Aprendizaje sobre un gen a través de recursos y formatos biológicos
Under Development!
This tutorial is not in its final state. The content may change a lot in the next months. Because of this status, it is also not listed in the topic pages.
| Autores/as |
|
| Traducción |
|
| Revisores/as |
|
Descripción GeneralPreguntas:
Objetivos:
¿Cómo utilizar recursos de bioinformática para investigar una familia específica de proteínas (opsinas)?
¿Cómo navegar por el Genome Data Viewer para encontrar opsinas en el genoma humano?
¿Cómo identificar genes asociados con las opsinas y analizar su localización en los cromosomas?
¿Cómo explorar la literatura científica y los contextos clínicos relacionados con el gen OPN1LW?
¿Cómo usar archivos de secuencias proteicas para realizar búsquedas de similitud utilizando BLAST?
Partiendo de una búsqueda por texto, navega por múltiples recursos web para examinar distintos tipos de información sobre un gen, presentada en diversos formatos de archivo.
Duración estimada: 1 horaNivel: Introductorio IntroductoryMateriales de apoyo:Published: Mar 30, 2026Última modificación: Mar 30, 2026Licencia: El contenido de este tutorial tiene la licencia Creative Commons Attribution 4.0 International License. GTN Framework tiene licencia del MIT MITversion Revision: 1
Cuando realizamos un análisis bioinformático, por ejemplo RNA-seq, podemos acabar con una lista de nombres de genes. A continuación, necesitamos explorar estos genes. ¿Pero cómo podemos hacerlo? ¿Cuáles son los recursos disponibles para ello? ¿Y cómo navegar por ellos?
El objetivo de este tutorial es familiarizarnos con ello, utilizando como ejemplo las opsinas humanas.
Las opsinas humanas se encuentran en las células de la retina. Las opsinas captan la luz e inician la secuencia de señales que dan lugar a la visión. Procederemos formulando preguntas sobre las opsinas y los genes de opsina, y luego utilizaremos diferentes bases de datos y recursos bioinformáticos para responderlas.
ComentarioEste tutorial es un poco atípico: no trabajaremos en Galaxy sino principalmente fuera de él, navegando por bases de datos y herramientas a través de sus propios interfaces web. El objetivo de este tutorial es ilustrar varias fuentes de datos biológicos en diferentes formatos de archivo, y que representan información diferente.
AgendaEn este tutorial trataremos:
Búsqueda de Opsinas Humanas
Para buscar Opsinas humanas, empezaremos por consultar el Visor de Datos del Genoma del NCBI. El Visor de Datos del Genoma del NCBI (GDV) (Rangwala et al. 2021) es un navegador del genoma que permite la exploración y el análisis de ensamblajes de genomas eucariotas anotados. El navegador GDV muestra información biológica asignada a un genoma, incluida la anotación de genes, datos de variación, alineaciones BLAST y datos de estudios experimentales de las bases de datos NCBI GEO y dbGaP. Las notas de la versión GDV describen las nuevas características relacionadas con este navegador.
Práctica: Abrir el Visor de Datos del Genoma del NCBI
- Abra el visor de datos del genoma del NCBI en www.ncbi.nlm.nih.gov/genome/gdv
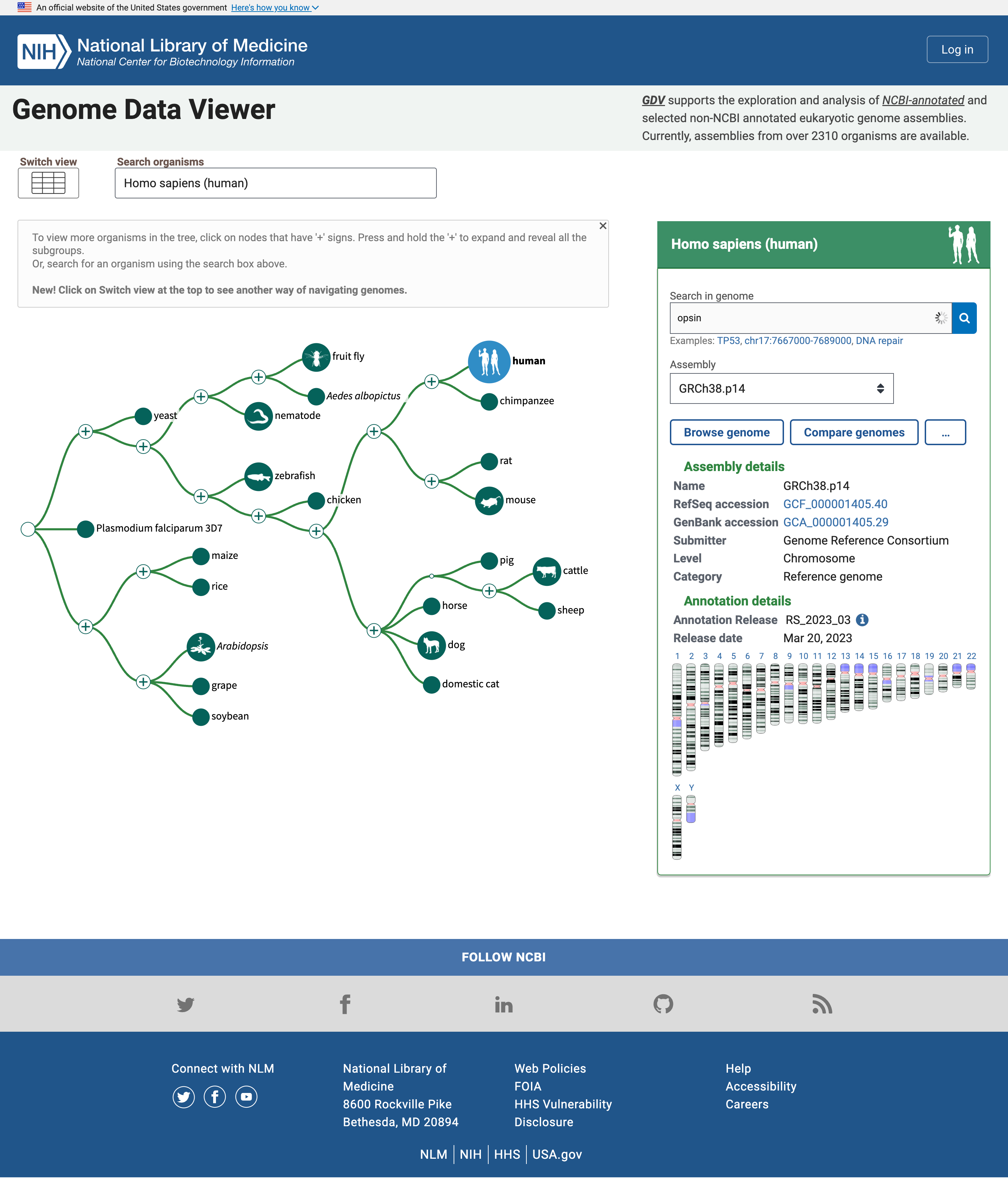
La página de inicio incluye un simple “árbol de la vida” donde el nodo humano está resaltado porque es el organismo por defecto para buscar. Podemos cambiar eso en la casilla Buscar organismos pero lo dejaremos por ahora ya que estamos interesados en las Opsinas Humanas.
 Open image in new tab
Open image in new tabEl panel de la derecha informa de múltiples ensamblajes del genoma de interés, y un mapa de los cromosomas en ese genoma. Allí podemos buscar Opsinas.
Práctica: Buscar Opsinas - Abrir el Visor de Datos del Genoma del NCBI
- Escriba
opsinen la casilla Buscar en genoma- Haga clic en el icono de la lupa o pulse Intro
Debajo del cuadro se muestra ahora una tabla con genes relacionados con la opsina junto con sus nombres y localización, es decir, el número de cromosoma, así como la posición inicial y final
En la lista de genes relacionados con el término de búsqueda opsina, aparecen el gen de la rodopsina (RHO), y tres pigmentos de los conos, opsinas sensibles a longitudes de onda corta, media y larga (para la detección de luz azul, verde y roja). Existen otras entidades, por ejemplo una -LCR (Locus Control region), genes putativos y receptores.
Múltiples coincidencias en el cromosoma X, uno de los cromosomas que determinan el sexo.
Preguntas
- ¿Cuántos genes se han encontrado en el cromosoma X?
- ¿Cuántos son los genes codificadores de proteínas?
- Los resultados en ChrX son:
- OPSIN-LCR
- OPN1LW
- OP1MW
- OPN1MW2
- OPN1MW3
- Al pasar el ratón por encima de cada gen, se abre un cuadro y podemos hacer clic en Detalles para saber más sobre cada gen. Entonces nos enteramos de que el primero (OPSIN-LCR) no codifica proteínas, sino que es una región reguladora de genes, y que los otros son genes codificadores de proteínas. Así que hay 4 genes codificadores de proteínas relacionados con las opsinas en el cromosoma X. En particular, el cromosoma X incluye un gen de pigmento rojo (OPN1LW) y tres genes de pigmento verde (OPN1MW, OPN1MW2 y OPN1MW3 en el ensamblaje del genoma de referencia).
Centrémonos ahora en una opsina específica, el gen OPN1LW.
Práctica: Buscador del genoma abierto para el gen OPN1LW
- Haga clic en la flecha azul que aparece en la tabla de resultados al pasar el ratón por encima de la fila OPN1LW
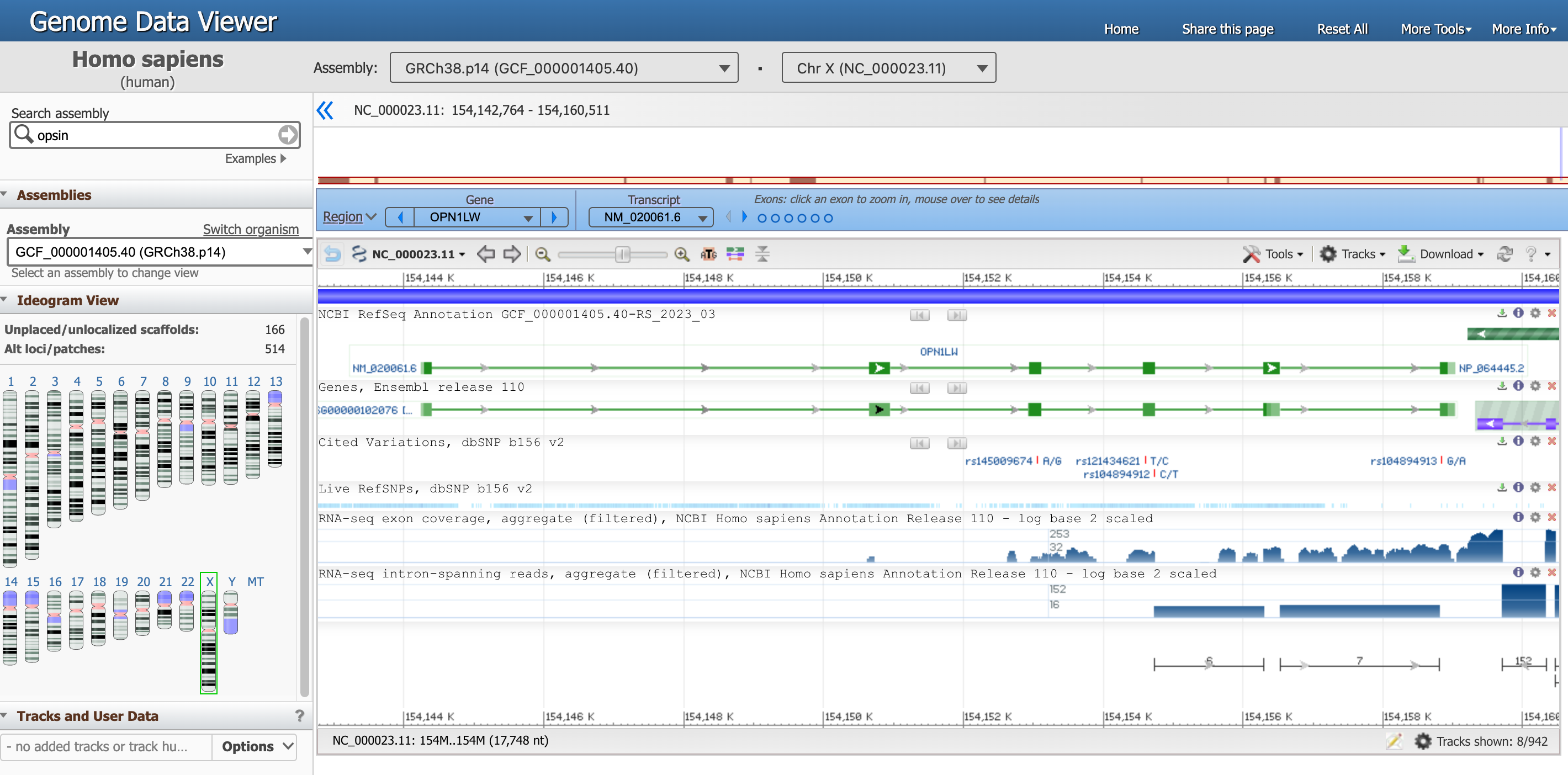
Debería haber aterrizado en esta página, que es la vista del genoma del gen OPN1LW.
 Open image in new tab
Open image in new tabHay mucha información en esta página, centrémonos en una sección cada vez.
- El Visor de Datos del Genoma, en la parte superior, nos dice que estamos viendo los datos del organismo
Homo sapiens, ensamblajeGRCh38.p14y en particular enChr X(Cromosoma X). Cada una de estas informaciones tiene un ID único. - Todo el cromosoma está representado directamente debajo, y las posiciones a lo largo de los brazos corto (
p) y largo (q) están resaltadas. -
A continuación, un recuadro azul resalta que ahora nos centramos en la Región correspondiente al Gen
OPN1LW.Hay múltiples formas de interactuar con el visor de abajo. Pruebe, por ejemplo, a pasar el ratón por encima de los puntos que representan exones en el recuadro azul.
-
En el gráfico siguiente, la requencia génica es una línea verde con los exones (fragmentos codificantes de proteínas) representados por rectángulos verdes.
Pase el ratón sobre la línea verde correspondiente a
NM_020061.6(nuestro gen de interés) para obtener información más detallada.Preguntas- ¿Cuál es la ubicación del segmento OPN1LW?
- ¿Cuál es la longitud del segmento OPN1LW?
- ¿Qué son los intrones y los exones?
- ¿Cuántos exones e intrones hay en el gen OPN1LW?
- ¿Cuál es la longitud total de la región codificante?
- ¿Cuál es la distribución entre regiones codificantes y no codificantes? ¿Qué significa eso en el término de biología?
- ¿Cuál es la longitud de la proteína en número de aminoácidos?
- De 154.144.243 a 154.159.032
- 1.4790 nucleótidos, encontrados en Span on 14790 nt, nucleotides)
- Los genes eucarióticos suelen estar interrumpidos por regiones no codificantes denominadas secuencias intermedias o intrones. Las regiones codificantes se denominan exones.
- En este diagrama se puede ver que el gen OPN1LW consta de 6 exones y 5 intrones, y que los intrones son mucho más grandes que los exones.
- La longitud de la CDS es de 1.095 nucleótidos.
- De los 14790 nt del gen, sólo 1095 nt codifican proteínas, lo que significa que menos del 8% de los pares de bases contienen el código. Cuando este gen se expresa en las células de la retina humana, se sintetiza una copia de ARN de todo el gen. A continuación, se recortan las regiones de intrones y se unen las regiones de exones para producir el ARNm maduro (un proceso denominado splicing), que será traducido por los ribosomas al fabricar la proteína opsina roja. En este caso, se desecha el 92% del transcrito inicial de ARN, dejando el código proteico puro.
- La longitud de la proteína resultante es de 364 aa, aminoácidos.
Pero, ¿cuál es la secuencia de este gen? Hay múltiples formas de recuperar esta información, vamos a repasar la que creemos que es una de las más intituitivas.
Práctica: Buscador del genoma abierto para el gen OPN1LW
- Haga clic en el icono tool Herramientas en la parte superior derecha del cuadro que muestra el gen
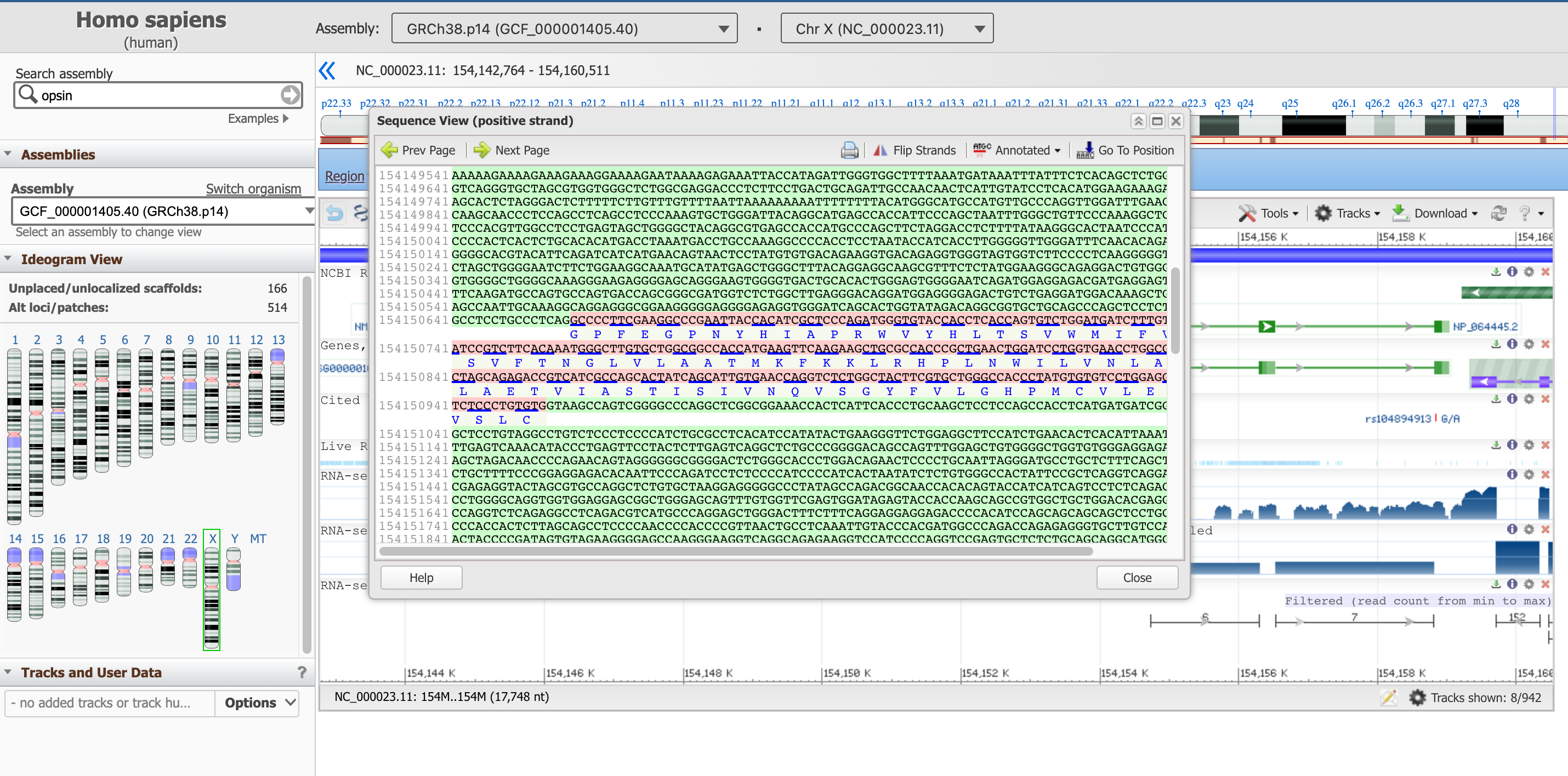
- Haga clic en Vista de secuencias de texto
Este panel informa de la secuencia de ADN de los intrones (en verde), así como de la de los exones (en rosa, incluyendo la secuencia de proteína traducida más abajo).
 Open image in new tab
Open image in new tabEste cuadro de secuencia no muestra el gen completo en este momento, sino una subsecuencia del mismo. Puede moverse aguas arriba y aguas abajo del código genético con las flechas Página anterior y Página siguiente, o empezar desde una posición específica con el botón Ir a la posición. Sugerimos empezar con el inicio de la parte codificante del gen, que como aprendimos antes está en la posición 154,144,243.
Práctica: Ir a una posición específica en la Vista de Secuencia
- Haga clic en Ir a la posición
Escriba en
154144243Tenemos que quitar las comas para validar el valor
La secuencia resaltada en púrpura señala aquí una región reguladora.
Preguntas
- ¿Cuál es el primer aminoácido del producto proteico resultante?
- ¿Cuál es la última?
- ¿Puede anotar los tres primeros y los tres últimos AA de esta proteína?
- La proteína correspondiente empieza por Metionina, M (todas lo hacen).
- El último AA del último exón (que se encuentra en la 2ª página) es Alanina (A). Después viene el codón de parada TGA, que no se traduce en un AA.
- Los tres primeros AA son: M,A,Q; los tres últimos: S,P,A.
Ahora podemos cerrar la Vista Secuencia.
Desde este recurso, también podemos obtener archivos, en diferente formato, que describen el gen. Están disponibles en la sección Download.
- Descargar FASTA nos permitirá descargar el formato de archivo más sencillo para representar la secuencia de nucleótidos de todo el rango visible del genoma (más largo que el gen solamente).
- Download GenBank flat file nos permitirá acceder a la anotación disponible en esta página (y más allá) en un formato de texto plano.
- Download Track Data nos permite inpectar dos de los formatos de archivo que presentamos en las diapositivas: los formatos GFF (GFF3) y BED. Si se cambian las pistas, cada una puede o no estar disponible.
Encontrar más información sobre nuestro gen
Veamos ahora la información que tenemos (en la literatura) sobre nuestro gen, utilizando los recursos del NCBI
Práctica: Ir a una posición específica en la Vista de Secuencia
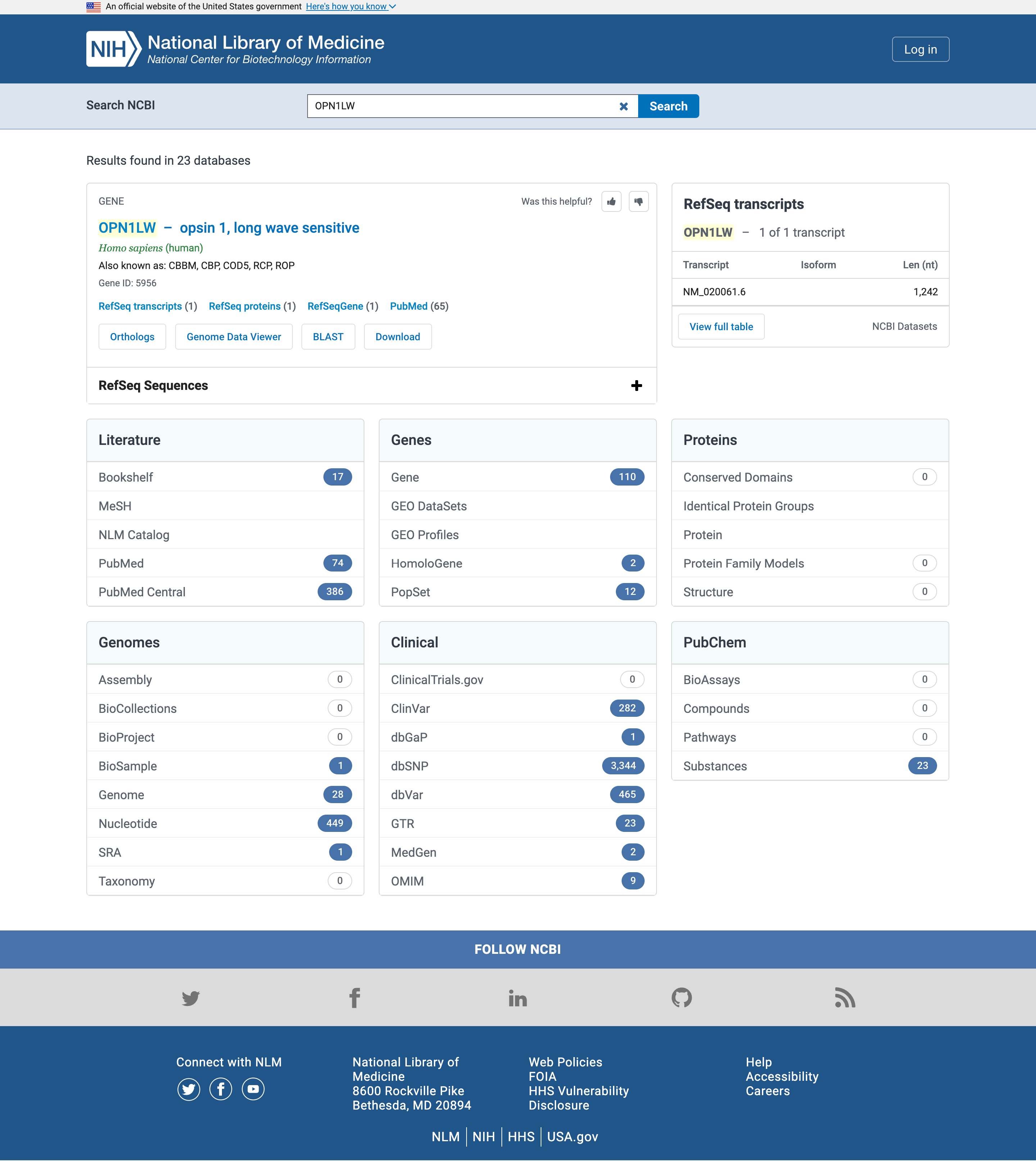
- Abra la búsqueda NCBI en www.ncbi.nlm.nih.gov/search
- Escriba
OPN1LWen la casilla de búsqueda *Search NCBI
 Open image in new tab
Open image in new tab.
Literatura
Empecemos con la literatura y en particular con los resultados de PubMed o *PubMed Central
PubMed es una base de datos de literatura biomédica que contiene los resúmenes de las publicaciones de la base de datos.
PubMed Central es un repositorio de texto completo, que contiene el texto completo de las publicaciones de la base de datos.
Aunque el número exacto de aciertos puede variar en el tiempo con respecto a la captura de pantalla anterior, cualquier nombre de gen debería tener más aciertos en PubMed Central (búsqueda en los textos completos de las publicaciones) que en PubMed (búsqueda sólo en los resúmenes).
Práctica: Abrir PubMed
- Haga clic en PubMed en la casilla *Literatura
Ha introducido en PubMed, una base de datos gratuita de literatura científica, los resultados de una búsqueda completa de artículos directamente asociados a este locus génico.
Haciendo clic en el título de cada artículo, podrá ver resúmenes del mismo. Si se encuentra en un campus universitario donde hay acceso en línea a revistas específicas, también podrá ver enlaces a artículos completos. PubMed es su punto de entrada a una amplia variedad de literatura científica en ciencias de la vida. En la parte izquierda de cualquier página de PubMed encontrará enlaces a una descripción de la base de datos, ayuda y tutoriales sobre búsquedas.
Preguntas
- ¿Puede adivinar qué tipo de enfermedades están asociadas a este gen?
- Responderemos a esta pregunta más adelante
Práctica: Volver a la página de búsqueda del NCBI
- Volver a la página de búsqueda del NCBI
Clínica
Centrémonos ahora en el cuadro Clinical, y especialmente en OMIM. OMIM, el Online Mendeliam Inheritance in Man (¡y woman!), es un catálogo de genes humanos y trastornos genéticos.
Práctica: Abrir OMIM
- Haga clic en OMIM en la casilla *Clinical
Cada entrada OMIM es un trastorno genético (aquí principalmente tipos de daltonismo) asociado con mutaciones en este gen.
Práctica: Lea tanto como le dicte su interés
- Siga los enlaces para obtener más información sobre cada entrada
Comentario: Lea tanto como le dicte su interésPara obtener más información sobre OMIM, haga clic en el logotipo de OMIM en la parte superior de la página. A través de OMIM, se dispone de abundante información sobre innumerables genes del genoma humano, y toda la información está respaldada por referencias a los artículos de investigación más recientes.
¿Cómo afectan las variaciones en el gen al producto proteico y a sus funciones? Volvamos a la página de los NIH e investiguemos el acceso a la lista de Polimorfismos de Nucleótido Único (SNPs) que fueron detectados por estudios genéticos en el gen.
Práctica: Abrir dbSNP
- Volver a la página de búsqueda del NCBI
- Haga clic en dbSNP en la casilla *Clinical
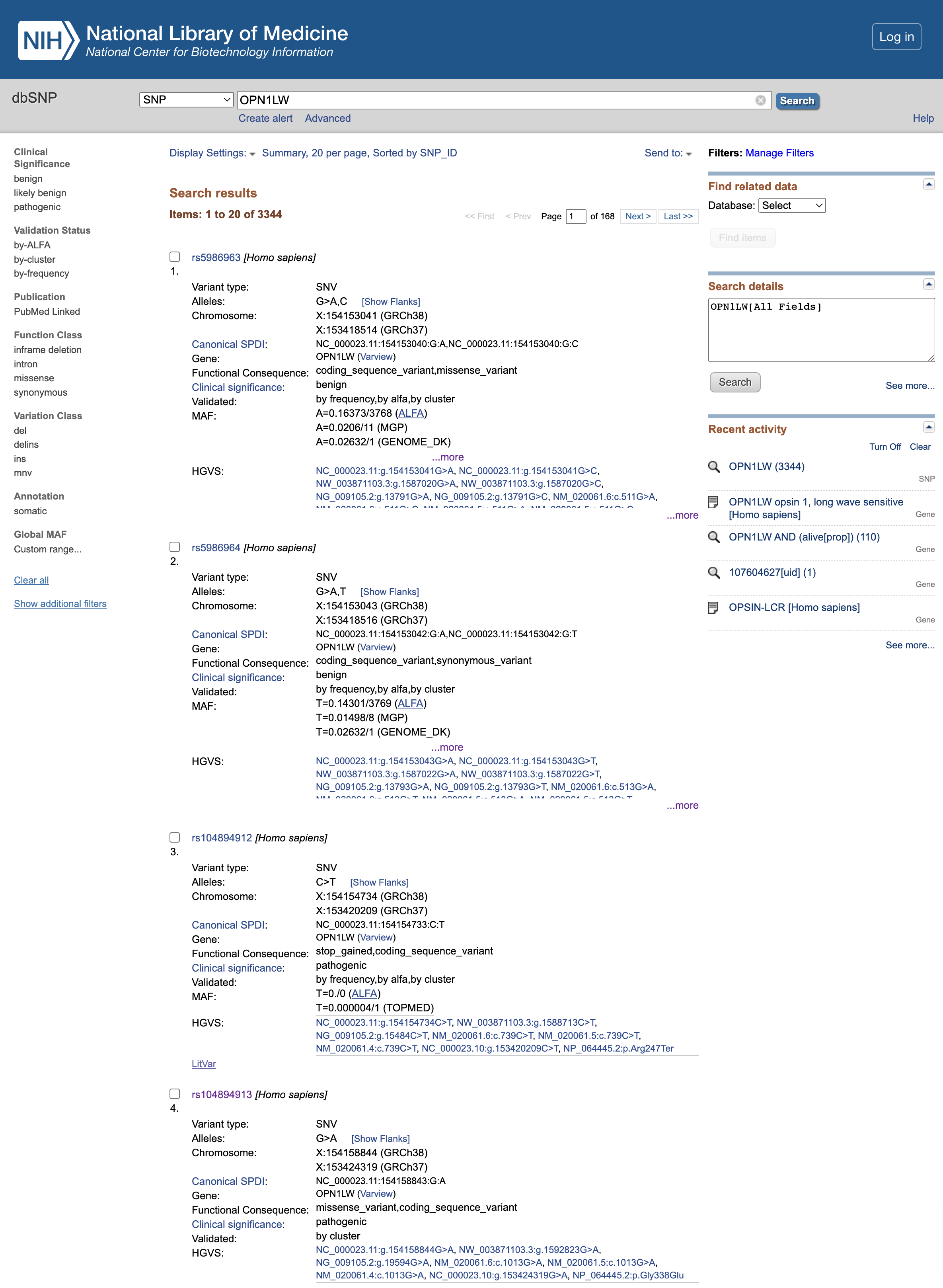 Open image in new tab
Open image in new tabPreguntas
- ¿Cuál es el significado clínico de las rs5986963 y rs5986964 (las 2 primeras variantes listadas en el momento de creación de este tutorial)?
- ¿Cuál es la consecuencia funcional de rs104894912?
- ¿Cuál es la consecuencia funcional de rs104894913?
- La significación clínica es
benignpor lo que parece que no tienen efecto sobre el producto proteico final- la mutación rs104894912 conduce a una variante
stop_gained, que trunca la proteína resultante demasiado pronto y es por tantopathogenic- la mutación rs104894913 conduce a un
missense_variant, tambiénpathogenic.
Investiguemos más sobre la variante rs104894913
Práctica: Aprenda más sobre una variante dbSNP
- Haga clic en
rs104894913para abrir su página dedicadaHaga clic en Clinical Significance (Importancia clínica)
Preguntas¿Qué tipo de afección se asocia con la variante rs104894913?
El nombre de la enfermedad asociada es “defecto de Protan”. Una rápida búsqueda en Internet con su buscador le aclarará que se trata de un tipo de daltonismo.
Haga clic en Detalles de la variante
Preguntas
- ¿Qué sustitución está asociada a esta variante?
- ¿Cuál es el impacto de esta subtitución en términos de codón y aminoácido?
- ¿En qué posición de la proteína se encuentra esta sustitución?
- La sustitución
NC_000023.10:g.153424319G>Acorresponde al cambio de una Guanina (G) a una Adenina (A)- Esta sustitución cambia el codón
GGG, una Glicina, porGAG, un Glutatiónp.Gly338Glusignifica que la sustitución se encuentra en la posición 338 de la proteína.
¿Qué significa esta sustitución para la proteína? Echemos un vistazo más profundo a esta proteína.
Proteína
Práctica: Proteína abierta
- Volver a la página de búsqueda del NCBI
- Haga clic en Proteína en la casilla *Proteínas
- Haga clic en
OPN1LW – opsin 1, long wave sensitiveen el cuadro superior
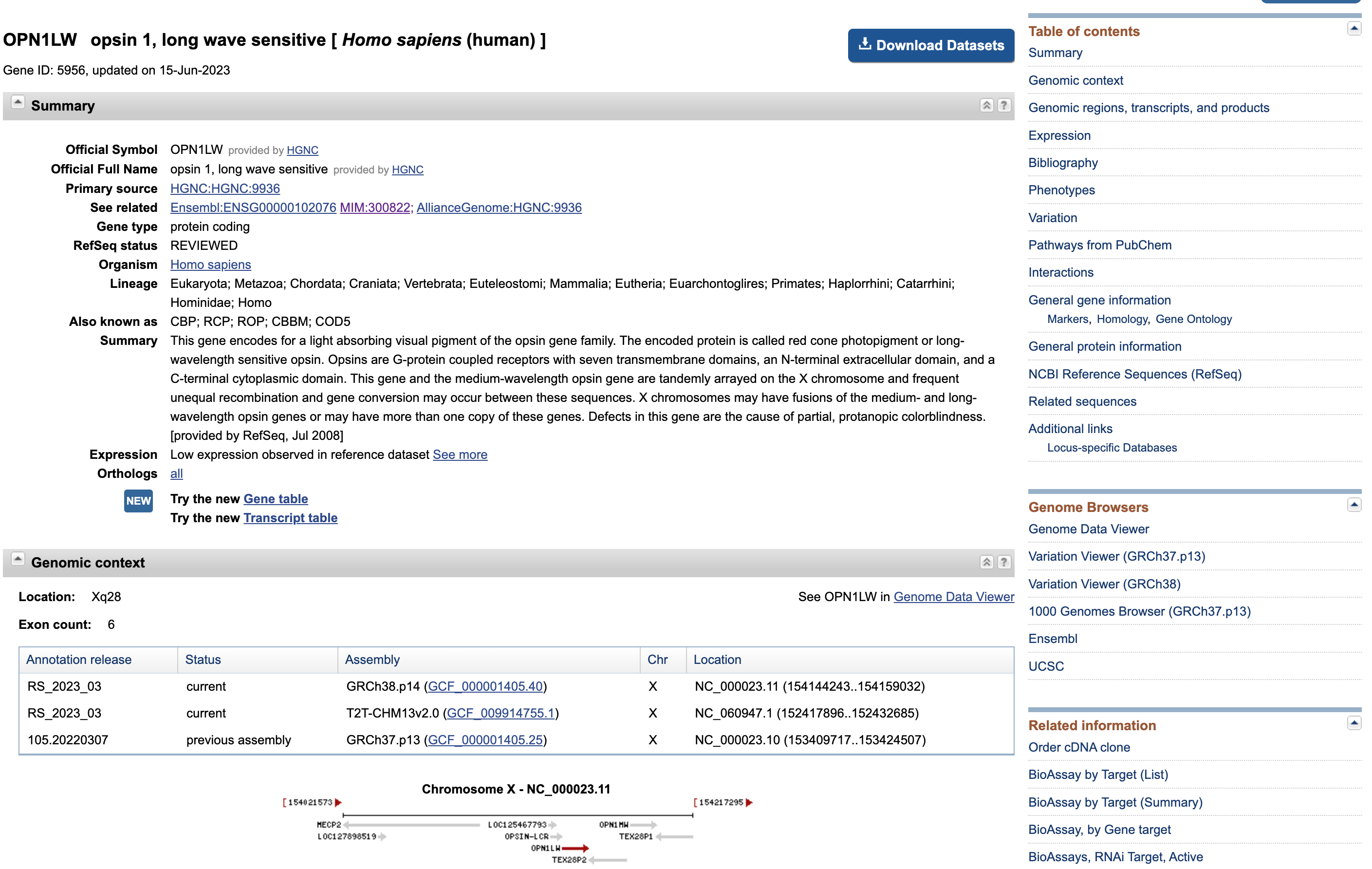 Open image in new tab
Open image in new tabEsta página presenta de nuevo algunos datos con los que estamos familiarizados (por ejemplo, la distribución de los exones a lo largo de la secuencia del gen).
Práctica: Descargar las secuencias de proteínas
- Haga clic en Descargar conjuntos de datos
- Seleccionar
Gene Sequences (FASTA)Transcript sequences (FASTA)Protein sequences (FASTA)- Haga clic en el botón *Descargar
- Abra el archivo ZIP descargado
Preguntas
- ¿Qué contiene la carpeta?
- ¿Cree que han aplicado buenas prácticas de datos?
- La carpeta incluye
- una carpeta
ncbi_datasetscon diferentes subcarpetas en ella leadig algunos archivos de datos (múltiples formatos),- un
README.md(un archivo Markdown), que está diseñado para “viajar” junto con los datos y explicar cómo se recuperaron los datos, cuál es la estructura de la subcarpeta que contiene los datos, y dónde encontrar documentación extensa.- Sin duda, es una buena práctica de gestión de datos guiar a los usuarios (no sólo a sus colaboradores, sino también a usted mismo en un futuro no muy lejano, cuando olvide de dónde procede ese archivo de su carpeta Descargas) hasta la fuente de datos y la estructura de datos.
Búsqueda por secuencia
¿Qué podríamos hacer con estas secuencias que acabamos de descargar? Supongamos que acabamos de secuenciar los transcritos que hemos aislado mediante un experimento, de modo que conocemos la secuencia de nuestra entidad de interés, pero no sabemos cuál es. Lo que tenemos que hacer en este caso es buscar en toda la base de datos de secuencias conocidas por la ciencia y emparejar nuestra entidad desconocida con una entrada que tenga alguna anotación. Hagámoslo.
Práctica: Busca la secuencia de proteína contra todas las secuencias de proteína
- Abra (con el editor de texto más sencillo que tenga instalado) el archivo
protein.faaque acaba de descargar.- Copie su contenido
- BLAST abierto blast.ncbi.nlm.nih.gov
Haga clic en
Protein BLAST, protein > proteinEn efecto, utilizaremos una secuencia de proteínas para buscar en una base de datos de proteínas
- Pegue la secuencia de la proteína en el cuadro de texto grande
- Compruebe el resto de parámetros
- Haga clic en el botón azul
BLAST
Esta fase llevará algún tiempo, después de todo hay algún servidor en alguna parte que está comparando la totalidad de las secuencias conocidas con su objetivo. Cuando la búsqueda se haya completado, el resultado debe ser similar a la de abajo:
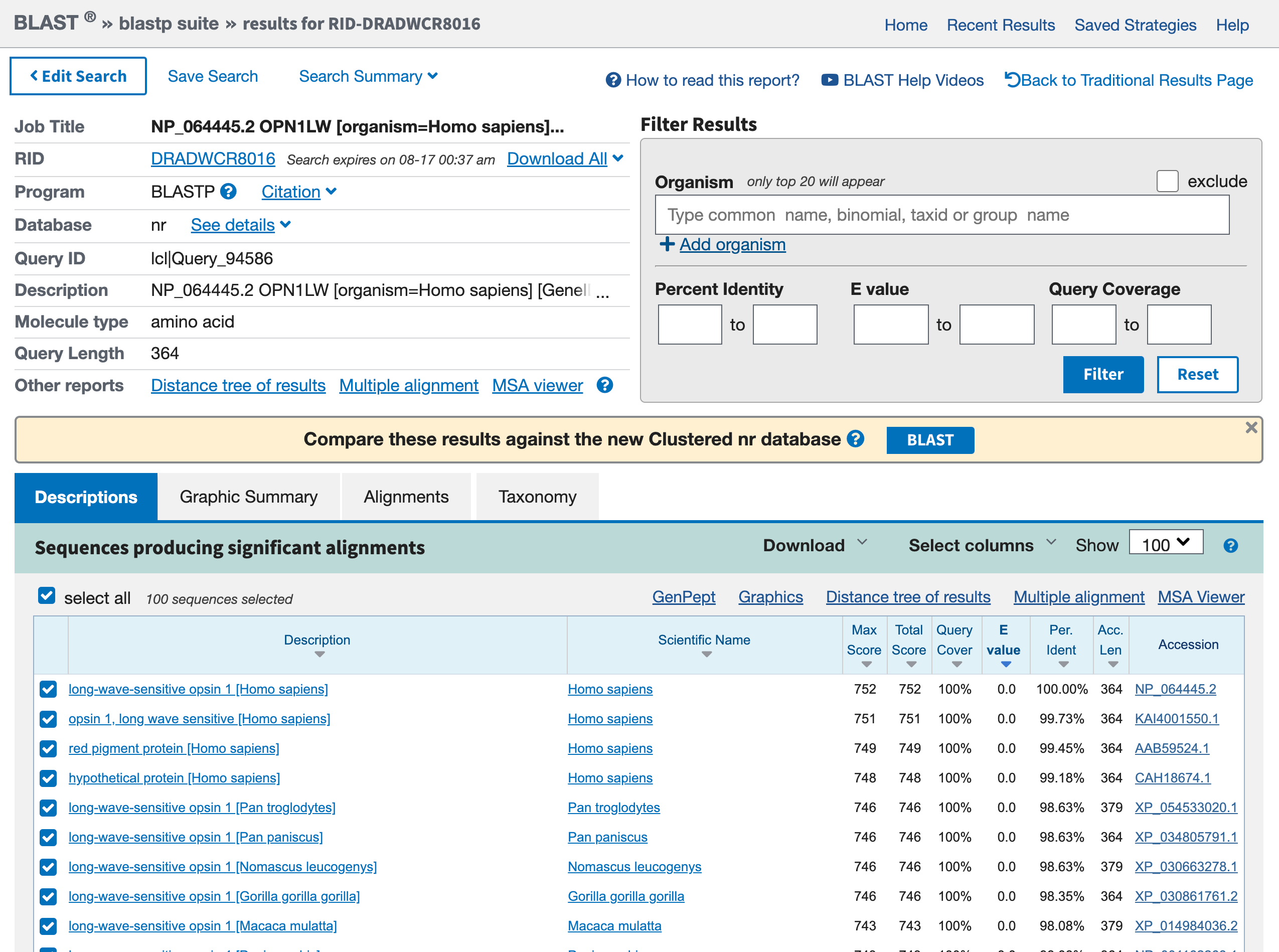 Open image in new tab
Open image in new tabPráctica: Resumen gráfico de las secuencias de proteínas
- Haga clic en la pestaña Resumen gráfico
Accedemos a un cuadro que contiene muchas líneas de colores. Cada línea representa un acierto de su búsqueda blast. Si hace clic en una línea roja, el recuadro estrecho que aparece justo encima ofrece una breve descripción del resultado.
Práctica: Descripciones de las secuencias de proteínas
- Haga clic en la pestaña Descripciones
Preguntas
- ¿Cuál es el primer resultado? ¿Se espera?
- ¿Cuáles son los otros resultados? ¿Para qué organismos?
- El primer acierto es nuestra opsina roja. Eso es alentador, porque la mejor coincidencia debe ser a la secuencia de consulta en sí, y usted tiene esta secuencia de esa entrada de genes.
- Otros hits son otras opsinas. Incluyen entradas de otros primates (por ejemplo,
Pan troglogytes).
Los resultados son para nuestra opsina roja en humanos pero también para otras opsinas en otros primates. Podríamos querer eso, por ejemplo si quisiéramos utilizar estos datos para construir un árbol filogenético. Si en cambio estamos bastante seguros de que nuestra secuencia de interés es humana, también podríamos haber filtrado la búsqueda sólo en secuencias humanas.
Práctica: Filtrar una búsqueda BLAST
- Haga clic en Editar búsqueda
- Escriba
Homo sapiensen el campo Organism- Haga clic en el botón azul
BLAST
Con esta nueva búsqueda, encontramos las otras opsinas (verde, azul, pigmento de células bastón) en la lista. Los otros resultados tienen un número menor de residuos coincidentes. Si hace clic en cualquiera de las líneas de color en el Resumen Gráfico, abrirá más información sobre ese resultado, y podrá ver cuánta similitud tiene cada uno con la opsina roja, nuestra secuencia de consulta original. A medida que se desciende en la lista, cada secuencia sucesiva tiene menos en común con la opsina roja. Cada secuencia se muestra en comparación con la opsina roja en lo que se denomina un alineamiento de secuencias por pares. Más adelante, realizará alineaciones de secuencias múltiples a partir de las cuales podrá discernir las relaciones entre los genes.
Las visualizaciones contienen dos medidas destacadas de la importancia del acierto:
la puntuación BLAST - lableled Score (bits)
La puntuación BLAST indica la calidad del mejor alineamiento entre la secuencia buscada y la secuencia encontrada (hit). Cuanto mayor sea la puntuación, mejor será el alineamiento. Las puntuaciones se ven reducidas por los desajustes y las lagunas en el mejor alineamiento. El cálculo de la puntuación es complejo e implica una matriz de sustitución, que es una tabla que asigna una puntuación a cada par de residuos alineados. La matriz más utilizada para la alineación de proteínas se conoce como BLOSUM62.
el Valor de Expectativa (etiquetado Expect o E)
El valor de la expectativa E de un acierto indica si el acierto es probablemente el resultado de la semejanza casual entre el acierto y la consulta, o de la ascendencia común del acierto y la consulta. ()
Comentario: Filtrar una Búsqueda BLASTSi E es menor que \(10\mathrm{e}{-100}\), a veces se da como 0.0.
El valor de expectativa es el número de aciertos que esperarías que se produjeran por pura casualidad si buscaras tu secuencia en un genoma aleatorio del tamaño del genoma humano.
\(E = 25\) significa que podría esperar encontrar 25 coincidencias en un genoma de este tamaño, puramente por azar. Por lo tanto, una coincidencia con \(E = 25\) es probablemente una coincidencia casual, y no implica que la secuencia encontrada comparta ascendencia común con la secuencia buscada.
Los valores de expectativa de alrededor de 0,1 pueden o no ser biológicamente significativos (se necesitarían otras pruebas para decidirlo).
Pero valores muy pequeños de E significan que la coincidencia es biológicamente significativa. La correspondencia entre su secuencia de búsqueda y esta coincidencia debe surgir de la ascendencia común de las secuencias, porque las probabilidades son simplemente demasiado bajas de que la coincidencia pueda surgir por casualidad. Por ejemplo, \(E = 10\mathrm{e}{-18}\) para una coincidencia en el genoma humano significa que sólo se esperaría una coincidencia casual en un billón de billones de genomas diferentes del mismo tamaño que el genoma humano.
La razón por la que creemos que todos procedemos de antepasados comunes es que la similitud masiva de secuencias en todos los organismos es sencillamente demasiado improbable para ser un hecho fortuito. Cualquier familia de secuencias similares en muchos organismos debe haber evolucionado a partir de una secuencia común en un antepasado remoto.
Práctica: Descargando
- Haga clic en la pestaña *Descripciones
- Haga clic en cualquier coincidencia de secuencia
- Haga clic en Descargar
- Select
FASTA (aligned sequences)
Descargará un nuevo tipo de archivo, ligeramente diferente: un FASTA alineado. Si lo desea, explórelo antes de la siguiente sección.
Mientras que en las secciones anteriores de este tutorial hemos utilizado ampliamente las interfaces web de las herramientas (visores genómicos, exploración rápida de la literatura, lectura de anotaciones, etc.), esta búsqueda BLAST es un ejemplo de un paso que podría automatizar completamente con Galaxy.
Práctica: Búsqueda de similitud con BLAST en Galaxia
Crear un nuevo historial para este análisis
Haz click sobre el icono new-history en la parte superior del panel de historiales.
Cambiar el nombre del historial
- Haz clic sobre Unnamed history (o el nombre que tenga el historial sobre el que estás trabajando) (Haz clic para cambiar el nombre del historial) en la parte superior de tu panel de historial
- Escribe el nombre nuevo
- Pulsa Enter
Importar la secuencia de proteínas a través de enlace desde Zenodo o bibliotecas de datos compartidos Galaxy:
https://zenodo.org/record/8304465/files/protein.faa
- Copia los enlaces
Abre el manejador de carga de datos de Galaxy (galaxy-upload (Upload) en la parte superior derecha del panel de herramientas)
- Selecciona ‘Pegar/Traer datos’ Paste/Fetch Data
Copia los enlaces en el campo de textos
Presiona ‘Iniciar’ Start
Close Cierra la ventana.
- Galaxy utiliza los URLs como nombres de forma predeterminada , así que los tendrás que cambiar a algunos que sean más útiles o informativos.
Como alternativa a cargar los datos desde una URL o desde su ordenador, los archivos también pueden estar disponibles desde una biblioteca de datos compartidos:
- Entra en Libraries (panel izquierdo)
- Navega a la carpeta correcta indicada por su instructor. - En la mayoría de los tutoriales de Galaxias los datos serán proporcionados en una carpeta llamada GTN - Material –> Topic name -> Tutorial name.
- Seleccione los archivos deseados
- Haz clic en Add to History galaxy-dropdown cerca de la parte superior y selecciona as Datasets en el menú desplegable
- En la ventana emergente, elige
- “Seleccionar historial “: el historial al que desea importar los datos (o crear uno nuevo)
- Haga clic en Import
NCBI BLAST+ blastp ( Galaxy version 2.10.1+galaxy2) con los siguientes parámetros:
- “Protein query sequence(s) “:
protein.faa- “Subject database/sequences “:
Locally installed BLAST database“Protein BLAST database “:
SwissProtPara buscar sólo secuencias anotadas en UniProt, necesitamos seleccionar la última versión de
SwissProt- “Set expectation value cutoff “:
0.001- “Output format “:
Tabular (extended 25 columns)

Preguntas¿Cree que estamos viendo exactamente los mismos resultados que nuestra búsqueda original de
opsinen www.ncbi.nlm.nih.gov/genome/gdv? ¿Por qué?Los resultados pueden ser similares, pero sin duda hay algunas diferencias. De hecho, no sólo una búsqueda de texto es diferente a una búsqueda de secuencias en términos de método, sino que además en esta segunda ronda partimos de la secuencia de una opsina específica, es decir, de una rama de todo el árbol genealógico de proteínas. Algunos de los miembros de la familia son más similares entre sí, por lo que este tipo de búsqueda examina toda la familia desde una perspectiva bastante sesgada.
Más información sobre nuestra proteína
Hasta ahora, hemos explorado esta información sobre las opsinas:
- cómo saber qué proteínas de un determinado tipo existen en un genoma,
- cómo saber dónde se encuentran a lo largo del genoma,
- cómo obtener más información sobre un gen de interés,
- cómo descargar sus secuencias en diferentes formatos,
- cómo utilizar estos archivos para realizar una búsqueda por similitud.
Puede que ahora sienta curiosidad por saber más sobre las proteínas que codifican. Ya hemos recopilado alguna información (por ejemplo, enfermedades asociadas), pero en los próximos pasos la cruzaremos con datos sobre la estructura de la proteína, localización, interactores, funciones, etc.
El portal a visitar para obtener toda la información sobre una proteína es UniProt. Podemos buscar en él utilizando una búsqueda de texto, o el nombre del gen o de la proteína. Vamos a utilizar nuestra palabra clave habitual OPN1LW.
Práctica: Búsqueda en UniProt
- Abrir UniProt
- Escriba
OPN1LWen la barra de búsqueda- Seleccione la vista de tarjeta
El primer resultado debe ser P04000 · OPSR_HUMAN. Antes de abrir la página, dos cosas a notar:
- El nombre de la proteína
OPSR_HUMANes diferente del nombre del gen, así como sus IDs son. - Esta entrada tiene una estrella dorada, lo que significa que fue anotada y curada manualmente.
Práctica: Abrir un resultado en UniProt
- Haga clic en
P04000 · OPSR_HUMAN
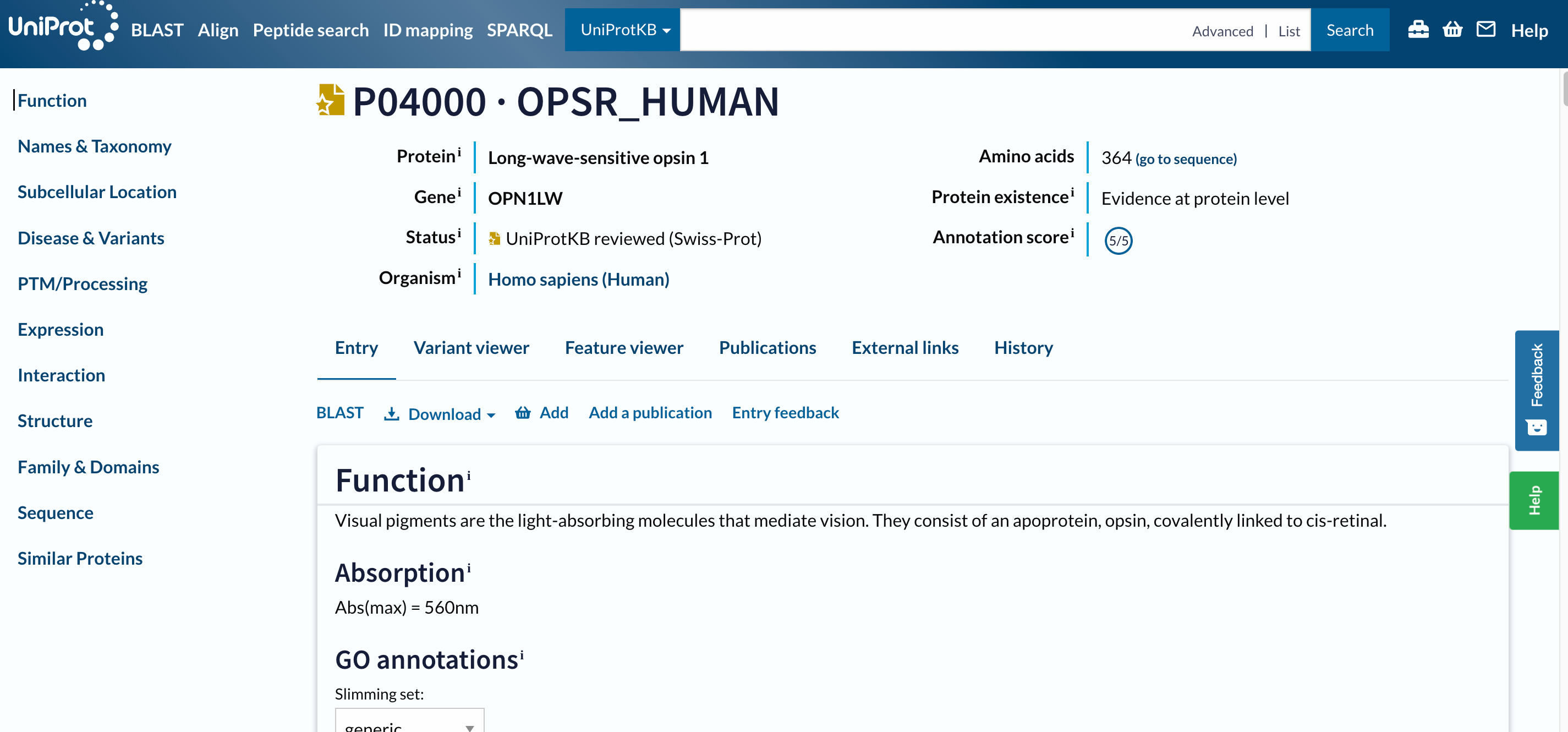 Open image in new tab
Open image in new tabEsta es una página larga con mucha información, hemos diseñado un tutorial entero para repasarla.
You've finished the tutorial
Puntos clave
Puedes buscar genes y proteínas usando texto específico en el genoma de NCBI.
Una vez encuentres un gen o proteína relevante, puedes obtener su secuencia y anotación en varios formatos desde NCBI.
También puedes conocer la localización cromosómica y la composición de exones‑intrones del gen de interés.
NCBI ofrece una herramienta BLAST para realizar búsquedas de similitud con secuencias.
Puedes explorar más recursos incluidos en este tutorial para aprender sobre condiciones asociadas al gen y sus variantes.
Puedes introducir un archivo FASTA con una secuencia de interés para búsquedas BLAST.
Preguntas frecuentes
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsReferencias
- Rangwala, S. H., A. Kuznetsov, V. Ananiev, A. Asztalos, E. Borodin et al., 2021 Accessing NCBI data using the NCBI sequence viewer and genome data viewer (GDV). Genome research 31: 159–169. 10.1101/gr.266932.120
Retroalimentación
¿Utilizaste este material como instructor? Cuéntanos tu experiencia.
¿Has usado este material como aprendiz o estudiante? Haz click en el formulario a continuación para dejarnos tu opinión

Cómo citar este tutorial
- Lisanna Paladin, Bérénice Batut, Teresa Müller, Aprendizaje sobre un gen a través de recursos y formatos biológicos (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/data-science/tutorials/online-resources-gene/tutorial_ES.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{data-science-online-resources-gene, author = "Lisanna Paladin and Bérénice Batut and Teresa Müller", title = "Aprendizaje sobre un gen a través de recursos y formatos biológicos (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/data-science/tutorials/online-resources-gene/tutorial_ES.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Referencias
These individuals or organisations provided funding support for the development of this resource
¡Felicitaciones! ¡Completaste con éxito este tutorial!You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/data-science/tutorials/online-resources-gene/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: ncbi_blast_plus owner: devteam revisions: 0e3cf9594bb7 tool_panel_section_label: NCBI Blast tool_shed_url: https://toolshed.g2.bx.psu.edu/