter”:
sampleType- “Remove factor when”:
poolCommentYou can see here that you can take the opportunity of this filtering step to get rid of the pools. Indeed, next step is statistical analysis, and you do not need the pools anymore since they do not participate in the scientific design of the study.
Question
- What does the 0.3 threshold mean in the hands-on exercise you just executed?
- What does the 1.0 threshold mean in the hands-on exercise you just executed?
- How many variables are left in your dataset? How many samples?
- The 0.3 value corresponds to the maximum value kept in the dataset (‘Interval of values to remove: upper’) regarding the poolCV column in your Variable metadata file. As mentioned previously in ‘Step 1: global variability in the data’ section, pool CV values are commonly considered as reflecting unstable ions when superior to 0.3. Although the signal drift correction decreased the proportion of ions with pool CV > 30% from 74% to 53%, we still need to get rid of these remaining unstable ions for which sample comparisons would be difficult and at high risk of being unreliable.
- The 1.0 value corresponds to the maximum value kept in the dataset (‘Interval of values to remove: upper’) regarding the poolCV_over_sampleCV column in your Variable metadata file. This means that any ion with a pool CV / sample CV ratio above 1 (i.e. a pool CV greater than the sample CV) is discarded from the dataset.
- Filtering led to 2707 ions and 6 samples.
Statistical analysis to find variables of interest
The question of data filtering and correction must be addressed in all projects, even thought in some cases it may lead to the decision of no action on data. Once you applied your customized processing procedure, your tables are ready for the statistical analysis.
There is a large variety of statistical analysis methods that you can apply on metabolomic LC-MS data. The most standard strategy is a combination of univariate analysis (such as applying a Mann-Whitney-Wilcoxon test on each ion independently) and multivariate analysis (such as constructing a PLS model using all your ions at once). What you should keep in mind is that the choice of your statistical analysis strategy depends on both your data characteristics (such as colinearity or dataset size) and your study design. You should think carefully about what is appropriate for your own project.
In this tutorial, we will take the example of univariate analysis, using the bmi column of the sampleMetadata file as
the study’s biological factor investigated (body mass index). Since this variable is quantitative, we will chose in this example to measure
the link between the BMI and the measured ions using a statistical correlation calculation. For more examples of
statistical analysis performed on LC-MS data, you can take a few minutes to watch the usemetabo.org open course video.
Computation of statistical indices
The first step is to compute the correlation coefficients used to estimate the link between the biological variable bmi
and the ions that we have in our dataset. For this calculation we can use the Univariate tool tool.
Hands On: Statistical analysis
- Univariate ( Galaxy version 2.2.4) with the following parameters:
- “Data matrix file”:
Generic_Filter_BC_linear_dataMatrix.tsv- “Sample metadata file”:
Generic_Filter_Quality Metrics_sampleMetadata_completed.tsv- “Variable metadata file”:
Generic_Filter_Quality Metrics_BBC_linear_variableMetadata.tsv- “Factor of interest”:
bmi- “Test”:
Spearman correlation rank test (quantitative)- “Method for multiple testing correction”:
noneCommentIn this tutorial, we chose to perform the analysis without multiple testing correction. This choice is not based on a relevant statistical strategy (which would more likely be to use multiple testing correction). It is based on the fact that with only 6 biological samples in a dataset of 2706 ions it is almost impossible to settle for correlation coefficients significantly different from zero. Consequently, to illustrate better the filtering step that will follow, we chose not to apply the multiple testing correction, allowing us to obtain something that looks like ‘significant’ results regarding statistical indices.
The tool provides different types of output. You will find statistical indices in the variableMetadata output (such as p-values and statistical indicators). ‘Significant’ results are illustrated by graphics in the Univariate_figure.pdf file.
QuestionHow many significant variables were found?
The tool found that 61 variables have a correlation coefficient significantly different from 0.
Reducing the dataset to keep ions of interest only
In untargeted metabolomics, statistical analysis is usually used as a filter to focus on a subset of variables with potential. This subset can be used to proceed to identification and thus biological interpretation. Hence, statistical indices are generally associated with thresholds allowing us to determine which ions should be kept or discarded.
In our example of correlation analysis, two indices can be used to filter the data.
- P-values: it indicates whether it is likely for a given correlation coefficient not to be actually different from zero; considering a threshold of 0.05 generally corresponds to a misleading risk of 5%.
- Correlation coefficient: it indicates if the correlation between a given ion and the biological factor is strong or not; it goes from -1 to 1, with 0 meaning no correlation; in our example we consider as a sufficiently strong link a coefficient with absolute value above 0.9.
Hands On: Variable filtering
- Generic_Filter ( Galaxy version 2020.01) with the following parameters:
- “Data matrix file”:
Generic_Filter_BC_linear_dataMatrix.tsv- “Sample metadata file”:
Generic_Filter_Quality Metrics_sampleMetadata_completed.tsv- “Variable metadata file”:
Univariate_Generic_Filter_Quality Metrics_BC_linear_variableMetadata.tsv- “Deleting samples and/or variables according to Numerical values”:
yes
- param-repeat “Identify the parameter to filter “
- “On file”:
Variable metadata- “Name of the column to filter”:
bmi_spearman_none- “Interval of values to remove”:
upper
- “Remove all values upper than”:
0.05- param-repeat “Insert Identify the parameter to filter “
- “On file”:
Variable metadata- “Name of the column to filter”:
bmi_spearman_cor- “Interval of values to remove”:
between
- “Remove all values between”:
-0.9- “And”:
0.9- “Deleting samples and/or variables according to Qualitative values”:
no
With this filter you obtain a subset of your data, supposedly ions that may present an interest regarding your study. If the goal is to find biomarkers, then you have a subset of biomarker candidates. If you aim for mechanism explanation, you obtain a subset of ions to identify and replace in a biological context.
In this tutorial, the statistical filtering led to 25 remaining ions, linked to the BMI values by high correlation coefficients.
Annotation
Now that you have a short list of interesting ions, you may be interested in knowing which molecules these ions come from. Identification is generally a difficult and time-consuming step. To help you in that process or to get a potential first glance of the nature of your selected subset, annotation can be a first valuable step.
Annotation is not identification. It is only meant to try matching your data with hypotheses based on known information. Nonetheless, it can help you save a lot of time giving you hints about what to search for. The basic idea is to bring your ion’s masses and a reference mass bank face to face. This will give you potential origins of your ions.
To be able to perform annotation, you will ‘only’ need to gather the mass list of your subset of ions, a reference bank, and a tool to proceed to the matching. The use of ‘only’ is tricky here, since even the subset of ions to use may not be turnkey at this step of the workflow (even if you consider the previous steps as cleared now, selected ions may not be the ones most appropriate to get a foothold in annotation).
For example, what may be the reference bank that you need for the annotation step? This is a crucial question. It exists a variety of online resources with well-known reference banks, but which one to choose? Some banks may have overlapping content, but also specific one. In fact, the appropriate bank may depend on the analytical technique used, the type of sample analyzed, the nature of individuals/organisms from which you got your biological samples… If you are working on widely studied organism, you may find an adequate reference bank online. However, it is also possible that none of the provided banks is relevant for your study. In that case, you may need to construct your own database, to be able to search for relevant matches for your ions of interest.
In this tutorial, we chose the ‘easy’ case of human urinary samples. Thus, one possibility we have is to use the online reference bank HMDB (The Human Metabolome Database). Let’s try requesting directly into this widely used bank using the HMDB MS search tool tool.
Hands On: Annotating the data using the HMDB
- HMDB MS search ( Galaxy version 1.7.6) with the following parameters:
- “Would you use a file “:
YES
- “File of masses (Variable Metadata) “:
Generic_Filter_Univariate_Generic_Filter_Quality Metrics_BC_linear_variableMetadata.tsv- “Do you have a header “:
YES- “Column of masses “:
c3- “Mass-to-charge ratio “:
0.005- “Number of maximum entries returned by the query “:
3- “Molecular Species “:
Negatif Mode
Here, we tried to provide a Mass-to-charge ratio (i.e. a mass delta) based on what we globally know about the technique used to analyze the samples. Even if this parameter may seems simple, it is important to settle it with a relevant value. If you provide a value that is too low, you may not be able to have matches for your ions even though the original molecule is present in the database. On the opposite, if the value provided is too high, you may end with a huge number of matches, which could be time-consuming to review to identify relevant proposed annotation.
CommentOnce you reviewed carefully your annotation and settled for a subset of candidate identities, your are ready for further adventures. For now, Galaxy4Metabolomics stops here but we have various perspectives of additional tools for the future (a little bit of MetExplore for example?).
Conclusion
This tutorial allowed you to get a glance at what data analysis in Metabolomics could look like when dealing with LC-MS data. The workflow used here as an example is only one of many that you can already construct using Galaxy. For each of the four main steps described here, you can find a variety of combinations and tools to use, to try to reach the highest potential of Galaxy when dealing with LC-MS metabolomic data. Now that you know that tools exist and are available in this accessible, reproducible and transparent resource that Galaxy is, all that remains for you to make high level reproducible science is to develop and apply your expertise in Metabolomics, and create, run and share!
You've Finished the Tutorial
Key points
To process untargeted LC-MS metabolomic data, you need a large variety of steps and tools.
Although main steps are standard, various ways to combined tools exist, depending on your data.
Resources are available in Galaxy, but do not forget that you need appropriate knowledge to perform a relevant analysis.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsReferences
- Smith, C. A., E. J. Want, G. O’Maille, R. Abagyan, and G. Siuzdak, 2006 XCMS: Processing Mass Spectrometry Data for Metabolite Profiling Using Nonlinear Peak Alignment, Matching, and Identification. Analytical Chemistry 78: 779–787. 10.1021/ac051437y
- Tautenhahn, R., C. Böttcher, and S. Neumann, 2008 Highly sensitive feature detection for high resolution LC/MS. BMC Bioinformatics 9: 504. 10.1186/1471-2105-9-504
- Giacomoni, F., G. L. Corguille, M. Monsoor, M. Landi, P. Pericard et al., 2014 Workflow4Metabolomics: a collaborative research infrastructure for computational metabolomics. Bioinformatics 31: 1493–1495. 10.1093/bioinformatics/btu813
- Thévenot, E. A., A. Roux, Y. Xu, E. Ezan, and C. Junot, 2015 Analysis of the Human Adult Urinary Metabolome Variations with Age, Body Mass Index, and Gender by Implementing a Comprehensive Workflow for Univariate and OPLS Statistical Analyses. Journal of Proteome Research 14: 3322–3335. 10.1021/acs.jproteome.5b00354
- Carsten Kuhl, R. T., 2017 CAMERA. 10.18129/b9.bioc.camera https://bioconductor.org/packages/CAMERA
- Guitton, Y., M. Tremblay-Franco, G. L. Corguillé, J.-F. Martin, M. Pétéra et al., 2017 Create, run, share, publish, and reference your LC–MS, FIA–MS, GC–MS, and NMR data analysis workflows with the Workflow4Metabolomics 3.0 Galaxy online infrastructure for metabolomics. The International Journal of Biochemistry & Cell Biology 93: 89–101. 10.1016/j.biocel.2017.07.002
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Mélanie Petera, Gildas Le Corguillé, Jean-François Martin, Yann Guitton, Workflow4Metabolomics core team, Mass spectrometry: LC-MS analysis (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/metabolomics/tutorials/lcms/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{metabolomics-lcms, author = "Mélanie Petera and Gildas Le Corguillé and Jean-François Martin and Yann Guitton and Workflow4Metabolomics core team", title = "Mass spectrometry: LC-MS analysis (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/metabolomics/tutorials/lcms/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Funding
These individuals or organisations provided funding support for the development of this resource
Congratulations on successfully completing this tutorial!
You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/metabolomics/tutorials/lcms/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: qualitymetrics owner: ethevenot revisions: acdf51018708 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: univariate owner: ethevenot revisions: 5687435b182c tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: hmdb_ms_search owner: fgiacomoni revisions: 29195cb5d378 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: hmdb_ms_search owner: fgiacomoni revisions: 49f87ddb2c78 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: camera_annotate owner: lecorguille revisions: 73d82de36369 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: camera_annotate owner: lecorguille revisions: 75a1b3f7bacc tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: msnbase_readmsdata owner: lecorguille revisions: 6de175c1f6ef tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: msnbase_readmsdata owner: lecorguille revisions: 86a20118e743 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_export_samplemetadata owner: lecorguille revisions: 4ea32e46b2d6 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_fillpeaks owner: lecorguille revisions: ec9aebabc1d2 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_fillpeaks owner: lecorguille revisions: 3bc94c3abb28 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_group owner: lecorguille revisions: 71572faf938e tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_group owner: lecorguille revisions: fe4002ac5193 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_merge owner: lecorguille revisions: 6d475a389abc tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_merge owner: lecorguille revisions: a301f001835c tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_plot_chromatogram owner: lecorguille revisions: c8bef8f6a1cb tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_plot_chromatogram owner: lecorguille revisions: 271c9d5f0d10 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_retcor owner: lecorguille revisions: d2b82d89f848 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_retcor owner: lecorguille revisions: 7faadba7c625 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_xcmsset owner: lecorguille revisions: 6550698fe60f tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: xcms_xcmsset owner: lecorguille revisions: 378ddb410225 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: batchcorrection owner: melpetera revisions: 73892ef177e3 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: batchcorrection owner: melpetera revisions: 23314e1192d4 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: generic_filter owner: melpetera revisions: b1fa45bd2b44 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: generic_filter owner: melpetera revisions: cfd7c4aa5c26 tool_panel_section_label: Metabolomics tool_shed_url: https://toolshed.g2.bx.psu.edu/