Data Manipulation Olympics
| Author(s) |
|
| Editor(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How can I do basic data manipulation in Galaxy?
Which tools are available to convert, reformat, filter, sort etc my text-based data?
Familiarize yourself with data manipulation tools in Galaxy
Perform basic text manipulation tasks in Galaxy
Become comfortable converting text-based files in a variety of ways.
Reason about the expected outcome of tools
Time estimation: 1 hourLevel: Introductory IntroductorySupporting Materials:Published: Jul 20, 2022Last modification: Apr 13, 2026License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00184rating Rating: 4.5 (8 recent ratings, 43 all time)version Revision: 16
Scientific analyses often consist of a number of tools that run one after the other, in order to go from the raw data to scientific insight. Between these specialized tools, simple data manipulation steps are often needed as a kind of “glue” between tools. For example, the output of tool A may produce a file that contains all the information needed as input for tool B, but tool B expects the columns in a different order. Or in genomic data analysis, some tools expect chromosome X to be listed as chrX, while others simply expect X. In these situations, extra data manipulation steps are needed to prepare files for input to analysis tools.
Galaxy has a large collection of tools to perform such basic data manipulation tasks, and becoming familiar with these operations will allow to perform your analysis more easily in Galaxy (and outside).
AgendaIn this tutorial, we will cover:
Cheatsheet
Here is an overview table of the different data manipulations in this tutorial, with links to the tools in Galaxy.
If you’ve opened this tutorial via the level icon in Galaxy (top menu bar), you can click on the tool names in the last column to quickly open them in Galaxy and start using them on your own!
| Operation | Description | Galaxy Tool |
|---|---|---|
| Convert format | Change the file format | galaxy-pencil Edit attributes |
| Word count | Count the number of lines, words and characters in a file | Line/Word/Character count |
| Sort on a column | Change the order of the rows based on values in one or more columns | Sort ( Galaxy version 1.1.1) |
| Filter | Remove rows based on values in one or more columns | Filter |
| Counting | Count occurrences of values in a column | Count , Datamash ( Galaxy version 1.1.0+galaxy2) |
| Group on a column | And perform simple operations (count, mean, min, max etc) | Group , Datamash ( Galaxy version 1.1.0+galaxy2) |
| Compute on rows | to derive new column values from existing ones | Compute ( Galaxy version 2.0) |
| Find and Replace | in a specific column | Column Regex Find and Replace ( Galaxy version 1.0.1) |
| Find and Replace | on every line | Regex Find and Replace ( Galaxy version 1.0.1) |
| Join two Datasets | side by side on a specified field | Join two Datasets |
| Concatenate datasets | one after the other | Concatenate multiple datasets or collections |
| Remove Beginning | Good for removing header lines | Remove beginning of a file |
| Select First lines | Good for finding top 10s or saving header lines | Select first lines |
| Cut Columns | By header name | Remove columns by heading ( Galaxy version 0.0.1) |
| Cut Columns | By column number | Cut columns from a table, Advanced Cut columns from a table ( Galaxy version 1.1.0) |
| Paste | Two files side by side | Paste |
| Split file | Based on values of a column | Split ( Galaxy version 0.6) |
| Unique | Remove duplicate rows | Unique ( Galaxy version 1.1.0) |
TIP: Adding tools to your Favourites: If you find yourself frequently using the same tool often but struggle to find it back in the long list of tools, you can star your favourite tools in Galaxy!
Galaxy servers can have a lot of tools available, which can make it challenging to find the tool you are looking for. To help find your favourite tools, you can:
- Keep a list of your favourite tools to find them back easily later.
- Adding tools to your favourites
- Open a tool
- Click on the star icon galaxy-star next to the tool name to add it to your favourites
- Viewing your favourite tools
- Click on the star icon galaxy-star at the top of the Galaxy tool panel (above the tool search bar)
- This will filter the toolbox to show all your starred tools
- Change the tool panel view
- Click on the galaxy-panelview icon at the top of the Galaxy tool panel (above the tool search bar)
- Here you can view the tools by EDAM ontology terms
- EDAM Topics (e.g. biology, ecology)
- EDAM Operations (e.g. quality control, variant analysis)
- You can always get back to the default view by choosing “Full Tool Panel”
In this tutorial, these tools are explained in more detail, and we provide some exercises for you to practice.
Background
In this tutorial, we will use as our dataset a table with results from the Olympics, from the games in Athens in 1896 until Tokyo in 2020. The objective is to familiarize you with a large number of the most important data manipulation tools in Galaxy. Much like the Olympics, there are many different disciplines (types of operations), and for each operation there are often multiple techniques (tools) available to athletes (data analysts, you) that are great for achieving the goal.

We will show you many of these commonly needed data manipulation operations, and some examples of how to perform them in Galaxy. We also provide many exercises so that you can train your skills and become a data manipulation Olympian!
Upload Data
Before we can do any manipulation, we will need some data. Let’s upload our table with Olympics results now.
Hands On: Get data
Import the file
olympics.tsvvia linkhttps://zenodo.org/record/6803028/files/olympics.tsv
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window
Expand on the item in your history to see some metadata and a short preview of the contents.
View galaxy-eye the dataset by clicking on the eye icon.
Question
- What is the format of the file?
- What does each row represent?
- How many lines are in the file? (Hint: Line/Word/Character count)
- How many columns?
- When you expand the
olympics.tsvdataset in your history (see also screenshot below), you will seeformat: tabular, this is another term for a tab-separated (tsv) file.- Each row represents an athlete’s participation in an event. If an athlete competes in multiple events, there is a line for each event.
- 234,523. Look at the expanded view in your history, this tells us there are ~250,000 rows in the dataset. We can get the exact number using the Line/Word/Character count tool.
- There are 17 columns in this file. There are multiple ways to find this answer:
- Count the columns manually (only doable for small files)
- In the expanded view, scroll sideways on the dataset preview, at the top the columns are numbered
- Click on the galaxy-info i icon on the dataset; here you will find more detailed information about the file and the job that created it. At the bottom is also a preview (peek) of the dataset and numbered columns

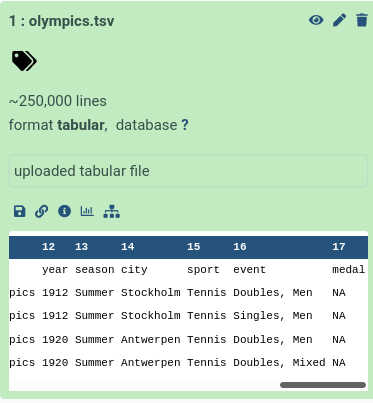
About this dataset
The data was obtained from Olympedia. The file olympics.tsv contains
234,522 rows and 17 columns. Each row corresponds to an individual athlete competing in an individual Olympic event. The columns are:
- athlete_id - Unique number for each athlete
- name - Athlete’s name
- sex - M or F
- birth_year - 4-digit number
- birth_day - e.g. 24 July
- birth_place - town and/or country
- height - In centimeters (or
NAif data not known) - weight - In kilograms (or
NAif data not known) - team - Team name
- noc - National Olympic Committee 3-letter code
- games - Year and season
- year - Integer
- season - Summer or Winter
- city - Host city
- sport - Sport
- event - Event
- medal - Gold, Silver, Bronze (or
NAif no medal was won)
We will use this dataset to practice our data manipulation skills in Galaxy.
Choose your adventure!
This tutorial is structured a bit differently than most. You do not have to do the steps in the order they are presented below. Every section in this tutorial uses the dataset you just uploaded (the olympics.tsv file) as input, so you can jump to any section in this tutorial right now if you have a particular data manipulation operation in mind you want to learn more about.
File Format Conversion
The file we uploaded is a .tsv file. This stands for tab-separated values. This means that this is a file containing rows and columns, where a TAB character is used to signify a column ends and a new one begins. Galaxy is great at understanding tab-separated files, and most of the data manipulation tools are designed to work with such files.
A similar format you may come across a lot in data science, is the .csv file, or comma-separated values file. This is the same as .tsv, but uses comma (,) characters to indicate new columns, instead of TAB (\t) characters.
Galaxy can convert these two formats into each other.
Hands On: Convert Tabular to CSV
Convert the
olympics.tsvfile into a CSV file
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes.
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top.
- In the galaxy-gear Convert to Datatype section, select
csv (using 'Convert tabular to CSV')from “Target datatype” dropdown.- Click the Create Dataset button to start the conversion.
galaxy-eye View the converted dataset
Question
- What do you notice?
- Why are some values in quotes?
- The display in the center panel should be indistinguishable from before the conversion; however, if you look at the “quick view” of the data in the history step, you will see the commas separating columns.
- If the data in a column contains a comma (e.g. in this file we have events such as
swimming 5,000 meters), we put the value in quotes to signify that that comma is part of the data, not a column delimiter.
Converting vs Changing the datatype
The file format conversion step changed the dataset itself (by changing TABs to commas), and therefore created another dataset in your history. It is also possible to change the datatype; this does not change the underlying file/data, but just tells Galaxy what type of file it is. Galaxy uses this information in a variety of ways, such as:
- How to display the data when you click the galaxy-eye View button
- Which visualization options to offer
- Filtering the list of possible inputs for tools (to only allow those of the correct datatype and protect you from mistakes)
- Which file format conversions to make available
- etc..
When you upload a file to Galaxy, by default it will attempt to auto-detect the file format. This is very often correct, but some times you may need to manually set the datatype to the correct value.
Hands On: Change datatype from Tabular to TXT
Change the datatype of the
olympics.tsvfile totxt.
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select
txtfrom “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button
galaxy-eye View the dataset again
Question
- What do you see?
- Why didn’t this step create a new item in your history?
Since Galaxy now no longer know that this is a tabular file with rows and columns, it displays the data as-is, no longer arranging the view into neat columns.
The file itself did not change, only the metadata. We simply told Galaxy to treat this file as a plain text file, instead of a tabular file.
Change the file back from
txttotabular
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select
tabularfrom “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button
Sorting
We have a lot of data in this file, but it is ordered by the athlete ID number, which is a somewhat arbitrary and meaningless number. But we can sort the rows in this file to something more convenient, for example alphabetically by name of the athlete, or chronologically by year of the Olympics.
Hands On: Sort table based on a column
We will sort the file in chronological order based on the year of the Olympic games
Question
- Which column contains the year?
- Do we want ascending or descending order if we want the oldest games at the top?
- What should we do with the very first row (the one with the header names?)
- Column 12
- The file should be sorted in ascending (increasing) order
- The header line should always stay on top, so we want to ignore it when we sort the file.
- Open the Sort - data in ascending or descending order ( Galaxy version 1.1.1) tool
- Read the help text at the bottom of the tool form
- Which settings do you think we need to use?
- Sort - data in ascending or descending order ( Galaxy version 1.1.1) with the following parameters:
- param-file “Sort Query”:
olympics.tsv- param-text “Number of header lines”:
1`- Column selections
- param-select “on column”:
Column 12- param-select “in”:
Ascending order- param-select “Flavor”:
Fast numeric sortgalaxy-eye View the sorted file.
QuestionWhich athlete is listed at the top of the file now?
- J. Defert. Who competed in a Tennis event 1896 Summer Olympics in Athens.
- Rename galaxy-pencil the resulting file to somthing meaningful (e.g.
Olympics in chronological order)
- It can be easy to lose track of what steps you have performed and what each output contains, especially if you are doing many data manipulation steps. Do future-you a favour and give datasets good names!
This is great, but maybe it would make more sense to sort alphabetically by athlete name within each year.
Sort on multiple columns at once
So we want to sort twice, first by year, and then within each year, we sort again alphabetically by name. The sort tool can do this!
Hands On: Sort table based on a column
We will sort the file in chronological order based on the year of the Olympic games
Question
- Which column contains athlete names?
- Do we want ascending or descending order if we want to sort alphabetically with A first?
- Column 2
- The file should be sorted in ascending (increasing) order
- galaxy-refresh Rerun the sort tool with the following parameters:
- All parameter from the first step should already be set for you, and should remain the same
- param-repeat Insert Column selections
- param-select “on column”:
Column 2- param-select “in”:
Ascending order- param-select “Flavor”:
Alphabetical sortgalaxy-eye View the sorted file.
QuestionWhich athlete is listed at the top now? Which discipline (sport) did they compete in?
- A. Grigoriadis. He competed in the 500 meters freestyle swimming event.
- Rename galaxy-pencil the resulting file to somthing meaningful
Exercises
Ok, time to train! Let’s see if you can use the sort tool to answer the following questions:
Exercise: Reverse the sortWhich athlete comes last by alphabet, in the most recent Olympics?
Žolt Petowho competed in table tennis at the 2020 Summer Olympics in Tokyo.
We do this by repeating the previous sort (on year and then name), but changing the order to descending for both, to get the answer to the top of the file.
Exercise: sort by height
- What is the height of the tallest competing athlete? Which athlete(s) are of this height?
- What is the shortest?
- Who was the tallest athlete from the most recent Olympics? How tall were they?
- Height is listed in column 7. Since this is a simple number (no scientific notation), we can use fast numerical sort, and because we want the tallest on top, we will need to sort in descending (decreasing) order.
- Rerun the tool for step 1, but change the order to ascending
- First sort by year (descending), then by height (descending)
- Adam Sandurski from Poland is the tallest athlete in the file, at 214 cm tall.
- Here we don’t get a clear answer. That is because not all athletes have height data available, and blank fields (
NA) are being sorted to the top. We can filter out rows with missing data to get our answer (see Filter section to learn how to do this). For now we cannot answer this question with just the sort tool. Some times multiple tools are required to perform such tasks. The exercise section at the end of this tutorial has many exercises that require a combination of different tools.- Gennaro Di Mauro, 210 cm. (2020 Summer Olympics in Tokyo)
- Sort - data in ascending or descending order ( Galaxy version 1.1.1) with the following parameters:
- param-file “Sort Query”:
olympics.tsv- param-text “Number of header lines”:
1`- Column selections
- param-select “on column”:
Column 7- param-select “in”:
Descending order- param-select “Flavor”:
Fast numeric sort- Sort - data in ascending or descending order ( Galaxy version 1.1.1) with the following parameters:
- param-file “Sort Query”:
olympics.tsv- param-text “Number of header lines”:
1`- Column selections
- param-select “on column”:
Column 7- param-select “in”:
Ascending order- param-select “Flavor”:
Fast numeric sort- Sort - data in ascending or descending order ( Galaxy version 1.1.1) with the following parameters:
- param-file “Sort Query”:
olympics.tsv- param-text “Number of header lines”:
1`- Column selections
- param-select “on column”:
Column 12(year column)- param-select “in”:
Descending order(most recent on top)- param-select “Flavor”:
Fast numeric sort- param-repeat Insert Column selections- param-select “on column”:
Column 7(height column)- param-select “in”:
Descending order(tallest first)- param-select “Flavor”:
Fast numeric sort
Filtering
This file contains a lot of data, but we may only be interested in a subset of this data. For example, we may only want to look at one particular Olympics, or one particular sport. In such cases we can filter the dataset. This will create a new dataset, removing any rows that are not of interest to us (i.e. that don’t meet the criteria we provide).
Filtering based on column contents
Hands On: Filter table based on a columnWe will filter the file to show only winter Olympics
Look at the
olympics.tsvfile and answer the following questionsQuestion
- Which column contains this information?
- Which values can this column have? (make sure to notice capitalisation, ‘Winter’ is not the same as ‘winter’ to these tools)
- Column 13, the column with the season header
- The values can be
SummerorWinter- Open the tool Filter data on any column using simple expressions
- read the help text at the bottom of the tool carefully
- get familiar with how to indicate columns and write expressions for filtering
Question
- How would you write the expressions for the following conditions:
- column 6 must be ‘Yes’
- column 13 must be smaller than 75
- column 7 cannot be ‘NA’
- column 2 cannot be empty
- It is also possible to combine multiple conditions, using
and,or,notand parentheses How would you write expressions for the following filtering conditions:
- column 5 is larger than 2 or smaller than -2
- column 5 is larger than 2 and smaller than 10
- the sum of columns 4 and 6 is greater than or equal to 25,000
- The answers are:
c6=='Yes'c13<75c7!='NA'c2!=''- The answers are:
c5>2 or c5<-2c5>2 and c5<10c4+c6 >= 25000Ok, great, now that you’ve got the hang of writing expressions for this tool, let’s create a file with only Winter Olympics:
- Filter data on any column using simple expressions with the following parameters:
- param-file “Filter”:
olympics.tsv- param-text “With the following condition”:
c13=='Winter'- param-text “Number of header lines to skip”:
1galaxy-eye View the filtered file.
QuestionHow many lines are in this file? (Hint: expand the dataset in your history or use Line/Word/Character count )
44,681 (this is including the header line)
Repeat the step for the Summer Olympics
Question
- How many lines do you expect in this file?
- How many lines are in this file? Were you right?
- Use the Line/Word/Character count to find the number of lines in the
olympics.tsvfile and subtract the number of rows in the Winter Olympics file- Be careful to consider whether these counts include the header line of the file or not
- The original file has 234,523 lines, and the Winter Olympics had 44,681 lines. So we would expect 234,523 - 44,681 = 189,842 rows of data. Since we have subtracted the header line in this equation as well, we expect the Summer Olympics file to have 1 more line that this, so 189,843 total lines.
- 189,843. If you were off by one or two lines, it may have been that you counted the header lines double.
It is always useful to take a moment to think about the expected outcome; this makes it easier to spot mistakes and will save you time in the long run.- Rename galaxy-pencil both outputs to something descriptive (e.g.
Filter: Winter Olympics onlyetc)
- This is primarily to get you into the habit. If this is a file you might want to view or use again later, it will be hard to find back again unless you name it well.
Advanced Filtering with Python Syntax
In addition to basic filtering, the Galaxy filtering tool allows for more advanced filtering using Python syntax. This can be particularly useful when you need to apply more complex conditions or manipulate the data in specific ways.
Comment: Understanding Python Syntax for FilteringBefore we dive into specific examples, let’s briefly discuss some basic Python concepts that will help you understand how to write these filtering expressions:
Methods: In Python, methods are functions that are associated with an object. For example, in the expression
c2.startswith('Liu'),startswithis a method that checks if the value in column 2 (c2) starts with the substring ‘Liu’.Boolean Expressions: These are expressions that evaluate to either
TrueorFalse. For example,c2.startswith('Liu')will returnTrueif the value in column 2 starts with ‘Liu’, andFalseotherwise.Comparison Operators: These include
==(equal to),!=(not equal to),<(less than),>(greater than),<=(less than or equal to), and>=(greater than or equal to). These operators are used to compare values and are commonly used in filtering.String Methods: Strings in Python have several built-in methods that can be used for filtering. Some commonly used ones include:
startswith(substring): Checks if a string starts with a specified substring.endswith(substring): Checks if a string ends with a specified substring.find(substring): Returns the lowest index of the substring if it is found in the string; otherwise, it returns-1.count(substring): Returns the number of non-overlapping occurrences of the substring in the string.
These concepts will be used in the filtering expressions we write in Galaxy. Let’s now explore some specific scenarios where you might use these expressions.
Filtering Based on Substring Occurrence
We want to filter rows where a particular column contains a specific substring using the cX.find() method, where X is the column number.
For example, while you can easily filter Summer or Winter Olympics using c13=="Summer" or c13=="Winter" if the data is stored in a dedicated column, sometimes the data may not be that straightforward. The relevant information might be embedded in another column, like in c11 with entries such as “1992 Summer Olympics”.
In such cases, you can use substring filtering:
Question
- How would you filter the rows where the 11th column contains “Summer”?
- How would you filter the rows where the 11th column does not contain “Summer”?
c11.find('Summer') != -1c11.find('Summer') == -1
Hands On: Filtering Based on Substring OccurrenceOk, great, now that you’ve got the hang of writing expressions for this tool, let’s filter the file for rows where column 11 contains “Summer”:
- Filter data on any column using simple expressions with the following parameters:
- param-file “Filter”:
olympics.tsv- param-text “With the following condition”:
c11.find('Summer') != -1- param-text “Number of header lines to skip”:
1galaxy-eye View the filtered file.
Question
- How many rows contained the string “Summer” in column 11? (Hint: use Line/Word/Character count )
189843(this is including the header line)- Rename galaxy-pencil both outputs to something descriptive.
Filtering Rows that Start or End with a Specific Value
Filter rows based on whether a column starts or ends with a particular value using cX.startswith() or cX.endswith().
For example, if we want to:
- Find all athletes whose names start with “Liu”.
- Find all teams whose names end with “China”.
Question
- How would you filter rows where the 2nd column starts with “Liu”?
- How would you filter rows where the 9th column ends with “China”?
c2.startswith('Liu')c9.endswith('China')
Hands On: Filtering Rows that Start or End with a Specific ValueOk, great, now that you’ve got the hang of writing expressions for this tool, let’s filter the file to find all athletes whose names start with “Liu”:
- Filter data on any column using simple expressions with the following parameters:
- param-file “Filter”:
olympics.tsv- param-text “With the following condition”:
c2.startswith('Liu')- param-text “Number of header lines to skip”:
1galaxy-eye View the filtered file.
Question
- How many rows contained the string start with “Liu” in column 2? (Hint: expand the dataset in your history or use Line/Word/Character count )
324(this is including the header line)- Rename galaxy-pencil both outputs to something descriptive.
Filtering Based on the Count of Substring Occurrences
Sometimes, you may need to filter rows based on how many times a certain substring appears in a column. This can be done using the cX.count() method.
For example, if we want to find athletes with three-part names by counting spaces in the name column.
Hands On: Filtering Based on the Count of Substring OccurrencesWe want to filter the dataset to find athletes with three-part names.
Have a look at the
olympics.tsvfileQuestion
- Which column contains the names of athletes?
- For athletes with 3-part names, how many spaces do we expect in that column?
- What expression would you use to find these cases?
- Column 2 contains the names
- For 3-part names we expect 2 space characters
c2.count(' ') == 2- Filter data on any column using simple expressions with the following parameters:
- param-file “Filter”:
olympics.tsv- param-text “With the following condition”:
c2.count(' ') == 2- param-text “Number of header lines to skip”:
1galaxy-eye View the filtered file.
Question
- How many rows contain three-part names (i.e., two spaces) in column 2?
11259(this is including the header line)Exercises. Now let’s take it a step further and filter athletes with even longer names.
Question
- How would you filter rows where the 2nd column contains three spaces (i.e., four-part names)?
- How many medals were won by athletes with five-part names or more?
- How many parts does the longest name have? Give an example of such a name.
- Bonus: How many athletes have 6-part names won a medal?
- None ;)
- You can also use greater than or less than symbols in your expression. You can filter on two lines using logical operators like
and.- Keep increasing the count until no results are returned
- The number of lines returned indicates the number of medals won by long-named athletes, to find out how many different athletes have such a name, we can use the Count - occurrences of each record tool on Column 2.
c2.count(' ') == 3c17 != 'NA' and c2.count(' ') >= 4returns 27 lines, meaning 26 medals won accounting for the header line excluding the header line. Appart from the name you need to additionally filter out athletes that did not won a medal.c2.count(' ') == 5is the maximum value to still return results. Five spaces means a 6-part name. For example Patricia Galvin de la Tour d’Auvergnec17 != 'NA' and c2.count(' ') == 5returns 5 records. So 5 medals were won by these long-named athletes. Using the Count - occurrences of each record to count occurrences in column 2, we discover that there are 3 different athletes with 6-part names.
Exercises
Ok, time to train! let’s see if you can use the Filter tool to answer the following questions:
Exercise: Medal winners
- How many gold medals were handed out?
- How many total medals?
- How many medals were handed out during the 2018 Olympics?
- How many medals were won by individuals with a height between 170 and 180 cm?
- How many gold medals were won by individuals shorter than 160cm or taller than 190?
- Column 17 contains information about medals
- The possible values are
Gold,Silver,Bronze, and `` (empty).- Expand the output or use the tool Line/Word/Character count to see the number of lines in the file
- Don’t forget that the output (and line count) may include the header line
- Do not use quotes on number columns (e.g. year)
- You may need parentheses for complex conditions
- 8,110 (Expression:
c17=='Gold')- 24,633 (Expression:
c17=='Gold' or c17=='Silver' or c17=='Bronze', orc17!='NA')- 131 (Expression:
c17=='Gold' and c12==2018(note: do not use quotes around2018, as it is a numerical value))- 8,086 (Expression:
c17!='NA' and c7>=170 and c7<=180)- 812 (Expression:
c17=='Gold' and (c7<160 or c7>190)(note: parentheses are important here))Note: these numbers are found by determining the number of lines in the file after each filtering step, and subtracting 1 for the header line.
Counting
A common operation we might want to perform on tables of data, is simple counting. How many times does a certain value appear? For our dataset for instance, we might want to know how many countries participated in each Olympics, how many women, etc; any column that has categorical data that we can count. The tool Count occurrences of each record does exactly this.
Hands On: Count occurrences of values in columnsLet’s start by simply counting how many different Olympic Games we have in our dataset, and how many times it appears (so how many participations there were each year)
- Count occurrences of each record with the following parameters
- param-file “from dataset”:
olympics.tsv- param-select “Count occurrences of values in column(s)”:
Column 11galaxy-eye View the results.
Question
- How many different Olympic games are in our file?
- Which Olympic games had the most participations? (Tip: set the parameter “How should the results be sorted?” to
most common values first)
52; there are 53 lines in the resulting file, with one line containing the value of the column header (
games).The resulting file looks something like:
615 1896 Summer Olympics 2503 1900 Summer Olympics 2643 1904 Summer Olympics 3213 1908 Summer Olympics 4610 1912 Summer Olympics 3448 1920 Summer Olympics 5242 1924 Summer Olympics 358 1924 Winter Olympics 4493 1928 Summer Olympics ...1996 Summer Olympics. (10501 participations)
You may have noticed that we could have selected multiple columns in this tool. This lets us count on combinations of columns. Let’s try counting the number of men and women in each olympic games.
- Count occurrences of each record with the following parameters
- param-file “from dataset”:
olympics.tsv- param-select “Count occurrences of values in column(s)”:
Column 11, Column 3galaxy-eye View the results.
QuestionYou see the resulting file has a line for every combination of the two columns (games and sex), providing the count for each.
How many women were in the first Olympic games?
Which Olympic games had the most women participants? (Tip: set the parameter “How should the results be sorted?” to
most common values first)
- 2 women participated in the 1896 Olympics. (note that we cannot be sure if this is two different women, or 1 woman participating twice). The file looks something like this:
2 F 1896 Summer Olympics 43 F 1900 Summer Olympics 17 F 1904 Summer Olympics 55 F 1908 Summer Olympics 97 F 1912 Summer Olympics 132 F 1920 Summer Olympics 269 F 1924 Summer Olympics- 2020 Summer Olympics (4652)
Let’s say we wanted to know how many different sports there were in each Olympics. If we used the counting tool above, we would get a results file for each combination of sport and olympics, with the number of lines (participations) of each. But we don’t really care about the number of lines that have this combination, just the total number of unique sports in each games.
To answer these types of questions we can use a slightly more advanced tool, called Datamash ( Galaxy version 1.1.0+galaxy2). This tool can do a lot more than counting, but here we will show you how to use it to count in this way.
Hands On: Counting number of different sports per Olympic GamesWe will now determine how many different sport there were in each of the different Olympics
- Datamash ( Galaxy version 1.1.0+galaxy2) with the following parameters:
- param-file “Input tabular dataset”:
olympics.tsv- param-text “Group by fields”:
11(thegamescolumn)- param-toggle “Input file has a header line”:
Yes- param-toggle “Sort Input”:
Yes- “Operation to perform on each group”:
- param-select “Type”:
Count Unique values- param-select “On Column”:
Column: 15(thesportcolumn)galaxy-eye View the results.
Question
- Why did we tell the tool to sort the file?
- How many sport were in the first Olympics? How many in the latest?
- Which Olympics had the most different sports?
- This is for technical reasons; the tool assumes that your file is sorted (on the column that you supplied to the “Group by fields” parameter). This assumption can greatly speed up the calculation, but will give incorrect results if the file was not actually sorted. If you know for sure that your data is sorted in the right way, you can skip this step. If you are unsure, enable this parameter to be safe, and the tool will perform the sorting step before its calculation.
- 10 and 38.
- The 2020 Summer Olympics had the most different sports (38)
- Rename galaxy-pencil the output to something descriptive
Note: Datamash can do a lot more than counting, and we will showcase some of these other operatins in the Grouping section.
Exercises
Ok, let’s practice!
Exercise: Number of participations per country
- Which country has had the most participations in the Olympics?
- How many countries participated in the first Olympics? How many in the last?
- Since we are counting participations (rows), we can use the simple Count tool
- Since we are counting a bit more complex question, we need the Datamash ( Galaxy version 1.1.0+galaxy2) tool
- The United States with 17,286 participations
- 15 and 250.
- Count with the following parameters:
- param-file “from dataset”:
olympics.tsv- param-select “Count occurrences of values in column(s)”:
Column 9(theteamcolumn)- param-select “How should the results be sorted?”:
With the most common values firstThis gives an output like:
17286 United States 11700 France 10230 Great Britain 8898 Italy 7988 Canada- Datamash ( Galaxy version 1.1.0+galaxy2) with the following parameters:
- param-file “Input tabular dataset”:
olympics.tsv- param-text “Group by fields”:
11(thegamescolumn)- param-toggle “Input file has a header line”:
yes- param-toggle “Sort Input”:
yes- “Operation to perform on each group”:
- param-select “Type”:
Count Unique values- param-select “On Column”:
Column: 9(theteamcolumn)This gives an output like:
1896 Summer Olympics 15 1900 Summer Olympics 29 1904 Summer Olympics 13 ... 2016 Summer Olympics 280 2018 Winter Olympics 108 2020 Summer Olympics 250
Grouping
Often we may want to group rows based on a value in a column, and perform some operation on the resulting rows. For example we would like to group the olympics data by one value (e.g. year, country, sport), and determine some value for each group (e.g. number of medals won, average age of athletes, etc).
In the counting section of this tutorial we show how to get answers that require a count (e.g. number of medals won), but sometimes we want to do something more complex, like calculating the average height of athletes in a group, say per country or per sport. This section will show some example of these types of questions.
We can use the Datamash ( Galaxy version 1.1.0+galaxy2) tool for this purpose.
Hands On: Tallest athlete per sportWe would like to answer the following question: How tall was the tallest athlete of each sport?
Open the Datamash ( Galaxy version 1.1.0+galaxy2) tool and read the help section at the bottom
QuestionWhich settings do you think we need to provide to answer our question?
- “Group by fields”: We want to group by sport (Column 15).
- “Sort”:
Yes. This may not be obvious, but because our file is currently not sorted by our chosen group (sport), we need to tell the tool to do this.- “Skip NA or NaN values”: since we do have NA values for athletes for whom height data is unknown, we should set this to
Yes- Our file has a header line, so we should indicate this as well
- “Operation”: we want to determine the Maximum height (Column 7)
- Datamash ( Galaxy version 1.1.0+galaxy2) with the following parameters:
- param-file “Input tabular dataset”:
olympics.tsv- param-text “Group by fields”:
15- param-toggle “Sort input”:
yes- param-toggle “Input file has a header line”:
yes- param-toggle “Skip NA or NaN values”:
yes- “Operation to perform on each group”:
- param-select “Type”:
Maximum- param-select “On Column”:
Column: 7galaxy-eye View the results.
Question
- How tall was the tallest athlete in basketball? And what about karate?
- Why do some sports have a value of
inf?
- Basketball’s tallest athlete was 192cm. For Karate it is 163.
- Our dataset had quite a number of
NA(unknown) values in the height column, especially for the earlier Olympics. For sports that had only NA values, there is no maximum so the tool outputsinfinstead.
Grouping on multiple columns
You may have noticed that we could also provide multiple columns to group on. If we do this, we can compute values for combinations of groups, such as sex and sport, to find e.g. the tallest woman in basketball or the shortest man per Olympics. There are also many more options for the computation we perform, so perhaps we are more interested not in the tallest athlete, but the average height. Let’s perform some of these slightly more advanced queries now.
Hands On: Average height of men and women per sportThe question we would like to answer here, is what is the average height for men and women per sport?
- Open the Datamash ( Galaxy version 1.1.0+galaxy2) tool
- Which parameters do you think we need?
- Refer to the help section at the bottom of the tool page if you need more information
- Datamash ( Galaxy version 1.1.0+galaxy2) with the following parameters:
- param-file “Input tabular dataset”:
olympics.tsv- param-text “Group by fields”:
15,3(The sports column, and the sex column)- param-toggle “Sort input”:
yes- param-toggle “Input file has a header line”:
yes- param-toggle “Print header line”:
yes- param-toggle “Skip NA or NaN values”:
yes- “Operation to perform on each group”:
- param-select “Type”:
Mean- param-select “On Column”:
Column: 7- galaxy-eye View the results.
- Notice the header line in this output that we requested with the “Print header line parameter”. Adding this line will help you remember which columns you grouped on and which computation you performed. In our case it was obvious, but if you have a dataset with multiple columns with similar values, this can be useful
- See if you can answer the following questions based on the output file.
Question
- What is the average height of women participating in archery?
- What is the average height of men participating in ballooning?
- Why do some values have
naninstead of a height?- Why do some sports not have a value for one of the sexes?
- Can you find a sport where women were taller than the men? (Hint: it starts with the letter A)
- 167.25677031093 cm
- 170 cm
- If none of the rows in the group had height data available, it will output
nan(not a number) instead. This is most common for sports that were only featured a few times in the early years of the Olympics.- Sports such as artistic swimming only exist for women, so no M appears in the data for that group, so there simply is no row for the mean height of men doing artistic swimming in our output.
- Art Competitions
If all went well, your output file should look something like:
GroupBy(sport) GroupBy(sex) mean(height) Aeronautics M nan Alpine Skiing F 167.38324708926 Alpine Skiing M 178.18747142204 Alpinism M nan Archery F 167.25677031093 Archery M 178.5865470852 Art Competitions F 175.33333333333 Art Competitions M 173.97260273973 Artistic Gymnastics F 156.15316901408
Exercises
Exercise: Grouping and computing
- How tall is the shortest woman Badminton player to win a gold medal?
- What is the average height and standard deviation of athletes from Denmark (DEN) in the 1964 Olympics?
- Can you determine how heavy the heaviest tennis player in the 2020 Olympics is? Why not?
- We need to group on 3 columns: medals, sport and sex (note: the order you provide the columns determines the order they are listed in in the output)
- We need to group on 2 columns: country (team) and year, then compute 2 things: the average (mean) and population standard deviation over column 7 (height). (explanation of sample vs population standard deviation)
- You should get an error message here, try to read it carefully to find out why it didn’t work, and how we might be able to fix it (Tip: troubleshooting errors HOWTO)
TIP: You can use CTRL+F in your browser to search for values in the file (e.g. “Badminton”)
- 161 cm.
- mean height: 175.91304347826, standard deviation: 7.0335410308672`
- We get an error message saying:
datamash: invalid numeric value in line 2434 field 8: '63-67'. So from this we see that our weight column is not always a single number, but sometimes a range, such as63-67(kg), e.g. for sports with weight classes such as boxing. Datamash does not know how to handle such values, and will therefore fail. If we want to do this computation, we will have to clean up our data first (e.g. by replacing each range by its upper or lower value. We will do this in the final exercise section of this tutorial)
- Datamash ( Galaxy version 1.1.0+galaxy2) with the following parameters:
- param-file “Input tabular dataset”:
olympics.tsv- param-text “Group by fields”:
17,15,3(The medal, sports, and the sex columns)- param-toggle “Sort input”:
yes- param-toggle “Input file has a header line”:
yes- param-toggle “Print header line”:
yes- param-toggle “Skip NA or NaN values”:
yes- “Operation to perform on each group”:
- param-select “Type”:
Minimum- param-select “On Column”:
Column: 7This will give an output like below, scroll down to find the gold medalists, then badminton, then F (if you used a different order in the Group by fields parameter, this file may look a bit different, but will still provide the same information)
GroupBy(medal) GroupBy(sport) GroupBy(sex) min(height) Bronze Alpine Skiing F 156 Bronze Alpine Skiing M 167 Bronze Archery F 155 Bronze Archery M 166 Bronze Art Competitions F -inf Bronze Art Competitions M 172 Bronze Artistic Gymnastics F 136 ...- Datamash ( Galaxy version 1.1.0+galaxy2) with the following parameters:
- param-file “Input tabular dataset”:
olympics.tsv- param-text “Group by fields”:
12,9(year and team columns)- param-toggle “Sort input”:
yes- param-toggle “Input file has a header line”:
yes- param-toggle “Print header line”:
yes- param-toggle “Skip NA or NaN values”:
yes- “Operation to perform on each group”:
- param-select “Type”:
Mean- param-select “On Column”:
Column: 7- param-repeat “Insert Operation to perform on each group”:
- param-select “Type”:
Population Standard deviation- param-select “On Column”:
Column: 7This will give an output like below:
GroupBy(year) GroupBy(team) mean(height) pstdev(height) 1896 Australia nan nan 1896 Austria nan nan 1896 Belgium nan nan 1896 Bulgaria nan nan 1896 Denmark nan nan 1896 France 167.62962962963 4.6836844324555 ...Any calculations you run which try to compute anything over the weight column (Column 8) will fail. Please see the final exercise section for the solution to this question, in which we will first clean up the data in the weight column using the Find and Replace operation.
This type of situation occurs quite frequently, where your data does not fit with your expectations or assumptions, and you may have to perform additional data manipulation steps to clean up your data. It is very useful to know how to read the error messages of tools. Depending on the tool, the error messages may or may not be very informative, but in many cases it can give you a clue as to why it failed, which sometimes can be fixed by you. If you think it is a problem with the tool itself, please submit a bug report, and the tool authors will be able to have a look at it. More information about troubleshooting and reporting errors can be found in this FAQ
Computing
Sometimes we want to use the data in our column to compute a new value, and add that to the table. For instance, for our dataset we could caluclate athtletes BMI (using height and weight columns), or their age at time of participation (from year of birth and year of the Olymics). By adding these computed values as a new colum to our datset, we can more easily query the dataset for these values. We can do these types of operations using the Compute on rows ( Galaxy version 2.0) tool.
As an example, let’s calculate the age of each athlete at the time of participation, and add this as a new column to our dataset.
Hands On: Compute age of athletes
- Open the Compute on rows ( Galaxy version 2.0) tool.
- read the help text at the bottom of the tool
- what parameters do you think we need to use?
- Compute on rows ( Galaxy version 2.0) with the following parameters:.
- param-file “Input file”:
olympics.tsv- param-toggle “Input has a header line with column names?”:
Yes- In “Expressions”:
- param-text “Add expression”:
int(c12)-int(c4)(year column minus the year_of_birth column)- param-select “Mode of the operation?”:
Append- param-text “The new column name”:
age- Under “Error handling”:
- param-toggle “Autodetect column types”:
No- param-select “If an expression cannot be computed for a row”:
Fill in a replacement value- param-select “Replacement value”:
NA (not available)galaxy-eye View the results.
Question
Why did we set up the Error handling section of the tool like we did?
The help at the bottom of the tool interface has a section dedicated to its handling of errors. Read it and try to relate it to the detailed contents of our input data. You can also try rerunning the tool with any of the Error handling settings changed and see what happens.
- What changed in our file?
- How old was Arnaud Boetsch during his Olympic tennis participation?
- Rationale behind Error handling settings
- We disabled column type autodetection because some of the numerical columns in our input have “NA” values. The tool would figure out that the columns are meant to hold numbers, but would then fail to convert these “NA” values to a number. Without column type autodetection the tool will treat all column values as strings (words) and that is why we have to use
int()in the expression to compute, which says: take the value in parentheses and convert it to an integer number.- We configured ‘NA’ as the replacement value to use in rows for which our expression cannot be computed. If you inspect the input data carefully, you will find that some rows do not specify a year of birth of the athlete (look at athlete IDs 13 and 14 for example). Since the tool would not be able to compute our expression on such lines we needed to specify what to do instead.
- A new
agecolumn was added to the end of our file, the value is the age of the athlete in years at time of the olympics.- Arnaud Boetsch is listed on lines 6 and 7. He turned 27 the year of the Olympics in Atlanta.
- Rename galaxy-pencil the output to something descriptive (e.g.
Compute: add age column)
This was a simple computation, but much more complex mathematical expressions can be computed with this tool. See the help section at the bottom of the tool for a list of all supported operations. In the exercise below, we will compute the BMI for each athlete as an example.
Exercises
BMI stands for Body Mass Index, is a metric to provide a very crude measure of how healthy your weight is. The formula to compute BMI is:
\[BMI = weight / (height^2)\](with weight in kilograms and height in meters).
Adolphe Quetelet, who invented BMI, was not a doctor of medicine, instead he was a Belgian astronomer, mathematician, statistician, and sociologist. His data consisted probably entirely of cisgender, white, european men and women Eknoyan 2007. In his defense, he did argue it should not be used at individual levels, however it came to be used as such due to simplicity. (See Wikipedia’s History section). BMI is a poor measure of health, especially for populations with high muscle content, and cannot be simply re-used as-is with anyone other than Anglo Saxons Caleyachetty et al. 2021, Wikipedia:Limitations.
However as it is an easy to calculate metric, we include the calculation here.
Let’s use the Compute on rows ( Galaxy version 2.0) tool to compute this data for all athletes and add it as a new column directly after the existing height and weight columns.
Exercise: Calculating BMI
- How would you express this calculation in the tool?
Remember that our height is in cm, and the formula expects height in meters
Try to apply the lessons learnt with regard to error handling from the previous age calculation, i.e. remember the problematic NA values in the weight and height columns.
- How do you configure the tool to insert the new BMI column directly to the right of the weight column?
- What is the BMI for Arnaud Boetsch?
- division is
/and multiplication is ` * ` .- The tool does not recognize the
^operation as exponentiation. You can useheight * heightorpow(height,2), or replace^with**.- Parentheses may be required.
Use
int(column)like before to tell the tool the columns contain numbersThis is only needed because the “NA” values will require disabling column type autodetection again.
Appendmode will add the newly computed column at the end of the row, but there are other options, too.
int(c8)/(int(c7)*int(c7))*10000(other variations are possible)- You can choose
Insert modeand specify column9as the insert position.- 22.69
- Compute on rows ( Galaxy version 2.0) with the following parameters:
- param-file “Input file”:
olympics.tsv- param-toggle “Input has a header line with column names?”:
Yes- In “Expressions”:
- param-text “Add expression”:
int(c8)/(int(c7)*int(c7))*10000- param-select “Mode of the operation?”:
Insert- param-text “Insert new column before existing column number”:
9- param-text “The new column name”:
BMI- Under “Error handling”:
- param-toggle “Autodetect column types”:
No- param-select “If an expression cannot be computed for a row”:
Fill in a replacement value- param-select “Replacement value”:
NA (not available)
Find and Replace
Often you may need to change the contents of a file a bit to fit the expectations of an analysis tool. For instance, our file uses NA for missing values, but other conventions included leaving the cell empty, or using NaN (not a number) instead. Or, when working with chromosomal data, you may need to add or remove the chr prefix from a column before using it as input to a certain tool. In such situations, we can find all occurrences of a certain pattern in our file, and replace it with another value.
If we want to perform such a replacement on a single column in our data, we can use the Column Regex Find and Replace ( Galaxy version 1.0.1) tool, or if we want to do a replacement on a line by line basis (e.g. if our data isn’t tabular and therefore doesn’t have columns), we can use the Regex Find and Replace ( Galaxy version 1.0.1) tool. Both of these tools are similar, in that they use regular expressions (or regex) to define a pattern to search for. Regular expressions are a standardized way to describe patterns, and while they can seem quite complex at first, with just a few of the basics and a bit of practice, you can perform powerful operations on large datasets with ease.
A few of the basics of regular expression, plus some links to further resources are given in the box below:
Regular expressions are a standardized way of describing patterns in textual data. They can be extremely useful for tasks such as finding and replacing data. They can be a bit tricky to master, but learning even just a few of the basics can help you get the most out of Galaxy.
Finding
Below are just a few examples of basic expressions:
Regular expression Matches abcan occurrence of abcwithin your data(abc|def)abcordef[abc]a single character which is either a,b, orc[^abc]a character that is NOT a,b, norc[a-z]any lowercase letter [a-zA-Z]any letter (upper or lower case) [0-9]numbers 0-9 \dany digit (same as [0-9])\Dany non-digit character \wany alphanumeric character \Wany non-alphanumeric character \sany whitespace \Sany non-whitespace character .any character \.literal . (period) {x,y}between x and y repetitions ^the beginning of the line $the end of the line Note: you see that characters such as
*,?,.,+etc have a special meaning in a regular expression. If you want to match on those characters, you can escape them with a backslash. So\?matches the question mark character exactly.Examples
Regular expression matches \d{4}4 digits (e.g. a year) chr\d{1,2}chrfollowed by 1 or 2 digits.*abc$anything with abcat the end of the line^$empty line ^>.*Line starting with >(e.g. Fasta header)^[^>].*Line not starting with >(e.g. Fasta sequence)Replacing
Sometimes you need to capture the exact value you matched on, in order to use it in your replacement, we do this using capture groups
(...), which we can refer to using\1,\2etc for the first and second captured values. If you want to refer to the whole match, use&.
Regular expression Input Captures chr(\d{1,2})chr14\1 = 14(\d{2}) July (\d{4})24 July 1984 \1 = 24,\2 = 1984An expression like
s/find/replacement/gindicates a replacement expression, this will search (s) for any occurrence offind, and replace it withreplacement. It will do this globally (g) which means it doesn’t stop after the first match.Example:
s/chr(\d{1,2})/CHR\1/gwill replacechr14withCHR14etc.You can also use replacement modifier such as convert to lower case
\Lor upper case\U. Example:s/.*/\U&/gwill convert the whole text to upper case.Note: In Galaxy, you are often asked to provide the find and replacement expressions separately, so you don’t have to use the
s/../../gstructure.There is a lot more you can do with regular expressions, and there are a few different flavours in different tools/programming languages, but these are the most important basics that will already allow you to do many of the tasks you might need in your analysis.
Tip: RegexOne is a nice interactive tutorial to learn the basics of regular expressions.
Tip: Regex101.com is a great resource for interactively testing and constructing your regular expressions, it even provides an explanation of a regular expression if you provide one.
Tip: Cyrilex is a visual regular expression tester.
Let’s start with a simple example:
Hands On: Find and ReplaceOur file uses a mix of
AthinaandAthensto indicate the Capital City of Greece in thecitycolumn. Let’s standardize this by replacing occurrences ofAthinawithAthens.
- Open Column Regex Find and Replace ( Galaxy version 1.0.1)
- Read the help text at the bottom, what settings do you think we need to use?
Read the Regular expressions 101 FAQ below
Regular expressions are a standardized way of describing patterns in textual data. They can be extremely useful for tasks such as finding and replacing data. They can be a bit tricky to master, but learning even just a few of the basics can help you get the most out of Galaxy.
Finding
Below are just a few examples of basic expressions:
Regular expression Matches abcan occurrence of abcwithin your data(abc|def)abcordef[abc]a single character which is either a,b, orc[^abc]a character that is NOT a,b, norc[a-z]any lowercase letter [a-zA-Z]any letter (upper or lower case) [0-9]numbers 0-9 \dany digit (same as [0-9])\Dany non-digit character \wany alphanumeric character \Wany non-alphanumeric character \sany whitespace \Sany non-whitespace character .any character \.literal . (period) {x,y}between x and y repetitions ^the beginning of the line $the end of the line Note: you see that characters such as
*,?,.,+etc have a special meaning in a regular expression. If you want to match on those characters, you can escape them with a backslash. So\?matches the question mark character exactly.Examples
Regular expression matches \d{4}4 digits (e.g. a year) chr\d{1,2}chrfollowed by 1 or 2 digits.*abc$anything with abcat the end of the line^$empty line ^>.*Line starting with >(e.g. Fasta header)^[^>].*Line not starting with >(e.g. Fasta sequence)Replacing
Sometimes you need to capture the exact value you matched on, in order to use it in your replacement, we do this using capture groups
(...), which we can refer to using\1,\2etc for the first and second captured values. If you want to refer to the whole match, use&.
Regular expression Input Captures chr(\d{1,2})chr14\1 = 14(\d{2}) July (\d{4})24 July 1984 \1 = 24,\2 = 1984An expression like
s/find/replacement/gindicates a replacement expression, this will search (s) for any occurrence offind, and replace it withreplacement. It will do this globally (g) which means it doesn’t stop after the first match.Example:
s/chr(\d{1,2})/CHR\1/gwill replacechr14withCHR14etc.You can also use replacement modifier such as convert to lower case
\Lor upper case\U. Example:s/.*/\U&/gwill convert the whole text to upper case.Note: In Galaxy, you are often asked to provide the find and replacement expressions separately, so you don’t have to use the
s/../../gstructure.There is a lot more you can do with regular expressions, and there are a few different flavours in different tools/programming languages, but these are the most important basics that will already allow you to do many of the tasks you might need in your analysis.
Tip: RegexOne is a nice interactive tutorial to learn the basics of regular expressions.
Tip: Regex101.com is a great resource for interactively testing and constructing your regular expressions, it even provides an explanation of a regular expression if you provide one.
Tip: Cyrilex is a visual regular expression tester.
- Column Regex Find and Replace ( Galaxy version 1.0.1) with the following parameters:
- param-file “Select cells from”:
olympics.tsv- param-select“using column”:
Column 14- param-repeat “Check”
- “Find Regex”:
Athina- “Replacement”:
Athens- galaxy-eye View the results.
- Look at the file before and after. Athlete 7 (Patrick Chila) near the top of the
olympics.tsvfile, had a value of Athina in the city column. Verify that it has been changed to Athens.QuestionWhy did we use the column replace tool, and not the general replace tool?
It is safer to use the column replace tool in our case. We know the city name only occurs in one of the columns. If we had used the line replace tool, it would have replaced all occurrences of
Athina, which may have unforeseen consequences (e.g. maybe somebody was named Athina, in that case we don’t want to replace it)
This was rather simple example, so let’s try a few more examples with slightly more complex expressions.
Exercises
You may have noticed that our file has a lot of missing data. Especially for the earlier years, things like height, weight and birthday of athletes was not registered, or simply not known. In some columns you see these missing values have been replaced with an NA (not available) value. In other columns (for example birth place), the cells have simply been left empty.
Different tools may expect different ways of handling missing data. So you may have to change your missing data from empty to NA, NaN, or something else, between analysis steps
Hands On: Fill empty cellsWe will now replace empty cells in the
birth_placecolumn, to useNAinstead
- Open Column Regex Find and Replace ( Galaxy version 1.0.1)
- Read the help text at the bottom, what settings do you think we need to use?
Read the Regular expressions 101 FAQ below
Regular expressions are a standardized way of describing patterns in textual data. They can be extremely useful for tasks such as finding and replacing data. They can be a bit tricky to master, but learning even just a few of the basics can help you get the most out of Galaxy.
Finding
Below are just a few examples of basic expressions:
Regular expression Matches abcan occurrence of abcwithin your data(abc|def)abcordef[abc]a single character which is either a,b, orc[^abc]a character that is NOT a,b, norc[a-z]any lowercase letter [a-zA-Z]any letter (upper or lower case) [0-9]numbers 0-9 \dany digit (same as [0-9])\Dany non-digit character \wany alphanumeric character \Wany non-alphanumeric character \sany whitespace \Sany non-whitespace character .any character \.literal . (period) {x,y}between x and y repetitions ^the beginning of the line $the end of the line Note: you see that characters such as
*,?,.,+etc have a special meaning in a regular expression. If you want to match on those characters, you can escape them with a backslash. So\?matches the question mark character exactly.Examples
Regular expression matches \d{4}4 digits (e.g. a year) chr\d{1,2}chrfollowed by 1 or 2 digits.*abc$anything with abcat the end of the line^$empty line ^>.*Line starting with >(e.g. Fasta header)^[^>].*Line not starting with >(e.g. Fasta sequence)Replacing
Sometimes you need to capture the exact value you matched on, in order to use it in your replacement, we do this using capture groups
(...), which we can refer to using\1,\2etc for the first and second captured values. If you want to refer to the whole match, use&.
Regular expression Input Captures chr(\d{1,2})chr14\1 = 14(\d{2}) July (\d{4})24 July 1984 \1 = 24,\2 = 1984An expression like
s/find/replacement/gindicates a replacement expression, this will search (s) for any occurrence offind, and replace it withreplacement. It will do this globally (g) which means it doesn’t stop after the first match.Example:
s/chr(\d{1,2})/CHR\1/gwill replacechr14withCHR14etc.You can also use replacement modifier such as convert to lower case
\Lor upper case\U. Example:s/.*/\U&/gwill convert the whole text to upper case.Note: In Galaxy, you are often asked to provide the find and replacement expressions separately, so you don’t have to use the
s/../../gstructure.There is a lot more you can do with regular expressions, and there are a few different flavours in different tools/programming languages, but these are the most important basics that will already allow you to do many of the tasks you might need in your analysis.
Tip: RegexOne is a nice interactive tutorial to learn the basics of regular expressions.
Tip: Regex101.com is a great resource for interactively testing and constructing your regular expressions, it even provides an explanation of a regular expression if you provide one.
Tip: Cyrilex is a visual regular expression tester.
Question
- Should we use the column or line replace tool?
- What is the expression for an empty line? (hint: see regular expressions 101 box above)
- Since we only want to replace in one column, we will use the column replace tool
^$indicates an empty line (^indicated the beginning, and$the end). The value in the column is treated as the line, since we are looking only in 1 column.- Column Regex Find and Replace ( Galaxy version 1.0.1) with the following parameters:
- param-file “Select cells from”:
olympics.tsv- param-select“using column”:
Column 6- param-repeat “Check”
- param-text “Find Regex”:
^$- param-text “Replacement”:
NA- galaxy-eye View the results.
- Look at the file before replacement, find a line without a value in the
birth_placecolumn. Verify that it has been replaced in the resulting file.
Let’s do another example, this one using capture groups.
Look at the birth_day column. It has values in a format like 12 December. Suppose we have a tool that expects this data to be in the reverse format, December 12. The file is too big to change this manually in every column. But with regular expression tools we can make this replacement easily
Hands On: Reverse Birthday FormatWe will now change the format in birthday column from
day monthtomonth day
- Open Column Regex Find and Replace ( Galaxy version 1.0.1)
- Read the help text at the bottom, what settings do you think we need to use?
Read the Regular expressions 101 FAQ below
Regular expressions are a standardized way of describing patterns in textual data. They can be extremely useful for tasks such as finding and replacing data. They can be a bit tricky to master, but learning even just a few of the basics can help you get the most out of Galaxy.
Finding
Below are just a few examples of basic expressions:
Regular expression Matches abcan occurrence of abcwithin your data(abc|def)abcordef[abc]a single character which is either a,b, orc[^abc]a character that is NOT a,b, norc[a-z]any lowercase letter [a-zA-Z]any letter (upper or lower case) [0-9]numbers 0-9 \dany digit (same as [0-9])\Dany non-digit character \wany alphanumeric character \Wany non-alphanumeric character \sany whitespace \Sany non-whitespace character .any character \.literal . (period) {x,y}between x and y repetitions ^the beginning of the line $the end of the line Note: you see that characters such as
*,?,.,+etc have a special meaning in a regular expression. If you want to match on those characters, you can escape them with a backslash. So\?matches the question mark character exactly.Examples
Regular expression matches \d{4}4 digits (e.g. a year) chr\d{1,2}chrfollowed by 1 or 2 digits.*abc$anything with abcat the end of the line^$empty line ^>.*Line starting with >(e.g. Fasta header)^[^>].*Line not starting with >(e.g. Fasta sequence)Replacing
Sometimes you need to capture the exact value you matched on, in order to use it in your replacement, we do this using capture groups
(...), which we can refer to using\1,\2etc for the first and second captured values. If you want to refer to the whole match, use&.
Regular expression Input Captures chr(\d{1,2})chr14\1 = 14(\d{2}) July (\d{4})24 July 1984 \1 = 24,\2 = 1984An expression like
s/find/replacement/gindicates a replacement expression, this will search (s) for any occurrence offind, and replace it withreplacement. It will do this globally (g) which means it doesn’t stop after the first match.Example:
s/chr(\d{1,2})/CHR\1/gwill replacechr14withCHR14etc.You can also use replacement modifier such as convert to lower case
\Lor upper case\U. Example:s/.*/\U&/gwill convert the whole text to upper case.Note: In Galaxy, you are often asked to provide the find and replacement expressions separately, so you don’t have to use the
s/../../gstructure.There is a lot more you can do with regular expressions, and there are a few different flavours in different tools/programming languages, but these are the most important basics that will already allow you to do many of the tasks you might need in your analysis.
Tip: RegexOne is a nice interactive tutorial to learn the basics of regular expressions.
Tip: Regex101.com is a great resource for interactively testing and constructing your regular expressions, it even provides an explanation of a regular expression if you provide one.
Tip: Cyrilex is a visual regular expression tester.
Question
- How do we match on the birthday format? How strict/exact should we be here?
- How do we captures both the day and the month?
- How do we refer to the values we captured (for the replacement value)
- Birthday is one or more digits, followed by a space, followed by one or more letters.
- Remember that you can capture values using parentheses
(..)\1will be the variable containing the value in the first capture,\2the second, etc
- There are multiple solutions here, depending on how strict you want to be
\d+ ([a-zA-Z]+)(not strict, would also match on142 Septober[0-9]{1,2} (January|February|March|April|May|June|July|August|September|October|November|December)(this is much more strict, only matches on 1 or 2 digits, followed by a space, followed by one of the months. But this would still match on 42 April, and may miss it if one month names didn’t start with a capital letter)[123]?[0-9] [a-zA-Z]+this will only allow dates below 40There are different ways to express this, and there is no one perfect solution. If you know your data is clean, and you do not have to worry about values like 42 Septober, then you can be less strict. If your data is less clean, you may be more worried about capturing things that aren’t valid birthdays and might want to be a bit stricter. It all depends on your data and use case.
([\d]{1,2}) ([a-zA-Z]+)captures both the day and the month- We can use
\1to refer to the day we captured, and\2for the month in our replacement.- Column Regex Finda and Replace ( Galaxy version 1.0.1) with the following parameters:
- param-file “Select cells from”:
olympics.tsv- param-select“using column”:
Column 5- param-repeat “Check”
- param-text “Find Regex”:
(\d{1,2}) ([a-zA-Z]+)(or your own variation)- param-text “Replacement”:
\2 \1(first month, then space, then day)- galaxy-eye View the results.
- Did it work? If not, no shame, it often takes some trial and error to get your expression right. Click the rerun galaxy-refresh button on the tool, and tweak your expression until it works.
Removing Columns
We can remove columns from a table using either Remove columns by heading ( Galaxy version 0.0.1) if your table has a header line, or Cut columns from a table if it does not (in this case we just indicate columns by their number). These tools can also be used to change the order of columns in your file. There is also the tool Advanced Cut columns from a table ( Galaxy version 1.1.0) that offers a few more options.
To do the reverse, adding one or more columns, we can use the Paste tool. This assumes we have the same number of rows in both files, already in the correct order. It is a very “dumb” tool that simple combines the two files next to each other.
Hands On: Remove columnsSuppose we want to simplify our file a bit. All we want is file with 4 columns: athlete name, sport, olympic games, and medals.
- Open the Remove columns by heading ( Galaxy version 0.0.1) tool and read the help text at the bottom.
- Which settings do you think we need?
- Remove columns by heading ( Galaxy version 0.0.1) with the following parameters:
- param-file “Tabular File”:
olympics.tsv- param-text “Header name”:
name- param-repeat “Header name”:
sport- param-repeat “Header name”:
games- param-repeat “Header name”:
medal- param-toggle “Keep named columns”:
Yesgalaxy-eye View the results.
Question
- How many rows and columns do you expect the output to have?
- We expect the same number of rows as the original dataset, but now only the 4 columns we requested to keep.
Notice that during this step, we also changed the order of the columns. This tool can also be used to re-arrange columns, if you supply all column names but in a different order.
Exercises
Exercise: Removing Columns
- Create a file with 4 columns: name, sport, games, medal (same task as the previous hands-on), but use the Cut columns from a table tool instead.
- Create a file that is similar to
olympics.tsv, but without the first column (athlete_id column)- You want to keep all the columns of
olympics.tsv, but change the order so thatsportandeventcome right after the athlete’s name.
- We need to determine the column numbers and provide these to the tool, rather than the column headers
- Think about what the “Keep named colums” parameter does to simplify the settings here
- Which of the two tools would be easier to use? (this can be a personal preference, but think about whether you would rather provide column names or numbers)
- Cut columns from a table using the following parameters:
- param-text “Cut Columns”:
c2,c15,c11,c17- param-select “Delimited By”:
TAB- param-file “From”:
olympics.tsv- Remove columns by heading ( Galaxy version 0.0.1) with the following parameters:
- param-file “Tabular File”:
olympics.tsv- param-text “Header name”:
athlete_id- param-toggle “Keep named columns”:
NoNote: the “Keep named columns” parameter determines whether we keep or remove the columns we specified. You could have obtained the same result by supplying all column names except the first one, and selecting “Keep named columns”:
No, but that would have been a lot more work.- Cut columns from a table using the following parameters:
- param-text “Cut Columns”:
c1,c2,c15,c16,c3,c4,c5,c6,c7,c8,c9,c10,c11,c12,c13,c14,c17- param-select“Delimited By”:
TAB- param-file “From”:
olympics.tsvNote: you can also use the Remove columns by heading ( Galaxy version 0.0.1), it just requires a bit more typing, but on the other hand it is also a bit less error-prone (i.e. it is easier to mix up column numbers than column names).
Unique
Sometimes, in the course of our data manipulations, we may end up with a file that has duplicate rows. In order to filter these out, we can use the Unique occurrences of each record ( Galaxy version 1.1.0) tool.
Let’s say we would like to create a list of all unique athletes (id and name).
Hands On: Obtaining list of unique athletesFirst we will cut just the
athlete_idandnamecolumns from our dataset (please see the Removing Columns section for more info on this step)
- Cut columns from a table using the following parameters:
- param-text “Cut Columns”:
c1,c2- param-select “Delimited By”:
TAB- param-file “From”:
olympics.tsvView galaxy-eye the resulting dataset
Question
- Do you see duplication? Why is that?
- Yes. For all athletes who participated more than once, the row will be identical.
- Unique - occurrences of each record ( Galaxy version 1.1.0) with the following parameters:
- param-file “File to scan for unique values”:
output from the first stepView galaxy-eye the resulting dataset
Question
- What happened to our header line? How could we fix that?
- How many unique athletes do we have?
- The unique tool has done some sorting internally, so our header line is not longer at the top. We could fix this in several ways:
- sort the file again to get it back to the top (using natural sort in descending order will work).
- or, we could have removed the header line before running Unique (with remove beginning tool), then add it back afterwards (with concatenate tool).
- 94,733; The resulting file has 94,734 lines (one of which is our header line)
Joining Files
This file contains a lot of information, but we may want to add more information. For example if we had a file with information about each country (population, capital city, etc), we could join that information with our Olympics data, to get a single file with all information in every row.
For example, if we would like to be able to group by continent, to e.g. count athletes, medals etc per continent, we will have to add a continent column to our file. To do this we would need a second file that maps each country to the corresponding continent. This is what we will do in the next hands-on section.
We obtained country information data from DataHub. More information about this file can be found in the description there. It has 56 columns with a wide variety of data about each country (from country codes, to capital city, languages spoken, etc)
Hands On: Get data
Import the file
country-information.tsvvia linkhttps://zenodo.org/record/6803028/files/country-information.tsv
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window
galaxy-eye View file.
Question
- How many columns does this file have?
- Which column(s) in this file are the same as in the
olympics.tsvfile?
- The country information file has 56 columns (see DataHub for more details).
- Both files have a
NOCcolumn with the 3-letter country code (NOCstands for National Olympic Committee). We can use this column to join the appropriate country data to each row in ourolympics.tsvfile.
We would now like to take our Olympics dataset as the basis, and add columns to every row of this file with some information about the country. In order to join, we will need to have one column that is shared between the two files, on which we can match. The NOC column is perfect for this because it is a defined standard. Both files also contain a column with the country name in it, which is also a possible candidate to use for joining, but because it is less standardised, it is safer to use the NOC column. For example, if one file uses “Netherlands”, while the other uses “The Netherlands” to indicate the same country, the joining will fail for these rows. So always make sure the columns you join on are compatible!
Hands On: Joining country information to the Olympics data.
- Open Join two Datasets side by side on a specified field, and read the help text at the bottom
- Which settings do you think we need to use?
- Join two Datasets side by side on a specified field with the following parameters:
- param-file “Join”:
olympics.tsv- param-select “using column”:
Column 10(thenoccolumn)- param-file “with”:
country-information.tsv- param-select “and column”:
Column 2(theNOCcolumn)- param-toggle “Keep the header lines?”:
Yesgalaxy-eye View the results.
Question
- What do you expect the output to look like? Were you right?
- How many columns are in the resulting file? What about the NOC column?
- What is a possible downside to this approach?
- All the columns from the country information file are added to the end of each row of our olympics dataset
- Our Olympics dataset had 17 columns, the country information file has 56 columns. Therefore, we have 17+56=73 columns in our resulting file. This also means the NOC column we joined on appears twice in our output.
- There is a lot of data duplication in this file now. The exact same country information is added to every line of every athlete from a certain country. This means much larger file size, and more usage of your quota. If you do not need all these columns, it could save you a lot of space to remove unneeded columns from the
country-information.tsvfile, before joining.
Concatenating
Concatenation of two files simple means putting the contents of the two files together, one after the other. Our dataset was created in 2021, but since then we’ve had another Olympic event, the 2022 Winter Olympics in Beijing. If we have the same data for this latest Olympics, we could simply add the rows from the 2022 games to our current file with data, in order to create a single file with all data from 1896 to 2022.
First, let’s get this data for the 2022 Olympics
Hands On: Get 2022 Olympics data
Import the file
olympics_2022.tsvvia linkhttps://zenodo.org/record/6803028/files/olympics_2022.tsv
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window
View galaxy-eye the new dataset, does it have the same structure as our original
olympics.tsvfile?Question
- Does the new file have the same structure?
- Can we simply add the lines of the new files to the end of our existing olympics dataset?
- Yes, this file has all the same columns, in the same order, so concatenation should be relatively straightforward.
- If we simply put the contents of this file after our existing dataset, we will have a second header line in the middle of our data rows. It is best to remove the header line from the second dataset after we have verified it is compatible. This way we will only add the real data rows to our dataset.
Since this new dataset has the exact same structure (number and order of columns), we can simply add the lines from this file to the end of our existing olympics.tsv file.
Hands On: Adding 2022 Olympics to our datasetFirst we need to remove the header line from the 2022 file (since these lines will be added to the end of our olympic dataset, we don’t want to have a second header line floating around in our file)
- Remove beginning of a file with the following parameters:
- param-text “Remove first”:
1- param-file “from”:
olympics_2022.tsvNow we can perform the concatenation:
- Concatenate multiple datasets or collections with the following parameters:
- param-file “Concatenate Datasets”:
olympics.tsv(this file will be first)- param-repeat “Insert Dataset”:
- param-file“Dataset”:
output from step 1(2022 data without the header)galaxy-eye View the results.
Question
- How many lines do you expect in the new file? Were you correct? (Hint: use Line/Word/Character count to count lines)
- Where are the lines of the 2022 Olympics?
- The
olympics.tsvfile had 234,523 lines, and theolympics_2022.tsvfile had 4076 lines. Both of these numbers include a header line, which we removed for the second file, so we expect our concatenated file to contain 234,523 + 4076 - 1 = 238,598 lines (which it does). Note that the estimated number of lines in the “quick view” (what you see when you click on the step to expand it) might be off by quite a bit (several thousand lines for example).- The new file has the entire contents of
olympics.tsvat the beginning of the file, followed by the contents of theolympics_2022.tsvfile at the end.
Now this only works so simply because our two datasets had the same structure; the same number of columns, in the same order. If your data comes from different sources, you may have to do some additional data manipulation before you can concatenate, e.g. to make sure the columns match, or how each file deals with missing data (empty cells, NA, NaN or something else).
Splitting Files
This dataset contains a lot of data, we might want to split the data into one file per Olympic games, or have one file for all the winter games, and another file for all the summer games. In these situtations, where we want to create new, smaller files, based on the values in a column, we can use the tool Split by group ( Galaxy version 0.6).
Tip: use this tool only if you want a separate file for all values in a column. For example, if you want a file for each Olympic games, use the split tool, but if you just want a file for one particular Olympics (say Tokyo 2020), you could simply use the Filter tools to extract the data from the full dataset, without making files for all the other Olympics as well.
Hands On: Splitting the dataset by OlympicsWe would like to create a separate file for each Olympic event.
- Open the tool Split by group ( Galaxy version 0.6), and read the help text at the bottom
- which settings do you think we need to use?
- Split by group ( Galaxy version 0.6) with the following parameters:
- param-file “File to select”:
olympics.tsv- param-select “on column”:
Column 11(thegamescolumn)- param-toggle “Include the header in all splitted files?”:
Yesgalaxy-eye View the results.
Question
- How many different files do we get?
- How many lines are in the file for the 1908 Summer Olympics?
- We get 1 collection with 52 files in it, one per Olympic games:
- 3214 lines
Exercises
Let’s practice this a bit more, see if you can use the split file to answer the following questions:
Exercise: sort by height
- Create two files, one for Summer Olympics, one for Winter Olympics. Which has more lines?
- Split the file by sport, how many sports have there been at the Olympics?
- Split the file by medal, would you expect the output files to be equal sizes?
- Split on the
seasoncolumn (Column 13)- Split on the
sportcolumn (Column 15)- Split on the
medalcolumn (Column 17)
- The summer olympics file has more lines (~180,000) than the winter olympics file (~45,000) (the first winter Olympics wasn’t held until 1924)
- Each file in the resulting collection represents a sport, there are 91 datasets in the collection, representing 91 different sports in the history of the Olympics.
- The files for gold silver and bronze are roughly equal, but not exactly (think of situations like shared second place, then 2 silver medals are handed out and no bronze medal)
Conclusion
These tools and operations covered in the tutorial are just a few examples of some of the most common operations. There are many more tools available in Galaxy that perform other data manipulations. We encourage you to look around the General Text Tools section in the Galaxy toolbox (left panel) to find and explore more data manipulation tools. The more comfortable you are performing these kinds of steps, the more you can get out of Galaxy!
Exercises: Putting it all together!
This section provides a number of exercises that require you to combine two or more of the techniques you learned in this tutorial. This is a great way to practice your data manipulation skills. Full solutions are provided for every exercise (i.e. all tools and settings), but for many of these exercises there will be multiple solutions, so if you obtained the same results in a different way, that is correct too!
Exercise 1: Finding shortest/lightest athleteIf you have done exercises in the sorting section, you noticed that finding the shortest athlete ever to compete was not easy, because all the rows with missing height data (
NA) in the column were sorted to the top. We need to filter out these values first, then perform our sort, so that our answer is on top.
- Find the shortest athlete ever to compete in the Olympics
- Find the shortest athlete of the Winter Olympics
- Find the lightest athlete of the most recent Summer Olympics
- You will need to filter out the columns with (
NA) in the height column first- You will need to filter by season as well
- You will need to filter out missing data in the weight column, filter out Summer Olympics, then sort (by 2 columns)
- Does the order in which you perform these steps matter?
- Lyton Mphande and Rosario Briones were both 127 cm tall, competing in boxing and gymnastics respectively
- Carolyn Krau was a 137 cm tall figure skater.
- Flávia Saraiva was the lightest athlete (31kg), she was a Artistic Gymnast from Brazil.
First we filter out the NA values from the height column:
Filter - data on any column using simple expressions with the following parameters:
- param-file “Filter”:
olympics.tsv- param-text “With following expression”:
c7!='NA'- param-text “Number of header lines to skip”:
1Then we can sort by height, in ascending order to get the shortest athletes on top:
Sort - data in ascending or descending order ( Galaxy version 1.1.1) with the following parameters:
- param-file “Sort Query”:
output from the previous step (filter)- param-text “Number of header lines”:
1`- Column selections
- param-select “on column”:
Column 7- param-select “in”:
Ascending order- param-select “Flavor”:
Fast numeric sortWe can take the output from the first exercise, and filter for only Winter Olympics:
Filter - data on any column using simple expressions with the following parameters:
- param-file “Filter”:
output from previous exercise- param-text “With following expression”:
c13=='Winter'- param-text “Number of header lines to skip”:
1First we filter out the NA values from the weight column:
Filter - data on any column using simple expressions with the following parameters:
- param-file “Filter”:
olympics.tsv- param-text “With following expression”:
c8!='NA'- param-text “Number of header lines to skip”:
1Then we can filter out only Summer Olympics:
Filter - data on any column using simple expressions with the following parameters:
- param-file “Filter”:
output from previous step- param-text “With following expression”:
c13=='Summer'- param-text “Number of header lines to skip”:
1Then we can sort by weigth, in ascending order to get the shortest athletes on top:
Sort - data in ascending or descending order ( Galaxy version 1.1.1) with the following parameters:
- param-file “Sort Query”:
output from the previous step- param-text “Number of header lines”:
1`- Column selections
- param-select “on column”:
Column 12(year column)- param-select “in”:
Descending order(most recent on top)- param-select “Flavor”:
Fast numeric sort- param-repeat Insert Column selections
- param-select “on column”:
Column 8(weight column)- param-select “in”:
Ascending order(lightest on top)- param-select “Flavor”:
Fast numeric sortIn this case, changing the order of these operations will still have led to the same answer. However, sorting takes more time than filtering, so it is usually faster to filter first, then do the sorting on a smaller file. Especially noticeable if you have large dataset.
Ok, let’s try another exercise! If you have done the exercises in the Grouping section, you will have noticed that we were not able
to perform computation on the weight column, because some of the values were weight classes, e.g. 63-78 (kg), and the Datamash ( Galaxy version 1.1.0+galaxy2)
tool could not handle such values. In this exercise, we will first clean up this weight column to avoid ranges (by taking the lower number in the range for every
row a weight range is used), and then answering the question a couple of questions around the weight of athletes.
Exercise 2: Data cleaning and computations of the weight column
- Get a list of all the values that occur in the weight column, take note of all the values that are not a single number or
NA; anything else should be cleaned up- Clean up the weight column (Column 8) so that we only have single numbers; weight classes (e.g.
63-78) should be replace by the lower bound (63) of that class- How heavy was the lightest woman competing in the Biathlon? And the heaviest?
- You can use the Count tool to get a list of all the different values that appear in Column 8
- You can use the Column Regex Find and Replace ( Galaxy version 1.0.1) tool to clean up the weight column. This tool is a bit complex, if you haven’t done so yet, we strongly recommend you work through the Find and Replace section first. To check if your cleaning worked, re-run galaxy-refresh the Count tool from step 1.
- Use the Datamash ( Galaxy version 1.1.0+galaxy2) tool to answer this question, make sure you use the cleaned up datset as input! Find the row showing Biathlon.
We see values such as
100-105, but also77,5,100, 104(notice the space!) and even76, 77, 79to indicate weight ranges or other unexpected weight values. All these variations must be converted to single numbers. For this example we will simply convert these ranges to their lower number, and remove the rest when we clean the column (taking the upper or median value would be equally valid, but for our solution we will remove everything after the first number.There are many possible regular expression that will clean this column. You can use a single check to catch all the exceptions, or use multiple, there is no one right answer. Check if your cleaning is successful using the Count tool again. Make sure you only have single number values in the weight column before proceeding to question 3 in this exercise. Also make sure the weights you have make sense (e.g. if you end up with columns having a weight of
0, something went wrong somewhere!)lightest woman weighed 45 kilograms, the heaviest 82.
- Count occurrences of each record with the following parameters
- param-file “from dataset”:
olympics.tsv- param-select “Count occurrences of values in column(s)”:
Column 8This should output a file like:
921 100 2 100, 104 2 100, 107 2 100-105 1 100-106 5 100-110 4 100-113 71 101 3 101-125 204 102 2 102, 103 4 102, 105 2 102-106 97 103 125 104 ...We will want to change weight ranges to single numbers in the next step
- Column Regex Find and Replace ( Galaxy version 1.0.1) with the following parameters:
- param-file “Select cells from”:
olympics.tsv- param-select“using column”:
Column 8- param-repeat “Check”
- “Find Regex”:
(\d+)(,|-).*(one or more digits (captured), followed by a dash or comma, then zero or more of any other characters)- “Replacement”:
\1(only the first set of numbers we captured)NOTE: there will be a lot of valid answers here, you could do it all in one check like the solution above, or in multiple checks (e.g. one for each different kind of way to denote a weight range you found in step 1). As long as a re-run of the Count occurrences of each record tool shows only single numbers in the column after your find & replace step, then your answer was correct! Also make sure the weights make sense (e.g. if your resulting column has weights of
0or other small numbers, this doesn’t make sense and you will have to tweak your expression. Don’t feel bad if this takes a bit of trial and error, that is expected!- Datamash ( Galaxy version 1.1.0+galaxy2) with the following parameters:
- param-file “Input tabular dataset”:
olympics-cleaned.tsv(output from your cleaning step)- param-text “Group by fields”:
15,3- param-toggle “Sort input”:
yes- param-toggle “Input file has a header line”:
yes- param-toggle “Print header line”:
yes- param-toggle “Skip NA or NaN values”:
yes- “Operation to perform on each group”:
- param-select “Type”:
Minimum- param-select “On Column”:
Column: 8- param-repeat “Insert Operation to perform on each group”:
- param-select “Type”:
Maximum- param-select “On Column”:
Column: 8Your resulting file should look something like:
GroupBy(sport) GroupBy(sex) min(weight) max(weight) Aeronautics M -inf inf Alpine Skiing F 45 90 Alpine Skiing M 50 138 Alpinism M -inf inf Archery F 42 95 Archery M 46 130 Art Competitions F -inf inf Art Competitions M 59 93 ...
Congratulations! You have now mastered the basics of data manipulation! There are a lot more data manipulation operations available in Galaxy that you may need. Please explore the tools for yourself, and check back with this tutorial often, we plan to add more sections and exercises over time!
You've Finished the Tutorial
Key points
There are a lot of tools available in Galaxy for performing basic data manipulation tasks
Basic data manipulation is often needed between steps in a larger scientific analysis in order to connect outputs from one tool to input of another.
There are often multiple ways/tools to achieve the same end result
Having a basic understanding of data manipulation tools will make it easier to do exploratory data analysis
Always read the help text of the tool before using it to get a full understanding of its workings
Always try to formulate the output you are expecting from a tool. This will make it easier to spot mistakes as soon as possible.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsReferences
- Eknoyan, G., 2007 Adolphe Quetelet (1796 1874) the average man and indices of obesity. Nephrology Dialysis Transplantation 23: 47–51. 10.1093/ndt/gfm517
- Caleyachetty, R., T. M. Barber, N. I. Mohammed, F. P. Cappuccio, R. Hardy et al., 2021 Ethnicity-specific BMI cutoffs for obesity based on type 2 diabetes risk in England: a population-based cohort study. The Lancet Diabetes and Endocrinology 9: 419–426. 10.1016/s2213-8587(21)00088-7
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Saskia Hiltemann, Yongbin Li, Data Manipulation Olympics (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/introduction/tutorials/data-manipulation-olympics/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{introduction-data-manipulation-olympics, author = "Saskia Hiltemann and Yongbin Li", title = "Data Manipulation Olympics (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/introduction/tutorials/data-manipulation-olympics/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Funding
These individuals or organisations provided funding support for the development of this resource
Congratulations on successfully completing this tutorial!You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/introduction/tutorials/data-manipulation-olympics/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: split_file_on_column owner: bgruening revisions: 37a53100b67e tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: d698c222f354 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: d698c222f354 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: d698c222f354 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: column_maker owner: devteam revisions: 02026300aa45 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: regex_find_replace owner: galaxyp revisions: ae8c4b2488e7 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: datamash_ops owner: iuc revisions: 562f3c677828 tool_panel_section_label: Join, Subtract and Group tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: datamash_ops owner: iuc revisions: 746e8e4bf929 tool_panel_section_label: Join, Subtract and Group tool_shed_url: https://toolshed.g2.bx.psu.edu/